先说说什么是编码。
编码(encoding)就是把一个字符映射到计算机底层使用的二进制码。
编码方案(encoding scheme)规定了字符串是如何编码的。
python编码,其实就是对python字符串的编解码问题,这也是为什么在python中,只有字符串,才有decode和encode方法。
在python中,字符串为str类型,其父类为basestring。unicode和ascii是str类型的两种常见编码,ascii是字符串的默认编码,如 str(12)。
ascii编码的字符串,7bit,编码范围为0-0x7f;
unicode为UCS2或UCS4, UCS2为16bit,编码范围为 0 - 0xffff;UCS4的编码范围为0-0x10ffff。
unicode是python编解码的核心,不同编码转换都需要通过unicode来进行。
Unicode 简介
Unicode是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。
UCS可以看作是"Unicode CharacterSet"的缩写。
常用的中英文编码
ASCII
美国编码
American Standard Code for Information Interchange,美国信息互换标准代码,是一种7位编码方案来表示所有的大写字母、小写字母、数字、标点符号和控制字符。
编码范围:0 - 0x7f
latin-1/iso-8859-1
西欧编码
编码范围:0 - 0xff
0x00-0x7f之间完全和ASCII一致,0x80-0x9f之间是控制字符,0xa0-0xff之间是文字符号。
utf-8
Unicode Transformation Format - 8 bit
UTF-8是以8位为单元对Unicode进行编码。
UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。
英文使用8位(即一个字节),中文使用24位(即三个字节)来编码。
具体如下:
0 - 0x7f single byte
0x80 - 0x7ff two bytes, each between 128 and 255
0x7ff - : three- or four-byte sequence, each between 128 and 255
utf-16
Unicode Transformation Format - 16 bit
采用16位对unicode进行编码
UTF-16以16位为单元对Unicode进行编码。对于小于0x10000的UCS码,UTF-16编码就等于UCS码对应的16位无符号整数。
对于不小于0x10000的Unicode码,定义了一个算法。
gb2312
简体中文编码
双字节等宽编码,
GB2312的编码范围是0xA1A1-0x7E7E
gbk/cp936
中文编码
双字节等宽编码,
GBK 编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。CJK就是中日韩的意思。
GBK的整体编码范围是为0x8140-0xFEFE,不包括低字节是0x7F的组合。
cp936 为 windows code page
gb18030
中文编码
GB18030编码向下兼容GBK和GB2312,兼容的含义是不仅字符兼容,而且相同字符的编码也相同。
有单字节、双字节和四字节三种方式。
GB18030 的单字节编码范围是0x00-0x7F,完全等同与ASCII;
双字节编码的范围和GBK相同,高字节是0x81-0xFE,低字节的编码范围是0x40-0x7E和0x80-FE;
四字节编码中第一、三字节的编码范围是0x81-0xFE,二、四字节是0x30-0x39。
注:gb2312、gbk和gb18030比较
编码范围:gb18030 > gbk > gb2312。
gb2312可以看作是gbk的真子集,而gbk是gb2312的真子集。
GBK和GB2312都是双字节等宽编码,而GB18030编码是变长编码,
big5
大五码,繁体中文编码。没用过。
Python编码
在Python中,上面这些编码都需要通过unicode进行间接转换,不能直接转换。比如将utf-8编码转为gb2312编码,则需要如下转换过程
utf-8 --> unicode --> gb2312
注:utf-8 --> unicode 为解码(decode), unicode --> gb2312为编码(encode)
中文编码在Python的表示,如下图所示
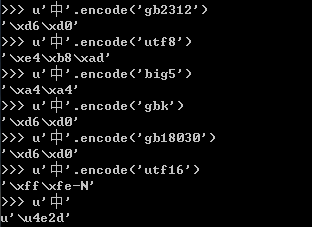
注:u'中' 为unicode字符串。若字符串以 u 开头,表示字符串为unicode编码。
参考资料
1、ASCII 、GB2312、GBK、GB18030、unicode、UTF-8字符集编码详解
http://blog.csdn.net/ylyuanlu/article/details/41844009
2、UTF-8 GBK UTF8 GB2312 之间的区别和关系
http://www.cnblogs.com/xiaomia/archive/2010/11/28/1890072.html