卷积神经网络是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
经典卷积神经网络卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。
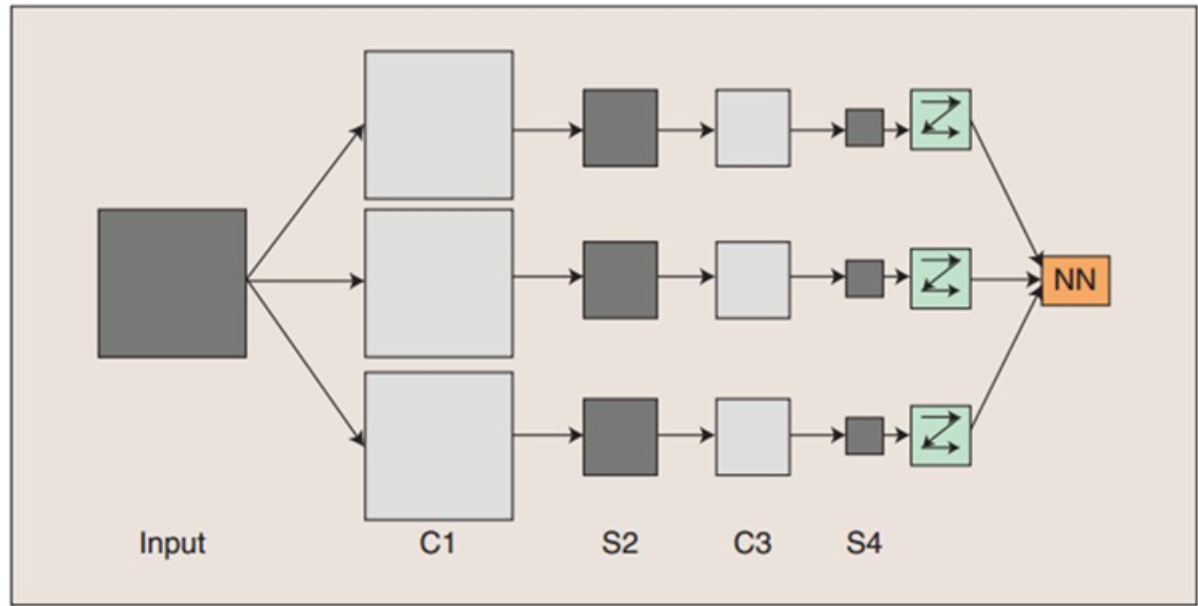
图:卷积神经网络的概念示范:输入图像通过和三个可训练的滤波器和可加偏置进行卷积,滤波过程如图一,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
层级介绍- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
- 损失层
数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
卷积计算层
这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在实际训练过程中,卷积核的值是在学习过程中学到的。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。
参数减少与权值共享,降低参数量级
如果我们使用传统神经网络方式,对一张图片进行分类,那么,我们把图片的每个像素都连接到隐藏层节点上,那么对于一张1000x1000像素的图片,如果我们有1M隐藏层单元,那么一共有10^12个参数,这显然是不能接受的。(如下图所示)
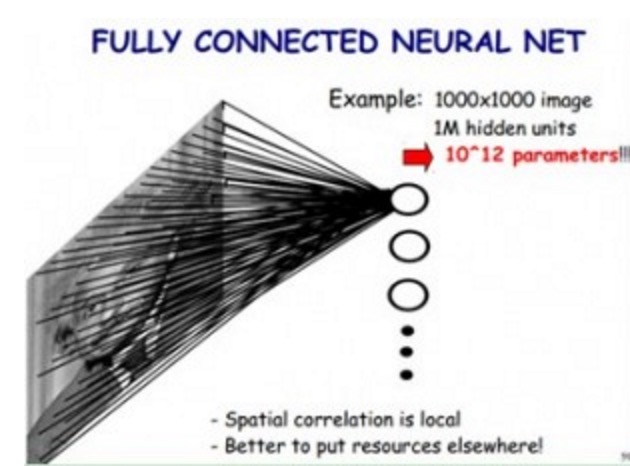
但是我们在CNN里,可以大大减少参数个数,我们基于以下两个假设:
1)最底层特征都是局部性的,也就是说,我们用10x10这样大小的过滤器就能表示边缘等底层特征
2)图像上不同小片段,以及不同图像上的小片段的特征是类似的,也就是说,我们能用同样的一组分类器来描述各种各样不同的图像
激励层
把卷积层输出结果做非线性映射。
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱。
激励层的实践经验:
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先试RELU,因为快,但要小心点
③ 如果2失效,请用Leaky ReLU或者Maxout
④ 某些情况下tanh倒是有不错的结果,但是很少
池化层(Pooling)
池化听起来很高深,其实简单的说就是下采样。池化的过程如下图所示:
