写在前面
在MindSpore开发过程中,由于动态Shape算子的开发需求,再加上MindSpore的动态Shape也在持续完善,笔者遇到了框架上的一些问题。通过查看源码和相关文档的方式,获得了初步的解决方案和感悟。这篇博客主要是将当时的见闻加以整理,并给出一点点开发建议。此外,当时笔者还做了组内分享,附件是分享的胶片,如果不想看文字版,也可以直接看胶片。由于本人刚入职不久,本博客适合于初学者,高手轻喷。
1 动态Shape的定义
动态Shape,指的是Tensor的Shape依赖于具体的运算,无法提前通过计算得出。具体来说分两种情况:算子输入是动态Shape和算子输出是动态Shape。其中,后者是常见的动态Shape算子,如图1的MaskedSelect算子是动态Shape算子,因为它的输出依赖于输入中Mask的具体数值,我们无法提前知道Shape的大小;而前者一般是被动态Shape算子感染的算子,例如MaskedSelect算子后面接一个Sum算子,那么这个Sum算子被MaskedSelect的输出感染了,所以此时的Sum算子也属于动态Shape算子。
>>> x = Tensor(np.array([1, 2, 3, 4]), mindspore.int64)
>>> mask = Tensor(np.array([1, 0, 1, 0]), mindspore.bool_)
>>> output = ops.MaskedSelect()(x, mask)
>>> print(output)
[1 3]
MindSpore有静态图和动态图模式,可以设置参数一键切换。在推导Shape时,动态图模式对算子逐个推导,不需要考虑整图中Shape的具体大小,所以前后端都很容易处理;而静态图模式需要推导出整图中所有算子的类型和Shape大小,以便于在前后端进行整图优化。下面阐述如何自定义一个支持动态Shape的算子以及简单分析一下动态Shape在MindSpore前后端的具体实现,包括静态图和动态图模式。
2 自定义算子
2.1 自定义静态Shape算子
首先简单回顾下如何在MindSpore自定义一个普通算子(Primitive),即实现一个静态Shape算子。在MindSpore里,每个算子有对应的前端注册和后端实现。其中,前端注册需要明确算子的输入输出个数,相应的参数检查和推导(infer)函数。这里推导函数的作用是告诉框架算子输入输出的Shape大小和类型的计算和推导规则。后端实现是指在不同硬件平台下的具体实现,如CPU,GPU和Ascend等。前后端如此分工的原因是由它们在AI框架中所担负的职责决定的。前端旨在提供硬件无关的中间表达,而后端针对前端的表达执行硬件感知的实现。
前端注册。前端注册也称作算子原语注册。首先每个算子是一个单独的类,继承于PrimitiveInfer作为子类,且类的名称即要注册的算子名称。MindSpore已有的算子可以在官网查询。PrimitiveInfer定义在mindspore/ops/primitive.py。图2是PrimitiveInfer在源码中的注释。
class PrimitiveWithInfer(Primitive):
"""
PrimitiveWithInfer is the base class of primitives in python and defines functions for tracking inference in python.
There are four method can be overridden to define the infer logic of the primitive: __infer__(), infer_shape(), infer_dtype(), and infer_value().
If __infer__() is defined in primitive, the __infer__() has the highest priority to be called.
If __infer__() is not defined, infer_shape() and infer_dtype() can be defined to describe the infer logic of the shape and type. The infer_value() is used for constant propagation.
"""
def __init__(self, name):
Primitive.__init__(self, name)
self.set_prim_type(prim_type.py_infer_shape)
def infer_shape(self, *args):
"""
Infer output shape based on input shape.
"""
return None
def infer_dtype(self, *args):
"""
Infer output dtype based on input dtype.
"""
return None
def infer_value(self, *args):
"""
Infer output value based on input value at compile time.
"""
return None
def __infer__(self, *args):
"""Infer shape, type, and value at the same time by using dictionary as arguments."""
