Abstract MTMCT:从多个摄像头采集的视频中跟踪多个人。 Re-id:从一系列图片中检索与一张被查询图片相似的图片。 我们用CNN为MTMCT和Reid学习好的特征。 贡献包括: ①为训练设计的一个自适应权重的三重损失 ②一种新的艰难身份挖掘技术 我们测验了好的re-id和好的MTMCT分数之间的相关性,并且做了消融研究,以阐明系统主要成分的贡献。
1.Introduction
MTMCT目标:给定多个摄像头采集的视频,在所有视频帧中决定每个人的位置。 MTMCT是有难度的:为减少成本,摄像头分布较远,并且视野域不总是重叠的。所以挑战有:遮挡,视角变化,光照变化,行人数量提前未知,要处理的数据量巨大,等等。 Re-id:与MTMCT密切相关。给定一张查询图片,re-id的系统将会从一系列其他人的快照数据库中检索图片(不同摄像头,不连续帧),然后根据与被查询图片的相似度,降序排列。在数据库中,与被查询图片身份相同的图片将排在前面。 二者的区别: ①任务不同 Re-id排列对于一张查询图片的距离。(相似度) MTMCT把图像对分成相同身份或者不同身份。 ②metric不同 Reid:排列性能 MTMCT:分类错误率 这似乎表明外观特征要从不同的loss中学习。Ideally, reid的loss应当确保:对于任意一张(any query)查询图片a来说,图片a与身份相同的特征之间的最大距离要小于图片a与与之身份不同的特征之间的最小距离。这可以确保,对于任意给定的查询图片,可以得到正确的特征排列。 MTMCT的loss应当确保:任意两个(any two)身份相同的特征之间的最大距离要小于任意2个不同身份的特征之间的最小距离。这样在同一种身份和不同种身份的距离之间就有一个间隔margin。 So, 0-MTMCT loss意味着0-reid loss。 但是,用MTMCT的loss进行训练代价很高,因为要求用所有的特征对作为输入。此外,相同身份对的数量和不同身份对的数量(超级多)很不平衡。 在本文中,采用了一种Reid类型的三重损失函数,训练过程基于难例挖掘,并且获得了高性能的特征。实验也展示出在适度拥挤的情况下跟踪时,将reid rank的准确度提高,超过一定点时,会使得MTMCT的收益递减。(起反作用了呗) 为了把特征用于MTMCT,提出了一个pipeline。
pipeline流程: 给定视频流,用行人检测器从视频中提取Bbox。为进行轨迹推断,特征提取器要从观测中提取运动特征和外观特征。这些特征将被轮流转换成相关性,并且会用相关聚类优化的方式打上标签。最后做一些后处理的工作:对漏检插值和去除低置信度的轨迹。多阶段推理为轨迹片段、单摄像头和多摄像头轨迹,重复进行了轨迹推理的过程。 在训练时,检测器被单独训练。特征损失会惩罚那些产生错误相关的特征。 在测试时,采用了一种基于相关聚类的数据关联算法,将观测分到不同的身份组。为降低计算复杂性,在跟踪器中采用了标准的分层推理和滑动时间窗口的技术。 当训练时,并没有包含相关聚类。而是假设:高质量的外观特征可以产生好的聚类结果,只训练这些特征就行了。实验结果也证明了这一假设。 Contributions: ①提出一种自适应权重的三重损失,准确且稳定,这点与固定权重的变量不同。 ②提出一种代价不高的艰难身份挖掘模式,可以帮助学到更好的特征。 ③关于tracking和ranking的准确度之间的关系,提出新的见解 ④我们的特征在MTMCT和reid任务上产生了极好的结果。
2.Related work
这里只总结本文所用的。 Person detection: OpenPose Data association: 为了公式的简化和准确性,本文牺牲了计算成本,选择相关性聚类来进行数据关联。这个公式考虑到了所有成对项的情况,并且联合优化身份。一种与之等价的公式就是图多割,最小化分歧,而不是最大化一致性。 Appearance: 当前reid,好的效果往往依赖于深度学习,难例挖掘,数据增强,特殊的loss函数等。本文采用残差网络,采用类似的技术,为MTMCT和Reid学习到了好的特征。 Multiple Cameras: 本文采取时间约束的方法,排除不可能的摄像头之间的关联。随着观测物之间时间距离的增大,可把相关性衰减到0。相关性衰减保证了如果有一系列正相关的观测形成观测链的话,具有一定时间距离的观测可被关联。 Learning to Track: 本文,为相关性学习特征的时候,无需通过联合优化的方式测量轨迹质量。学习好的相关性会使得训练更加简单,代价也没那么高,对于MTMCT而言,可以实现极好的效果。
3.Method
Input:从n个不同摄像头中获得的一系列视频 Ground-truth:一系列多个摄像头的轨迹 MTMCT可以看作是一个有监督的学习问题,寻找最优的参数以尽可能的估计真实的轨迹。 然而,端到端的训练要求通过一个可以进行数据关联的联合优化层反向传播loss,不过,这个过程代价蛮高的。本文避免这种复杂性。方法是对于同一身份的样本对标注相关性为正,对于不同身份的样本对把相关性标注为负。然后,组合的优化就变得微不足道了。 我们的目的是在训练的过程中学习那些可以产生好的相关性的特征。之后再用相关性聚类的方法进行数据关联。在测试时,我们使用相关性聚类的方法最大化潜在错误相关性之间的一致性。 下面讲述如何学习外观特征和跟踪器的不同部分。
3.1 Learning appearance features
给定一个带有标签的行人快照的大集合,我们用an adaptive weighted triplet loss来学习外观特征。对于一个样本,正样本集,负样本集。重写triplet loss:
