一、备份恢复方案
ES支持两种备份恢复方案,第一种是官方的工具snapshot,第二种是第三方工具elasticsearch-dump。
snapshot工具
- 官方提供的工具,也叫快照备份;
- 备份原理是需要一台存储服务器,这里使用nfs存储服务器,并将其挂载到各个节点上,snapshot工具会将每台ES数据分开备份在nfs服务器上。
- 备份数据无法直接查看,需要恢复后才能查看;
elasticsearch-dump工具
- 第三方工具;
- 备份可以存储在本地,也可以存储在第三方存储服务器上;
- 备份数据可以直接查看,是json格式的。
参考资料:官方资料
二、官方备份恢复
1、环境准备
我这里使用三台服务器,两台es,一台nfs
| 主机名 | 服务 | IP |
|---|---|---|
| es01 | es | 10.154.0.110 |
| es02 | es | 10.154.0.111 |
| nfs | nfs | 10.154.0.112 |
2、安装nfs
在10.154.0.112这台服务器上安装nfs,过程就不详细说了。
yum install -y nfs-utils -y
systemctl enable rpcbind
systemctl enable nfs
systemctl start rpcbind
systemctl start nfs
检查所有服务器,需要保证所有服务器的elasticsearch用户的uid号一致,gid号也一致。
id elasticsearch
#如果不一致,使用如下方法改为一致
systemctl stop elasticsearch
userdel elasticsearch
groupadd -g 1001 elasticsearch
useradd -u 1000 -g elasticsearch -s /sbin/nologin -M elasticsearch
我这里的gid是1001,uid是1000,也就是说这三台服务器的elasticsearch用户的uid必须为1000,gid必须为1001;
可以查看/etc/passwd文件找到未使用的uid跟gid号。
编辑nfs配置文件
#这里的anonuid就是elasticsearch用户的uid,anongid就是它的gid
vim /etc/exports
/data/es 10.154.0.0/24(rw,sync,all_squash,anonuid=1000,anongid=1001)
创建挂载目录
mkdir -p /data/es
chown -R elasticsearch.elasticsearch /data/es/
