Tensorboard是TF自带的可视化工具。它可以让我们从各个角度观察与修改模型,比如观察模型在训练时的loss动态变化曲线而无需在迭代完毕后再画图、绘制神经网络的结构图、调节超参数等。下面以最简单的形式展示tensorboard的常用功能。
开启tensorboard打开命令行输入
tensorboard --logdir logs
然后回车。前两个参数固定,第三个参数表示tensorboard所要观察的文件夹位置。后面再使用TF将信息写入该文件夹中,tensorboard就可以从中读取数据用于可视化。输出如下:

进入得到的链接,就是tensorboard的界面了。这时你的logs文件夹应该还是空的,没有写入数据,所以tensorboard无法可视化。下面介绍如何向文件夹中写入数据。
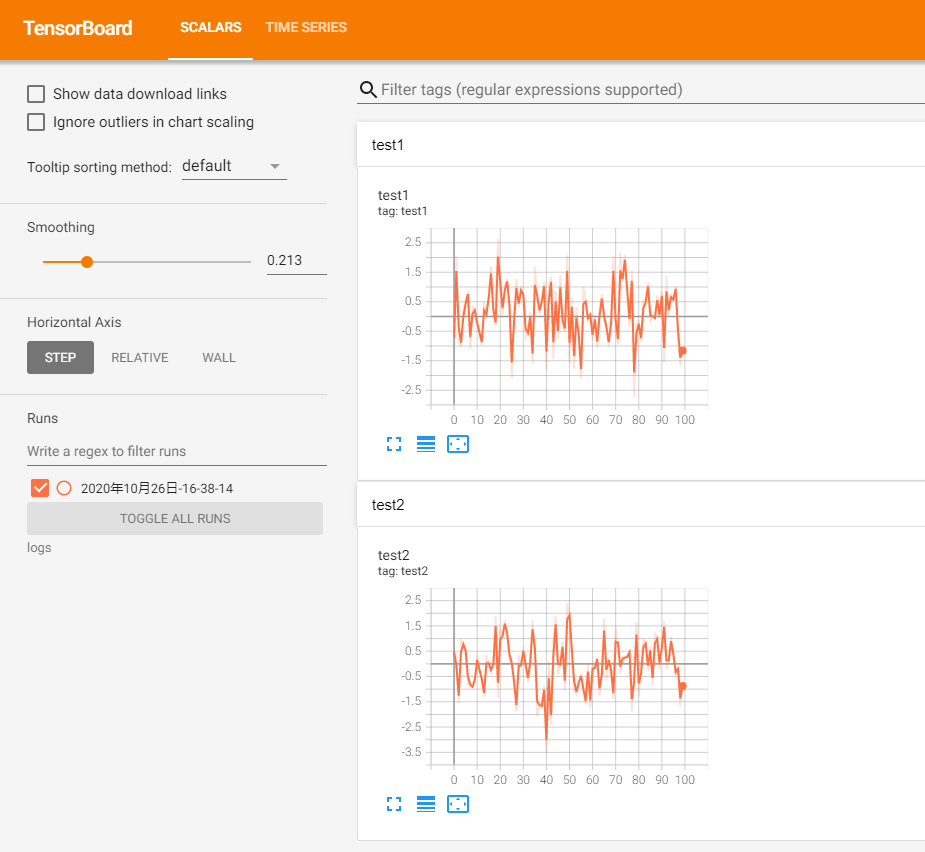
ScalarsScalars用来可视化时间步下的状态曲线,比如loss的变化曲线。下面是代码示例:
import numpy as np import tensorflow as tf from datetime import datetime current_time = datetime.now().strftime("%Y{y}%m{m}%d{d}-%H-%M-%S").format(y = '年',m = '月',d='日') log_path = 'logs/'+current_time#——————1—————— log_writer = tf.summary.create_file_writer(log_path)#——————2—————— for i in range(100): data1 = np.random.normal()#——————3—————— data2 = np.random.normal()#——————3—————— with log_writer.as_default():#——————4—————— tf.summary.scalar('test1', data1, i) #——————5—————— tf.summary.scalar('test2', data2, i) #——————5——————
#1/2:创建以时间命名的用于保存记录的文件,并获取用于往该文件中写入记录的对象实例。注意!文件要保存在logs文件夹中,tensorboard才能读取。
#3:定义每次迭代要记录的值。
#4/5:使用#2定义的对象将记录以scalar的方式写入,scalar实际上就是画折线图,其中三个参数分别代表是:记录名、这次迭代要保存的值、第几次迭代。可以看出,一个文件可以保存多条记录,而每条记录都含有多次迭代。
在tensorboard界面中,右上角点击刷新,或者在下拉选项中选择scalar,tensorboard就会显示输出的记录。界面中还能调节平滑度什么的,这里就不记录了。Tensorboard的一大好处在于它能在代码执行的时候同步可视化图像,上面的代码示例仅有100次迭代,不好体现,可以自己尝试一下。
可视化后的折线图界面如下:
可视化模型结构,但是显示出来的结构很乱,几乎没法看,暂时没弄懂看的是什么。这里先记录显示流程。代码示例如下:
import numpy as np from tensorflow.keras import Input,Model,layers,losses,callbacks logdir="logs/test" tensorboard_callback = callbacks.TensorBoard(log_dir=logdir)#——————1—————— class TestModel(Model):#——————2—————— def __init__(self): super().__init__() self.layer1 = layers.Dense(10) self.layer2 = layers.Dense(1) def call(self,inputs): x = self.layer1(inputs) x = self.layer2(x) return x model = TestModel()#——————3—————— model.compile(optimizer='rmsprop',loss='mse')#——————4—————— model.fit(np.ones([3,10]), np.ones([3,1]), callbacks=[tensorboard_callback]) #——————5——————
#1:定义保存模型结构的文件,获取一个回调函数对象,用于在fit的时候将模型计算图记录并保存。
#2:继承Model类自定义我们的模型,只要实现以上两个函数即可。
#3/4/5:实例化模型、编译,然后fit,让上面定义的回调函数过一遍我们的模型,这样一来它就能将结构记录下来了。
然后打开tensorboard网页,右上角下拉选中GRAPH,就能看到画出的图了。如下图(显示的玩意儿看不太懂):
另外,因为是在fit中保存的结构,所以它在保存的时候会多包一层train文件夹。
Hparams超参数优化。暂时用不到,以后再记录。