__init__函数定义了输入输出的名称和数量,并且有四个可重载的类成员方法:__infer__,infer_shape,infer_dtype和infer_value。其中:
- infer_shape:旨在根据输入的Shape推导输出的Shape;
- infer_dtype:旨在根据输入的数据类型推导输出的数据类型;
- infer_value:要求在编译期根据输入的值直接算出输出的值,一般配合@constexpr装饰符使用,适合于少量算子;
- __infer__:集成了另外三个infer函数的所有功能,拥有最高优先级,输入和输出是字典的形式。
在撰写算子时一般参考已有的算子,在已有的算子基础上进行修改。
后端实现。后端实现依赖于具体的硬件平台,如CPU,GPU和Ascend(自研的昇腾芯片)等。相关代码存放在mindspore/ccsrc/backend/kernel_compiler文件夹下。这里以CPU为目标平台作为例子进行阐述。和算子原语注册类似,首先需要在mindspore/ccsrc/backend/kernel_compiler/cpu文件夹下创建.cc和.h文件,定义一个继承CPUKernel的子类。图3是CPUKernel的主要成员函数。
class CPUKernel : public kernel::KernelMod {
public:
CPUKernel() = default;
~CPUKernel() override = default;
virtual void Init(const CNodePtr &kernel_node);
virtual void InitKernel(const CNodePtr &kernel_node) = 0;
virtual bool Launch(const std::vector<AddressPtr> &inputs, const std::vector<AddressPtr> &workspace,
const std::vector<AddressPtr> &outputs) = 0;
protected:
template <typename T>
inline T *GetDeviceAddress(const std::vector<AddressPtr> &addr_list, size_t index);
};
- Init:通常保持默认实现。它会接连调用InitKernel和InitInputOutputSize函数;
- InitKernel:需要重载。入参是CNode指针的引用,通过调用mindspore/ccsrc/backend/session/anf_runtime_algorithm.cc中定义的方法,我们可以获取该算子节点的输入输出的Shape以及算子的属性信息,如算子的坐标(axis)属性,这些属性在算子原语的__init__中注册。InitKernel方法的职能包括:
- 检查参数的合法性,如输入输出的数量,参数的类型,Shape大小和属性等;
- 指定workspace的大小,这里的workspace表示算子执行过程中需要申请的内存大小,可以由框架统一申请和释放。CPU算子用的较少。常用于GPU,需要框架明确申请显存。
- Launch:需要重载。三个入参分别是input,workspace和output的地址。在具体实现中,我们可以采用多线程加速计算,也可以调用第三方库:如CPU可以用MKL实现神经网络算子,Eigen实现线性代数等;GPU可以用CUDA,CUDNN等。
- GetDeviceAddress:公共接口,供Launch调用,用于获取输入输出地址。