查看挂载情况
$ systemctl reload nfs
#查看共享目录情况
$ showmount -e 10.154.0.112
Export list for 10.154.0.112:
/data/es 10.154.0.0/24
挂载nfs共享目录
在es01跟es02服务器上执行挂载nfs目录命令
mkdir -p /data/backup
yum -y install nfs-utils
mount -t nfs 10.154.0.112:/data/es /data/backup
df -h
#永久挂载
vim /etc/fstab
10.154.0.112:/data/es /data/backup nfs defaults,_netdev 0 0
其他资料:取消挂载
3、snapshot备份
1)全部备份
编辑es01,es02的配置文件
#在最后添加一行如下命令,注意冒号后面有一个空格
vim /etc/elasticsearch/elasticsearch.yml
path.repo: ["/data/backup"]
重启es服务器,因为做了集群,先重启从es服务器,再重启主es服务器
systemctl restart elasticsearch
创建存储快照空间
PUT /_snapshot/my_fs_backup #指定存储库名
{
"type": "fs",
"settings": {
"location": "/data/backup/my_fs_backup", #存储路径
"compress":true #是否压缩
}
}
GET /_snapshot/my_fs_backup #查看快照信息
此时会发现es01跟es02的/data/backup/目录下多出一个my_fs_backup文件夹,该文件夹此时是空的,因为我们还没有执行备份。
给所有索引创建快照
PUT /_snapshot/my_fs_backup/snapshot_1?wait_for_completion=true
效果如下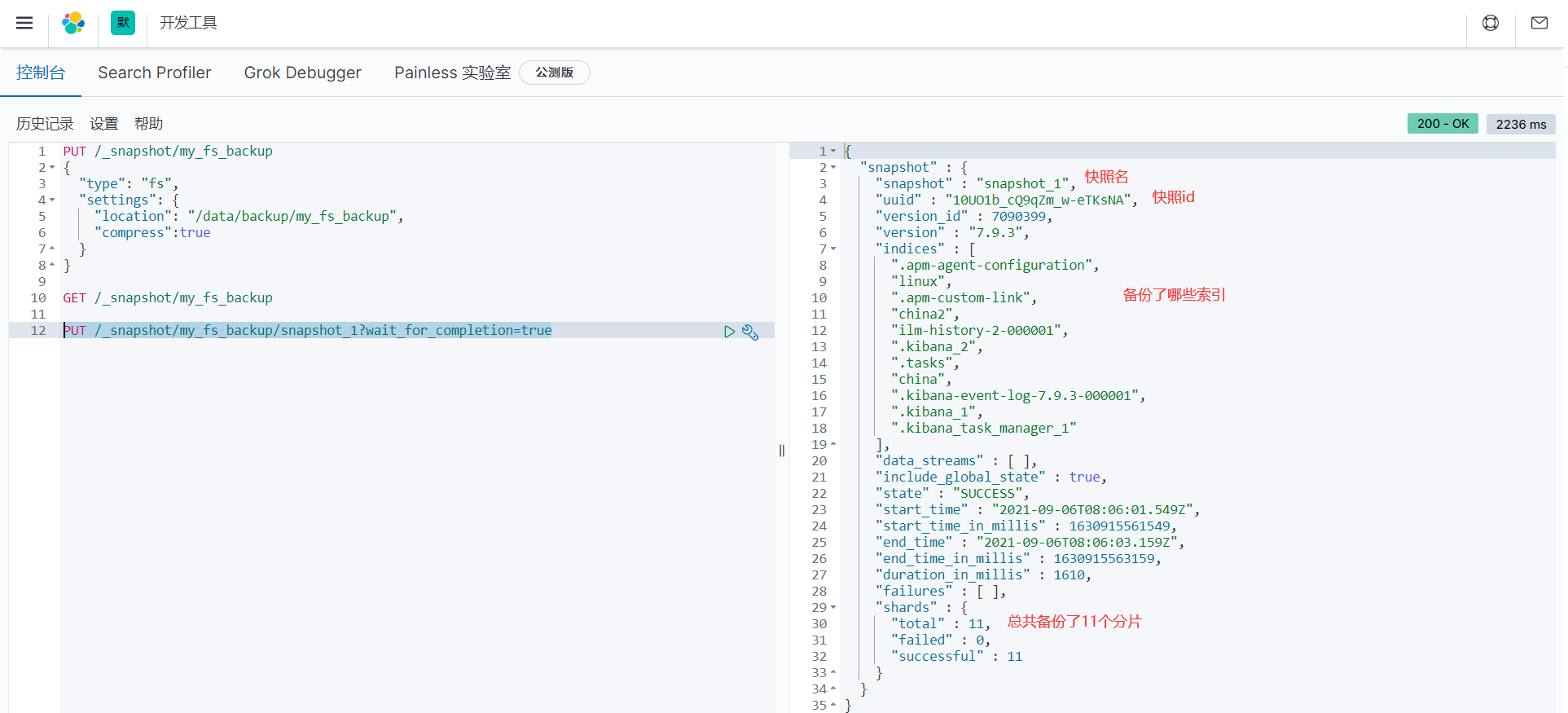
此时我们再来看看/data/backup/my_fs_backup文件夹里都有什么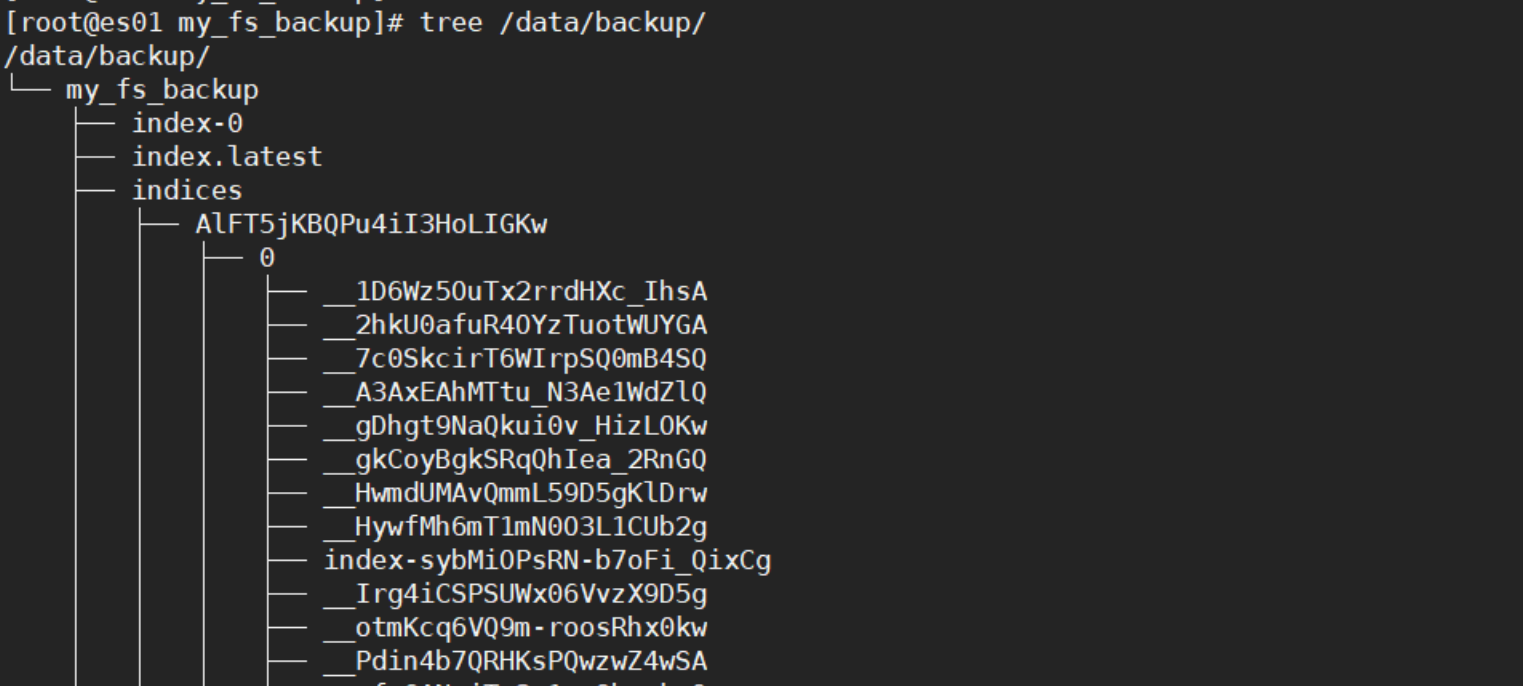
index-0文件可以使用jq查看,除此之外大部分文件是无法直接查看的。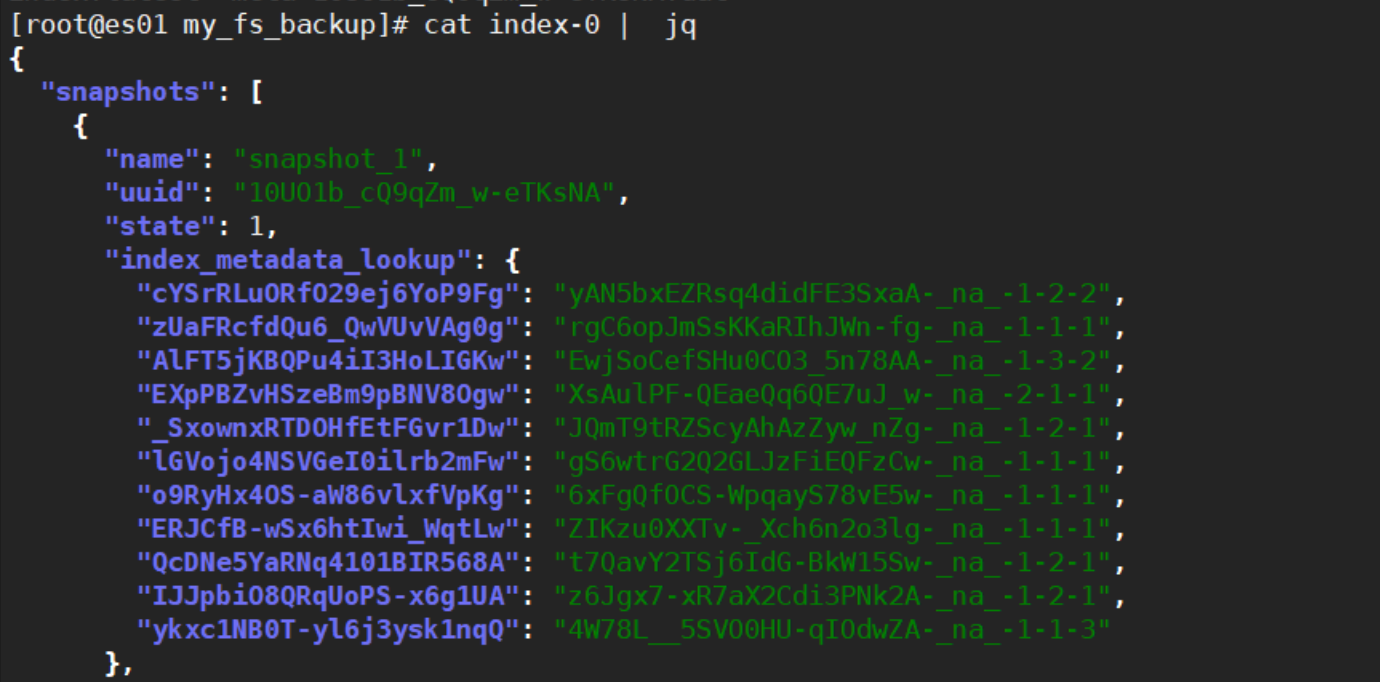
jq工具可以让json格式的数据看起来更加的美观便于我们查看,关于安装jq,需要配置epel源
然后执行yum -y install jq安装即可
