Mahout 是一套具有可扩充能力的机器学习类库。目前,最新版本为0.7,主要提供推荐引擎算法、分类算法和聚类算法。该类库既可以单机环境下使用,也可以在hadoop集群中使用。具体Mahout的介绍可以参考:
1、http://www.ibm.com/developerworks/cn/java/j-mahout/
实际应用中,可以将其相关包加入个人项目,使用已经封装好的jar包,即类库。作为研究,可以将Mahout最为一个单独的工程“检出”,在eclipse中单独处理,并对源码进行修改。基于应用和研究的不同,对mahout的处理就有所不同。
一、安装1、ubuntu linux 10.04
2、subclipse
eclipse中的svn插件,用于从SVN服务器中检出工程。具体参见:
1)http://xgdellis.iteye.com/blog/1450196
3、maven插件
用于检出mahout源码。具体参见:
1)http://blog.csdn.net/aidayei/article/details/6664386
2)http://blog.163.com/jiayouweijiewj@126/blog/static/1712321772011117111127400/
在2)中,最后运行了run as->maven bulid,文件之间就关联了起来,可以追溯类或方法,具体原因不太清楚。
二、简单案例在我的工程中,“usingMahout”工程用的是mahout的jar包,不是源码,参考的该博文:http://blog.csdn.net/zhzhl202/article/details/6316570,这种方法可以使用mahout,但不可以对其进行改进。
mahout-core都是从svn中检出的源码,执行了第一节第3步中相关的操作,maven build 之后,出现了一次死机的情况,之后便可以文件关联。
测试程序选的是http://blog.csdn.net/zhzhl202/article/details/6316570中提供的程序,经测试,在usingMahout和mahout-core中都能够得到正确的结果。
ps:在探索过程中,安装过maven,配置过相应的变量,也在检出的mahout整个工程中执行过一些命令,暂时没用到。对maven不熟,有待进一步学习。
三、集群中安装拷贝mahout的下载包至集群主节点(只需要在主节点中配置),或者通过Maven检出。之后配置环境变量,在命令行中输入一下命令:
export HADOOP_HOME=/home/hadoop
export HADOOP_HOME_CONF_DIR=/home/hadoop/conf检测是否安装成功:
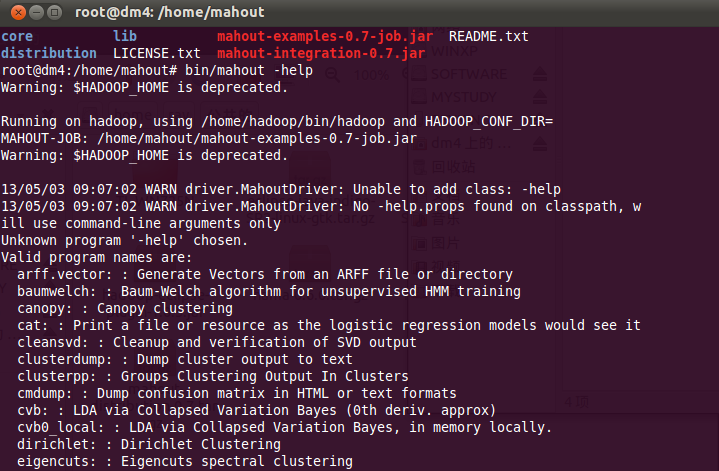
root@dm4:/home/mahout#mahout -help
若安装成功,会输出mahout已经实现的算法,如下图所示。
运行示例。mahout自带一些示例代码,执行下面的hadoop命令,可以运行Canopy聚类算法示例:
root@dm4:/home/hadoop#bin/hadoop jar /home/mahout/mahout-examples-0.7-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job (注意字母大小写,“Job”)
不太清楚 mahout-examples-0.7.jar和mahout-examples-0.7-job.jar的区别,做实验时可以多做些尝试。
root@dm4:/home/hadoop#bin/hadoop jar /home/mahout/mahout-examples-0.7.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job 在运行之前需要保证hadoop系统中存在/user/root/testdata目录存在,且该目录下包含数据,本次实验采用的是http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data,具体参考http://ices01.sinaapp.com/?p=90和http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data.html
使用mahout命令查看运行结果
root@dm4:/home/mahout# bin/mahout vectordump --seqfile /user/root/output/data/part-m-00000