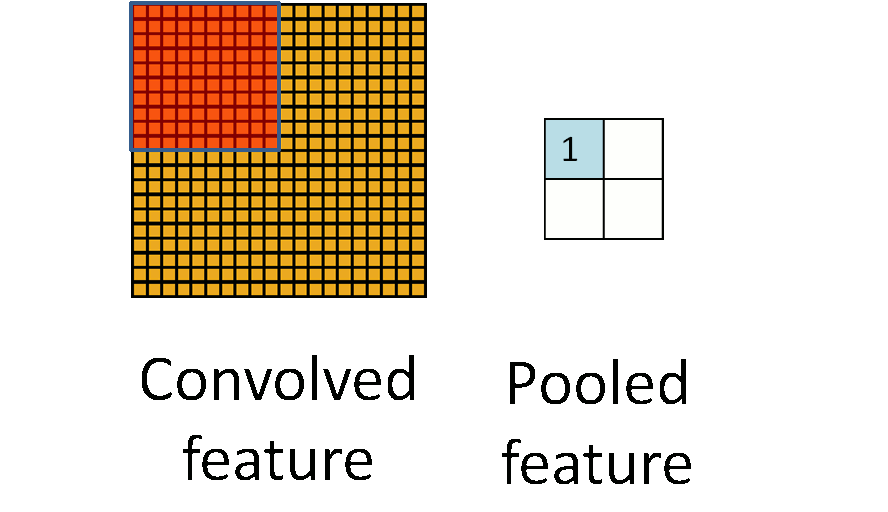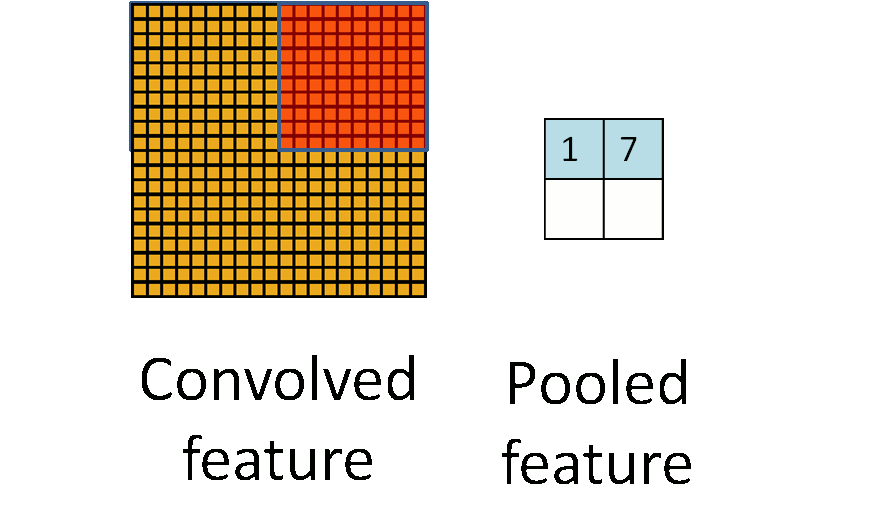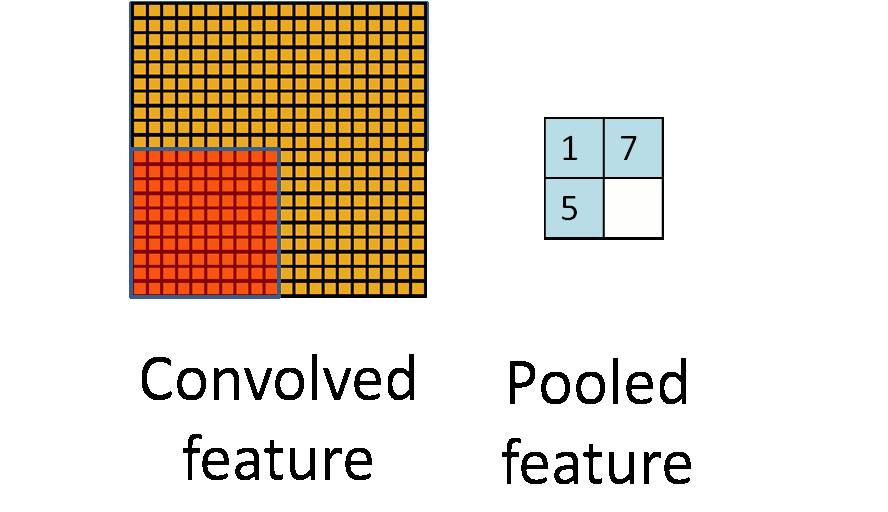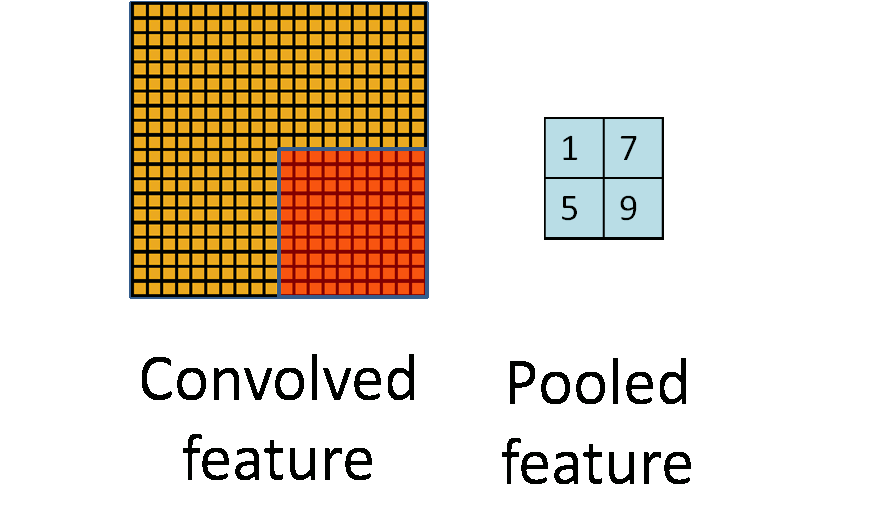
上图中,我们可以看到,原始图片是20x20的,我们对其进行下采样,采样窗口为10x10,最终将其下采样成为一个2x2大小的特征图。
之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
之所以能这么做,是因为即使减少了许多数据,特征的统计属性仍能够描述图像,而且由于降低了数据维度,有效地避免了过拟合。
在实际应用中,池化根据下采样的方法,分为最大值下采样(Max-Pooling)与平均值下采样(Mean-Pooling)。
这里就说一下Max pooling,其实思想非常简单。
对于每个2*2的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个2*2窗口中最大的数是6,那么输出矩阵的第一个元素就是6,如此类推。
全连接层
对池化层的输出进行处理,输出一个T*1的向量。这个向量也是损失层的输入
损失层
有几个重要的模型:softmax,softmax loss,cross entropy
输入是T*1的向量,输出也是T*1的向量(这个向量的每个值表示这个样本属于每个类的概率),只不过输出的向量的每个值的大小范围为0到1。
公式非常简单,前面说过softmax的输入是WX,假设模型的输入样本是I,讨论一个3分类问题(类别用1,2,3表示),样本I的真实类别是2,那么这个样本I经过网络所有层到达softmax层之前就得到了WX,也就是说WX是一个3*1的向量,那么上面公式中的aj就表示这个3*1的向量中的第j个值(最后会得到S1,S2,S3);而分母中的ak则表示3*1的向量中的3个值,所以会有个求和符号(这里求和是k从1到T,T和上面图中的T是对应相等的,也就是类别数的意思,j的范围也是1到T)。因为e^x恒大于0,所以分子永远是正数,分母又是多个正数的和,所以分母也肯定是正数,因此Sj是正数,而且范围是(0,1)。如果现在不是在训练模型,而是在测试模型,那么当一个样本经过softmax层并输出一个T*1的向量时,就会取这个向量中值最大的那个数的index作为这个样本的预测标签。