2)备份指定索引
前面说了备份全部索引,这里讲一下备份指定索引
PUT /_snapshot/my_fs_backup/snapshot_2?wait_for_completion=true
{
"indices": "linux,linux76",
"ignore_unavailable": true,
"include_global_state": false
}
- 这里使用的是之前创建的存储快照空间my_fs_backup
- 创建的是名为snapshot_2的快照
- 只备份了linux,linux76这两个索引
3) 创建以时间命名的快照
PUT /_snapshot/my_fs_backup/%3Csnapshot-%7Bnow%2Fd%7D%3E
效果如下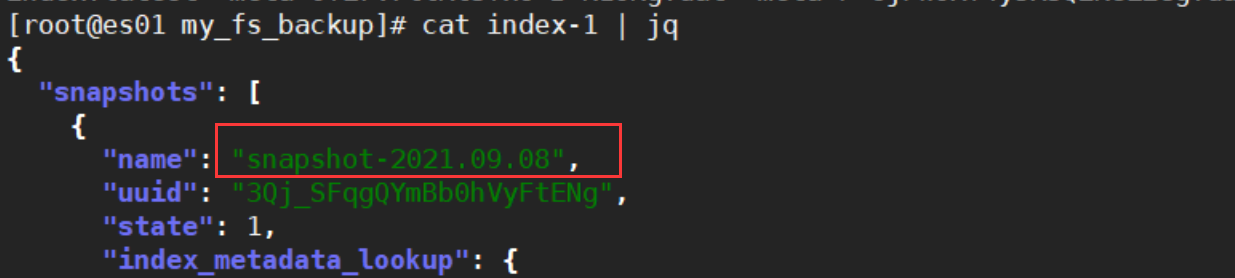
4、snapshot还原
1) 全部还原
使用全部还原,需要将原来的索引全部删除才能还原,如果有索引冲突,就会报错
#恢复全部索引
POST /_snapshot/my_fs_backup/snapshot_1/_restore
报错如下所示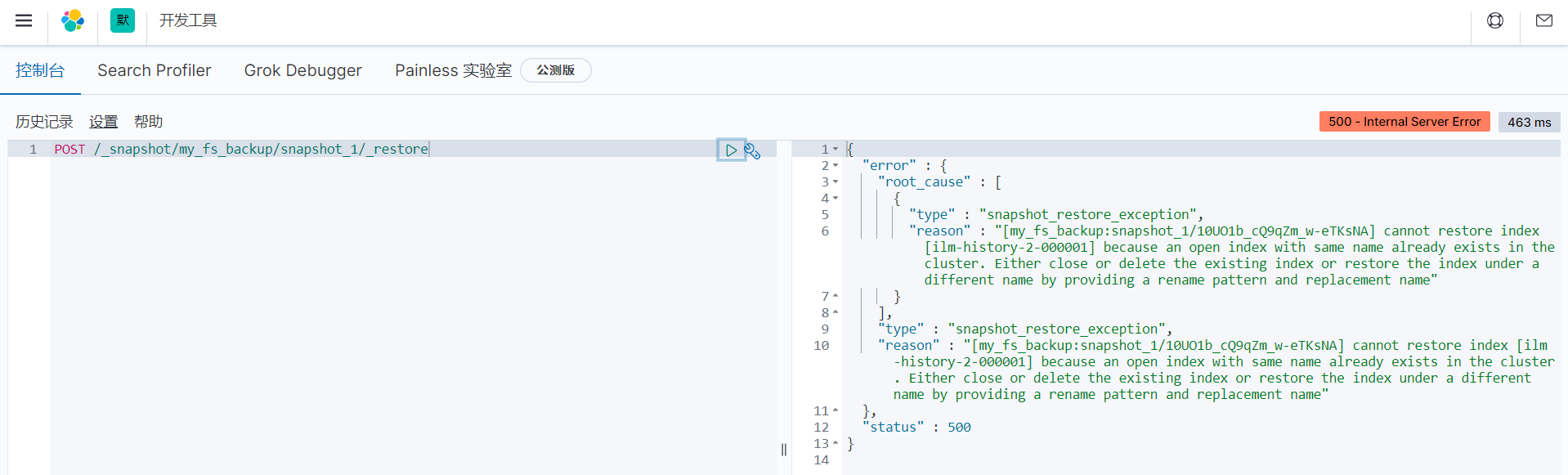
另外如果全备时备份了kibana的索引,恢复时需要关闭kibana服务,因为kibana服务会一直创建.kibana索引并向其写入数据,导致索引冲突。
systemctl stop kibana
#删除所有索引
curl -X DELETE 'http://10.154.0.110:9200/_all'
#全部还原
curl -XPOST 'http://10.154.0.110:9200/_snapshot/my_fs_backup/snapshot_1/_restore'
systemctl start kibana
那么有没有一种方式可以保留原来的索引呢?当然有的,接下来就讲
使用如下命令如果发现有同名索引就会将还原的索引重命名以backup_开头的索引,然后再进行还原。
POST /_snapshot/my_fs_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "*", #还原所有索引
"ignore_unavailable": true, #是否忽略显示错误,默认false不忽略,true为忽略
"include_global_state": false, #是否恢复集群状态,false为不恢复
"rename_pattern": "(.+)", #触发正则,即发现正在使用的索引跟要还原的索引同名
