博客中的文章均为meelo原创,请务必以链接形式注明本文地址

搜索引擎是一个十分神秘的事物,因为它铸造了google和百度两大传奇互联网公司。过去流传一种说法,世界上只有4个国家掌握了搜索引擎的核心技术,那就是美国、中国、俄罗斯和韩国,分别对应Google、百度、naver和yandex。曾经有国有背景的即刻搜索想承担起国家战略,国有企业在能源、基础设施领域雄踞一方,战无不胜,但即刻搜索最终却失败了。搜索引擎真的是那么遥不可及的技术吗?
其实,搜索引擎是诸多技术组成的复合体。囊括自然语言处理、并行计算、爬虫等领域。但其最基本的原理却并不复杂。北京大学在Coursera开设的程序设计与算法专项课程,从零基础开始教授C语言、算法、数据结构,当你过关闯将,完成6门课程之后,最后的毕业项目就是完成一个搜索引擎。毕业项目由7个部分组成,每个部分都有明确的目标说明,需要完成搜索引擎的一个部分。当你完成所有7个部分的时候,你就真正搭建出来一个搜索引擎啦。动手实践是最佳的学习方式,你可以在学习理论的同时,及时地检验学习的效果。这篇文章我就来介绍在毕业项目中我学到了什么,顺便揭秘所谓“搜索引擎的核心技术”。
一个网页搜索引擎主要有四个部分组成。分别是自动下载网页的爬虫、对网页建立索引、衡量网页的质量和评价网页和查询的相关性。首先我必须明确提出的是,毕业项目实现的是一个文本搜索引擎,和网页搜索引擎有一定差别。比如:文本搜索引擎无需通过爬虫遨游互联网下载网页,与之对应的是遍历硬盘上的文本文件;另一个差别是文本搜索引擎没法像网页那样使用PageRank算法衡量网页的质量,PageRank算法是Google的两位创始人共同发明的,其核心思想是利用连接不同网页的URL,如果有很多高质量的网页指向这一网页,那么说明这个网页也是一个高质量的网页,文本文件没有链接,因此不能应用PageRank算法。
即便文本搜索引擎和网页搜索引擎有一定差异,但目标仍然是一样的。给定一个关键词或者是一句话作为查询(query),找到包含这个关键词或者这句话的文档,同时要求与查询越相关的文档排名越靠前。
完成毕业项目的第一个难点就是理解文本搜索引擎的框架,这样在完成每一个部分的时候,才能清楚你在做什么。
除去自动下载网页的爬虫和评价网页和查询的相关性,文本搜索引擎的核心就只包含对文档建立索引和评价文档与查询相关性两个组件了。下面我将介绍这两个组件是如何在这7个部分中完成的。
对文档建立索引
在正式进入话题之前,需要消除一个误解。搜索引擎搜索网页并不是实时地检索整个互联网,现在完整请求一个网页就需要花费将近1秒,搜索引擎能够如此之快的返回结果,这是不现实的。取而代之的是,搜索引擎在数据库里建立了一个索引。
对文档建立的索引有两个。第一个索引是原封不动地把文档的内容存储到数据库里,就像“百度快照”一样,百度在它的服务器上,保存了一份网页的副本,如果网页无法打开,你仍然可以浏览这份副本。这对应于毕业项目的第2个部分,其实对于文本搜索引擎或者说在这个项目里,这个“快照”并没有起到什么作用。
不同文档的长度是不相同的,如何高效地存储是一个需要解决的问题。这在项目的要求中已经明确的给出了。分两个文件存储,第一个文件连续存储文档的内容,第二个文件存储每一个文档在第一个文件当中的起始位置。第二个文件的每一个记录就是定长的了,因此可以在常数时间内,获取文档的起始位置和结束位置。
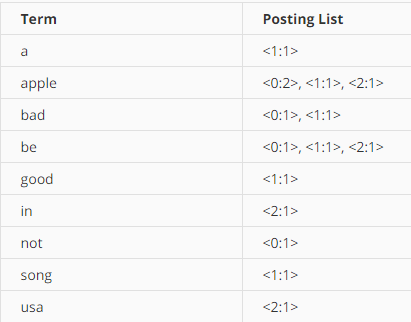
第二个索引是倒排索引(inverted index)。倒排索引是搜索引擎如此之快的一个核心原理。对于一篇文档,包含语义的基本元素是一个个的单词。处理文档的第一步就是将文档分割为一个个的单词,这是毕业项目的第1部分。在中文里,单词之间并没有明确的分隔符,分割单词需要涉及到自然语言处理。好在毕业项目所涉及的搜索引擎是一个英文的搜索引擎,英文单词之间有天然的空格分割,第1部分就是利用空格或者是标点符号作为分隔符,分割成单词,术语叫做Token。Token不仅仅是单词,还包括单词出现的位置,这有助于判断两个单词是否相邻,提升搜索结果的相关性,在毕业项目中虽然保存了单词出现的位置但在搜素的时候并没有使用这一信息。