2、softmax loss

首先L是损失。Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
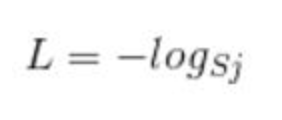
当然此时要限定j是指向当前样本的真实标签。
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。简单讲就是你预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
1. 同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
2. 找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层。
- ZF Net, 2013 ILSVRC比赛冠军
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
何谓fine-tuning?
fine-tuning就是使用已用于其他目标、预训练好模型的权重或者部分权重,作为初始值开始训练。
那为什么我们不用随机选取选几个数作为权重初始值?原因很简单,第一,自己从头训练卷积神经网络容易出现问题;第二,fine-tuning能很快收敛到一个较理想的状态,省时又省心。
那fine-tuning的具体做法是?
• 复用相同层的权重,新定义层取随机权重初始值
• 调大新定义层的的学习率,调小复用层学习率
Caffe
• 源于Berkeley的主流CV工具包,支持C++,python,matlab
• Model Zoo中有大量预训练好的模型供使用
Torch
• Facebook用的卷积神经网络工具包
• 通过时域卷积的本地接口,使用非常直观
• 定义新网络层简单
TensorFlow
• Google的深度学习框架
• TensorBoard可视化很方便
• 数据和模型并行化好,速度快
参考:
https://www.cnblogs.com/alexcai/p/5506806.html
https://blog.csdn.net/zouxy09/article/details/8781543
https://www.cnblogs.com/skyfsm/p/6790245.html
https://blog.csdn.net/u014380165/article/details/77284921