"rename_replacement": "backup_$1", #将要还原的同名索引名前加上backup_前缀
"include_aliases":false
}
2)还原指定索引
还原指定索引并修改副本分片设置
POST /_snapshot/my_fs_backup/snapshot_1/_restore
{
"indices": "linux,linux76", #只还原linux,linux76索引
"index_settings":{
"index.number_of_replicas":1 #将副本分片改为1个
}
"ignore_index_settings":[
"index.refresh_interval"
]
}
5、命令总结
snapshot备份还原总结
1、备份类
#创建存储快照空间
PUT /_snapshot/my_fs_backup #指定存储库名
{
"type": "fs",
"settings": {
"location": "/data/backup/my_fs_backup", #存储路径
"compress":true #是否压缩
}
}
#备份全部索引
PUT /_snapshot/my_fs_backup/snapshot_1?wait_for_completion=true
#备份指定索引
PUT /_snapshot/my_fs_backup/snapshot_2?wait_for_completion=true
{
"indices": "linux,linux76",
"ignore_unavailable": true,
"include_global_state": false
}
2、还原类
#恢复全部索引,如果索引冲突会报错
POST /_snapshot/my_fs_backup/snapshot_1/_restore
#恢复全部索引,索引冲突会改名
POST /_snapshot/my_fs_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "*", #还原所有索引
"ignore_unavailable": true, #是否忽略显示错误,默认false不忽略,true为忽略
"include_global_state": false, #是否恢复集群状态,false为不恢复
"rename_pattern": "(.+)", #触发正则,即发现正在使用的索引跟要还原的索引同名
"rename_replacement": "backup_$1", #将要还原的同名索引名前加上backup_前缀
"include_aliases":false
}
#还原指定索引