总的来说,一般我们会重载InitKernel和Launch方法。其中,InitKernel通常做初始化相关的工作,提前计算好内存大小,所以将与不依赖输入值的操作放在此方法执行;而Lanuch执行具体的计算,并且算子之间有依赖关系,当然这是框架应当考虑的事情。后面动态Shape部分也会提及一点。当我们写完算子的Kernel类之后,需要注册该算子的输入输出类型。CPU后端提供了三种算子注册方式:
- MS_REG_CPU_KERNEL: 通常用于非模板类,在Launch控制不同类型的处理;
- MS_REG_CPU_KERNEL_T: 通常用于输入为泛型的模板类,每注册一次实例化一个模板;
- MS_REG_CPU_KERNEL_T_S: 通常用于输入和输出均为泛型的模板类,常用于输入输出不统一的算子,如Cast算子;
三种注册存放在mindspore/ccsrc/backend/kernel_compiler/cpu/cpu_kernel_factory.h。本质上都是调用工厂方法进行注册,需要考虑的是如何根据算子的特点选择不同的注册,使得算子的实现更加简洁和易扩展。
综上所述,整个AI框架的运行逻辑如下:前端负责将Python表达翻译成算子组成的图(又叫ANF图)。图的每个节点的输入输出的类型和Shape大小都被正确推导;后端拿到这个图之后有一个算子选择的过程,即根据算子名称,输入输出个数和类型匹配具体的算子实现,最后将执行结果返回到Python侧输出。此外,不同后端的算子选择的过程会有所不同。如在CPU会自动降低精度寻找对应算子,而GPU是严格匹配算子注册类型。然而,动态Shape的出现给这个过程带来了一些变化:在前端,根据动态Shape的定义,我们无法预测算子的输入/输出的准确Shape;在后端,由于内存提前分配的缘故,我们需要在实现的过程注意动态Shape带来的细微变化。另外,算子注册上也有一些需要注意的地方,下一节会详细阐述。
2.2 自定义动态Shape算子
AI网络中用到的算子通常是静态Shape的算子,采用Python编写推理函数简单直接,因此前期MindSpore的推理函数主要在Python侧定义。随着对各类计算场景的需求增多,MindSpore需要支持动态Shape的算子,这类算子不仅要在前端推导输入输出的Shape范围(最大/最小Shape),还需要在后端执行的时候计算算子实际的Shape大小,以便于框架更好地进行内存管理(这部分后面分析代码的时候可以看到)。换句话说,后端也需要调用推理函数。然而,由于Python存在全局解释锁(Global Interpreter Lock, GIL),后端执行的时候需要由C++运行时转到Python运行时,这不仅需要框架在处理流程上进行变动,也不利于框架的并行处理。所以后端需要调用C++侧的推理函数,Python侧的原语定义不能满足动态Shape的需求。再后来,为了框架的统一,MindSpore也逐步推进前后端使用同一个算子推理函数。图4是目前的算子原语注册的流程。当同时存在Python侧和C++侧推理函数时,以C++侧的推理函数为主。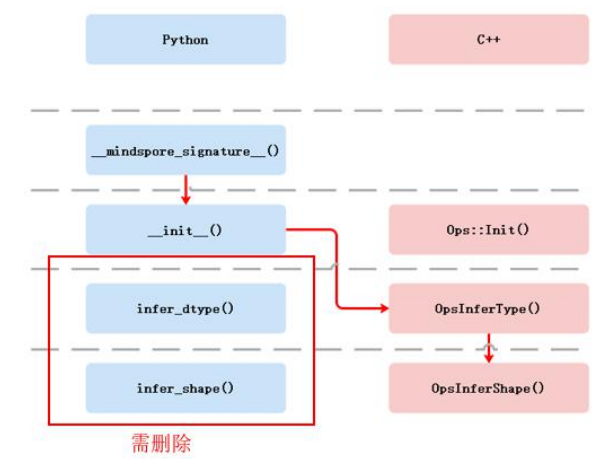
前端注册。C++侧的算子原语前端注册和Python侧相似:都需要继承基类定义一个算子子类,用于声明算子和输入输出。不同的是:infer函数不是作为类的一部分,需要另外定义,并以宏的方式(与后端注册算子实现类似)注册到prim_eval_implement_map中,供框架统一被调用。具体步骤如下:
在.h文件,继承PrimitiveC声明算子子类、定义推理函数接口;
在mindspore/core/base/core_ops.h声明一个const指针指向新定义的算子原语;
在.cc文件,实现成员函数(若有)和推理函数,并注册推理函数;