倒排索引是一个表格,第一列是所有文档里出现的单词,第二列是由多个元组组成的列表,元组的第一项是文档编号,第二项是该文档中这个单词出现的次数,又叫做文档频率(text frequency)。有了倒排索引,在检索一个单词的时候,就无需遍历所有文档了,搜索倒排索引就能找到包含这个单词的文档。存储倒排索引就是毕业项目第3部分需要完成的内容,与存储原始文档面临的相同问题是,倒排索引也是不定长的,因此需要像存储原始文档那样,分两个表来存储。这就是建立索引的全部了。
评价文档与查询相关性
检索通常不是一个单词而是一个短语,短语中包含多个单词。比如我的检索词是“百度公司”,只要是介绍一个公司的文档就会包含“公司”这个单词,但是只有涉及“百度”的文档才会出现“百度”这个单词。这说明不同单词的重要性不同的,搜索引擎需要关注检索词中特殊的词语才能找到最相关的文档。系统性衡量单词重要性的指标是反转文档频率(inverse docuement frequency)。它通过公式log(1/df)计算得到,df表示文档频率(docuement frequency),是出现该单词文档的次数。与文档频率成反比意味着一个单词在不同文档中出现的次数越多,越不重要,像“这”、“我”这些词汇,几乎会出现在每一个文档里,可以说完全不重要。这些词称为停止词(stop words)。
文档与查询的相关性就可以用一篇文档检索词出现的次数乘以反转文档频率tf×idf表示(又记作tf-idf),如果一篇文档出现了多个检索词,那么就是所有这些检索词的tf-idf之和。计算tf-idf便是毕业项目第4部分需要完成的任务。
一个检索词在一篇文档出现的次数可以通过查询倒排索引得到,如果一篇文档出现了一个单词,那么倒排索引在那个单词的记录中就会包含这个记录。只有出现这一单词的文档才会出现在倒排索引对应单词的记录中,文档的范围就大大减少了。在毕业项目里,倒排索引保持字典序,在检索一个单词的时候就可以使用二分搜索,这就是毕业项目第5部分需要完成的任务。
正如之前所说的,检索词可以是一个短语,根据不同搜索引擎的设计,短语中的单词可以要求同时出现在一个文档中,也可以要求至少出现一个单词。这对应两种组合多个单词构成最后检索结果的方法,相与和相或。更进一步,还可以要求搜索引擎不出现某一个关键词,在百度中可以通过一个减号“-”来表示。比如我想搜索“电子科技大学”,但不是“西安电子科技大学”,就可以输入“电子科技大学 -西安”。这些组合方式在数学上来说,其实就是集合操作。三种基本的集合操作“与”、“或”、“非”正对应着这三种组合方式。这就是毕业项目的第6个部分。
毕业项目的第7个部分是表达式求值的一个变种。在百度或者Google中,其实可以明确指出,多个单词之间是或的关系还是与的关系。比如:我想要搜索“北京”或者“大学”,可以使用检索词“北京 | 大学”,单词之间用竖线连接;如果想要同时检索“北京”和“大学”,可以使用检索词“北京 & 大学”,单词之间用&连接。当检索词由多个单词相与、相或组成复杂的逻辑表达式,就需要专门的函数来处理这种复杂的检索了。比如检索词是“北京 - 北京 & 大学 - 清华”,表示我想查找北京的信息,但是不想看到北京大学或者清华大学的信息。这仍然是一个表达式求值的问题,但是不同的是,表达式的值并不是直接求出,而是被表达成一组复合的检索关系。这就是毕业项目的7个部分了,是不是并没有想象的那么难。
完成了这个专项课程的毕业项目,我也可以说是,实现过搜索引擎的人了,虽然这个搜索引擎是最最简单的版本。在这个过程中,搜索引擎的面纱也被一步步揭开,你会发现搜索引擎也不过如此嘛。
但是搜索引擎其实远不止如此,百度和Google为了加快检索的速度、提高搜索的相关性,还做出了很多的努力。比如缓存常用的搜索结果,搜索结果反作弊。
知识虽然漫漫无穷,值得我们用一生去学习,但事物的本质与核心思想始终是简洁的。