POST /_snapshot/my_fs_backup/snapshot_1/_restore
{
"indices": "linux,linux76", #只还原linux,linux76索引
"index_settings":{
"index.number_of_replicas":1 #将副本分片改为1个
}
"ignore_index_settings":[
"index.refresh_interval"
]
}
3、查询类
#查询快照信息
GET /_snapshot/my_fs_backup/snapshot_1
#查看正在运行的快照
GET /_snapshot/my_fs_backup/_current
#删除快照
DELETE /_snapshot/my_fs_backup/snapshot_1
#删除存储库
DELETE /_snapshot/my_fs_backup
三、第三方工具备份恢复
使用elasticsearch-dump工具需要node环境
1、安装node环境
cd /opt/
wget https://nodejs.org/dist/v12.13.0/node-v12.13.0-linux-x64.tar.xz
tar xf node-v12.13.0-linux-x64.tar.xz
mv node-v12.13.0-linux-x64 node
echo 'export PATH=$PATH:/opt/node/bin'>>/etc/profile
source /etc/profile
npm -v
node -v
2、安装es-dump工具
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm install elasticdump -g
elasticdump --version
3、使用es-dump备份还原
1) 备份指定索引
$ elasticdump \
--input=http://10.154.0.110:9200/linux \
--output=/data/es_backup/linux.json \
--type=data
2)备份成压缩格式
$ elasticdump \
--input=http://10.154.0.110:9200/linux \
--output=$|gzip > /data/es_backup/linux.json.gz
3)备份分词器跟数据
$ elasticdump \
--input=http://10.154.0.110:9200/linux \
--output=/data/es_backup/linux_mapping.json \