为了描述输入输出中shape,value,dtype等信息,C++侧定义了一种AbstractBase的抽象基类,其继承关系如图5所示。其中使用的最广泛的是AbstractTensor和AbstractTuple两个子类,可以认为分别是Python的Tensor和Tuple两种类型的C++实现。此外,通过上述步骤2定义PrimitivePtr类型的const指针可以获取算子的属性值(通过GetAttr方法),这是部分算子确定类型和Shape大小所必须的。前端和后端都会调用prim_eval_implement_map中定义的infer函数(若有),在后面的源码分析部分可以看到。此map的key是上述步骤2定义的const指针,value是步骤3定义的推理函数。综上,C++侧的前端定义表达是足够覆盖Python定义算子原语所需要的信息,包括原语类和数据结构,虽然语法上没有Python侧的易用。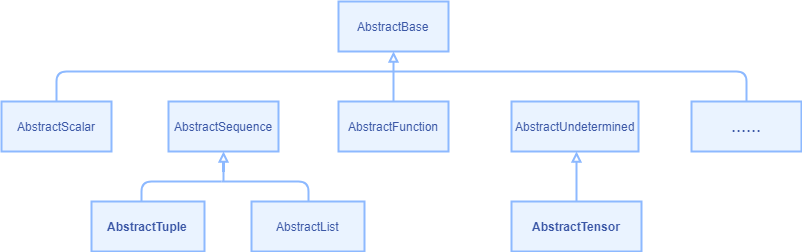
对于动态Shape算子,我们需要设置Shape中变化的维度为-1,还有最大和最小的Shape。如果连维度的多少也不确定,那么Shape直接固定为[-2]。以图1的MaskedSelect算子为例,推导的shape,min_shape和max_shape分别为[-1],[size]和[0]。其中size为mask变量中为True的个数。由此可见,小于0是框架判断是否为动态Shape的依据(后续也可以在代码中看到)。此外,编写动态Shape算子的推理函数时,需要特别注意会对最终Shape有确定作用的地方。如Sum算子的属性KeepDims是否为True对Shape有影响。一句话概括就是,具有动态Shape性质的算子需要编写C++侧的前端算子原语注册,并需要准确描述变化的Shape和最大/最小Shape。更详细的示例可以参照这个开发指南。
后端实现。后端下动态Shape算子实现和静态Shape的算子没有什么大的变化,但我们需要注意的是动态Shape算子在后端的执行流程以及实现细节。正如前面2.1节所说,InitKernel会做输入和输出Shape大小的初始化,并且Init部分是统一执行的。然而,动态Shape算子是在执行之后才能知道算子的具体大小。也就是说,InitKernel获取的信息是不准确的(注:截至r1.3的版本,动态Shape算子仍在整改中,听说后面的版本会支持如果有动态Shape算子会重新出发Init)。所以,当一个算子的输入是动态Shape时,我们需要注意InitKernel有没有初始化输入输出大小供后面的Launch使用,这个地方容易导致算子运行错误。Launch部分需要注意的是:
- 通过SetOutputInferTypeAndShape的方式设置每个输出的数据类型和数据大小。该方法存放在mindspore/ccsrc/backend/session/anf_runtime_algorithm.h。MaskedSelect算子的CPU实现是一个很好的参考;
- 在计算之前正式开始之前,要注意输入输出的Shape是否准确,如前面所说的InitKernel是一种情况。此外,还有一些算子(如CPU的Cast算子),通过output->size / sizeof(T),即将分配的output指针的大小作为最后的大小,这个长度有可能会出错。例如CPU后端当存在类型不匹配算子时会自动插入cast算子做自动转换。此时的Cast算子会由于前一个算子是动态Shape算子并且未执行inferShape更新Cast算子输入的真正Shape而导致分配内存大小不正确,这时候Cast算子的输出长度就不正确。避免这种情况的做法是用AnfAlgo::GetOutputInferShape获取正确的大小。
除了算子实现之外,还需注意的是动态Shape算子的注册问题。
3 结语
就到这里结束吧!本来还想多写一章对库上相关代码的分析。不过正如前面所说,MindSpore的代码还在不断完善,相信动态Shape算子会支持得更好,再加上笔者只是前期有动态Shape算子的需求,所以后面就没有持续追踪了。