摘要:
问题描述:1、数据库查询去重,云开发没有distinct2、数据库排序,联表查询用aggregate的情况下,不能用orderby()3、lookup()情况下,如何取用as中嵌套的字段4.联表中两个表中有字段名相同('_openid'),且需要对其中一个添加match限制问题解决:1、用group()代替distinct2、转用aggregate下的方法sort(),且应在project()中写
问题描述:
1、数据库查询去重,云开发没有distinct
2、数据库排序,联表查询用aggregate的情况下,不能用orderby()
3、lookup()情况下,如何取用as中嵌套的字段
4. 联表中两个表中有字段名相同('_openid'),且需要对其中一个添加match限制
问题解决:
1、用group()代替distinct
2、转用aggregate下的方法sort(),且应在project()中写相应设置,否则sort()会失效
3、摸索出来的,貌似没找到小程序文档里这么用的,能跑就大吉大利了
4、db.collection('表名')中对应哪个表,match中相应字段就指的是该表中的字段,不需要额外加条件区分
示例:
基本情况:联表查询两个表,forum表中 '_id' 字段对应f-reply表中 'forum_id' 字段,一条forum表的记录对应多条f-reply表的记录
需求:查出f-reply表中特定'openid'对应forum表中的'_id','title'等字段
两表的内容:
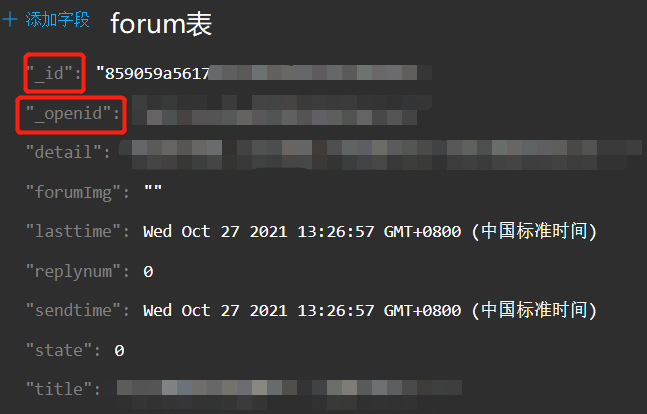
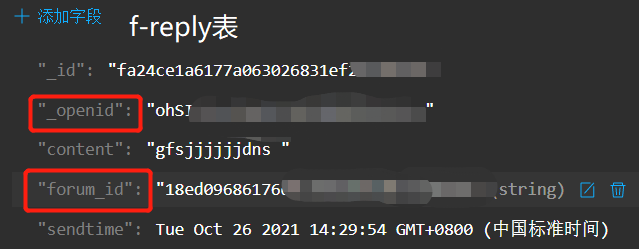
代码:
constdb=cloud.database({
env:"........"
})
const$=db.command.aggregate
db.collection('f-reply').aggregate().lookup({
from: "forum",
localField:"forum_id",
foreignField:"_id",
as:"forum_info"}).match({
//此处_openid是f-reply表字段
_openid:event.openid
}).project({
forum_id:1,
forum_info:1,
sendtime:1 //后面sort要用的字段,必须要在project中写明,否则排序失效}).group({
_id:'$forum_id',//这里必须设置一个'_id',作为group中合并的列名
title:$.first('$forum_info.title'),
replynum:$.first('$forum_info.replynum'),//粗暴解决,重复的title值都相同,所以直接取第一个
forumImg:$.first('$forum_info.forumImg')
}).sort({
sendtime:-1}).end()查询结果:
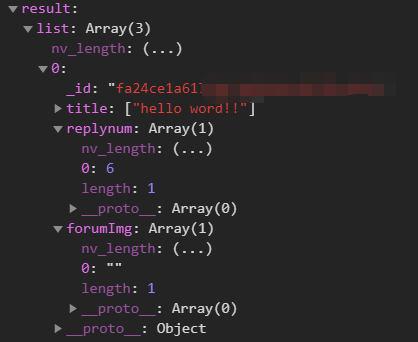
参考资料:
去重:https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database/aggregation/aggregation.html
字段重名:https://developers.weixin.qq.com/community/develop/doc/0004a67ebc4ff8e4da9ae9a8056c00
总结:本文可能存在误导,总之,不要靠近云开发...