--type=mapping
$ elasticdump \
--input=http://10.154.0.110:9200/linux \
--output=/data/es_backup/linux.json \
--type=data
4)还原指定索引
#调换一下备份时input跟ouput的位置即可
$ elasticdump \
--input=/data/es_backup/linux.json \
--output=http://10.154.0.110:9200/linux \
--type=data
4、批量备份脚本
这里通过awk去除了前面带点的系统索引,如.kibana等索引,相当于只备份用户索引
#!/bin/bash
es_addr=10.154.0.110
es_port=9200
index_list=`curl -s ${es_addr}:${es_port}/_cat/indices|awk '$3!~/^\./{print $3}'`
for index in $index_list
do
elasticdump --input=http://${es_addr}:${es_port}/${index} --output=/data/${index}.json --type=data
done
备份全部索引版本
#!/bin/bash
es_addr=10.154.0.110
es_port=9200
index_list=`curl -s ${es_addr}:${es_port}/_cat/indices|awk '{print $3}'`
for index in $index_list
do
elasticdump --input=http://${es_addr}:${es_port}/${index} --output=/data/${index}.json --type=data
done
5、带密码认证的导出
导出
elasticdump \
--input=http://tz:tz110@10.154.0.110:9200/linux \
--output=/data/es_backup/linux.json \
--type=data
导入
elasticdump \
--input=/data/es_backup/linux.json \
--output=http://tz:tz110@10.154.0.110:9200/linux \
--type=data
tz是用户名,tz110是密码;
导出的还是明文json文件,未被加密;
导入可以不写用户名密码一样可以导入;
感觉没啥用!
6、注意事项
1、如果恢复时,数据冲突了,冲突的数据会被覆盖
2、如果原来的索引存在备份文件里没有的数据,会被保留下来
7、来个实验
接下来做个实验,创建linux索引并向其插入数据,结果如下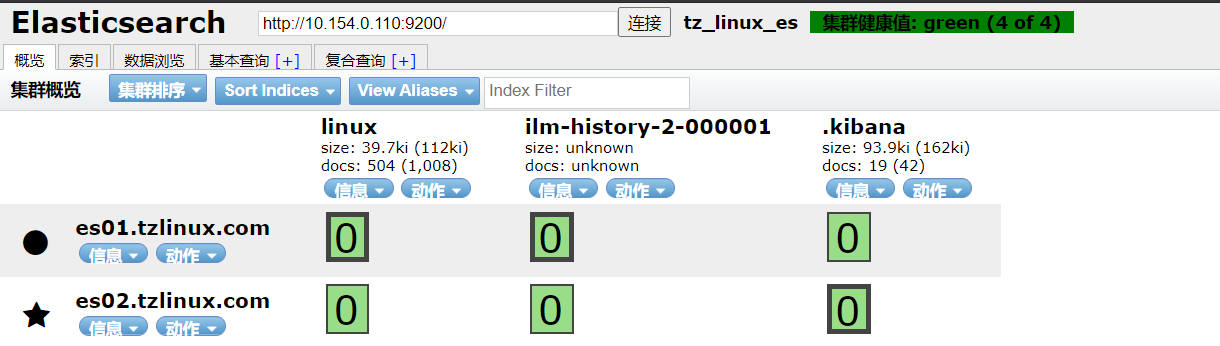
注意此时的linux索引有504个文档,括号里的1008表示linux索引有一个副本,副本分片加主分片的文档数一共1008个文档
执行备份
查看备份文件行数,如下图所示,有504行,每行表示一个文档,即一条数据,这跟es-head显示的结果相同
可以看到备份文件是明文的数据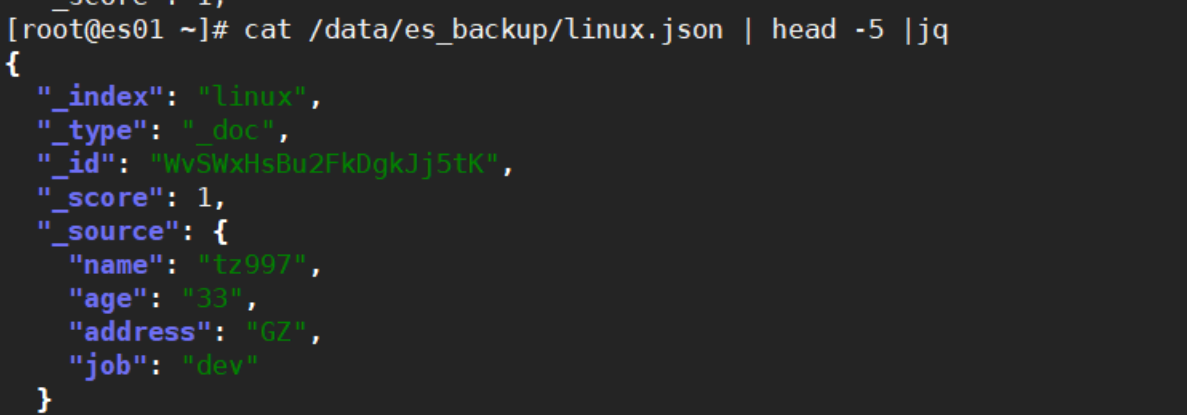
参考资料
老男孩教育_day106_视频