这里,m是给定的行人之间的分离间隔,d代表了外观距离。[.]+=max(0,.)。 这个公式的好处: ①通过用所有的样本,避免了三元组产生的组合过程。这样学习好的特征的关键就在于分配更大的权重给艰难的正样本和负样本。 ②正类和负类的不平衡性通过在权重分布中反映出来,就可以很容易的得到控制。 有一种用难例挖掘的方法建立起来的batch-hard triplet loss。这个损失只考虑了最艰难的正样本和负样本。那么对于公式2而言,这种batch-hard triplet loss的权重设计为: 这是二值的,满足条件为1,否则为0。 这种loss比传统的拥有统一权重的triplet loss结果要好。但是拥有统一权重的loss对离群点更加鲁棒,因为它们影响不了权重。 那么,我们希望定义一种权重,让L3像效果不错的batch-hard loss一样收敛的同时,也能对离群点保持鲁棒性。对此,有2点改进。 ①改进权重,使之能够实现高准确度,与此同时,训练也稳定。对每个anchor而言,公式3和公式4把全部的权重分配给最艰难的正样本和负样本,这样的话,忽视了其他的正样本和负样本。 而我们的做法是用softmax分配自适应的权重,小化权重的分布。
这种自适应权重,对于简单的样本给很少的importance,而比较重视最艰难的样本。当在一个batch中出现一些艰难的样本时,这些样本对于权重将会有公正的分享。这点不同于公式3和4,只把重要性分配给单个最重要的样本。 自适应权重是很有用的,当一个batch中最艰难的样本是一个离群点时,还可以从其他艰难样本中学习。实验也证明了自适应权重的有利属性。 对于训练过程中的batch构建,我们采用PK batches的思想。在每一个batch中,对于P个身份实体的每一个实体而言,有K个样本图片。这个方法在基于相似度的ranking上展示了非常好的性能,避免产生一个三元组的组合数。 在一个training epoch中,每个实体在他的batch中被轮流选择,剩余P-1个实体被随机采样。对于每个实体而言,K个样本也被随机选择。 ②改进了选择艰难实体的过程 随着训练集大小的增加,随机采样P-1个实体很难捕捉到最艰难的负样本,因此会降低batch的难度。这种影响在训练的后几轮迭代中会被观察到,在一个batch中,很多triplets展示出了0损失。 为了增加发现艰难负样本的几率,我们构建了两个集合从中进行采样。例子如下:
艰难样本池是在给定anchor的情况下,有H个最艰难的身份实体构成。 随机样本池是由剩余的实体构成。 然后,在一个大小为PK的batch中,给定an anchor identity,从艰难样本池或者随机样本池等概率的采剩余的P-1个样本。 这种技术采艰难负样本会更加频繁。这个池子可以从在网络训练了几轮之后构建出来,也可以从预先训练的网络中计算出来。
3.2 MTMC Tracker
这部分说了跟踪器的不同模块。 在我们的设计中,跟踪器首先为所有的检测输入计算特征,然后,估计所有特征对之间的相关性,最后,解决一个相关性聚类的问题,以把身份分配给观测(数据关联)。此外,有两个后处理的过程:插值和剪枝。对漏检进行插值,去除低置信度的轨迹。 Detector: OpenPose检测器 这个检测器学习部件亲和域,以捕获身体部件之间的关系,并且运用贪心分析法把部件亲和域联合起来,形成bbox。在训练期间,是在部件亲和域上进行监督的,而不是在bbox的准确度上进行监督。 Appearance feature 我们使用Resnet50模型,在pool5层后面接了一个带有1024个单元的dense layer,BN和Relu。另一个dence layer产生了128维的外观特征。用the adaptive weighted triplet loss,数据增强,艰难身份挖掘的方法训练模型。 定义两个检测之间的外观相关性为 . 阈值对所有训练对的正样本的距离和负样本的距离取均值。 数据增强 对训练图片在线裁剪和水平翻转等。此外还有一些其他技术,如,为模仿遮挡隐藏小的矩形图像块。 Motion correlation 我们使用一个线性运动模型来预测运动相关性。因为前向-反向预测误差是非负的,我们从训练集中使用这些轨迹,目的是学习能够把正负例分开的阈值,和一个能够把错误转换成相关性的尺度因子。运动相关性:。对于不可能的关联,相关性为负无穷。 Optimization 在优化的时候,有一个矩阵收集外观相关性和运动相关性。,可以随着观测间隔时间距离的增大,把相关性衰减到0。确保具有一定时间间隔的轨迹进行关联,关联链中观测呈正相关。所选参数要在小的训练集合上最大化跟踪的准确性。 通过相关性聚类建立目标的同一身份。给定一个带权值的图,如果,那么两个节点和就是同一个目标。 相关性聚类定义如下:
公式6最大化聚类之间的正相关或负相关。 公式7的约束确保解具有传递性。 Multi-Level reasoning 通过在3个层次上进行分层推理,降低了计算负担。 第一层:计算one-second long tracklets。 第二层:把tracklets关联成单摄像头的长轨迹。 第三层:把单摄像头的长轨迹关联成多摄像头轨迹。 Tracklets特点:不相交,one-second long windows. Trajectory:在一个滑动时间窗口中在线计算。 所有的trajectories在这个窗口中至少有一个检测可以被用作数据关联。 为单摄像头轨迹设置窗口宽度是10秒,为多摄像头轨迹设置窗口宽度是1.5分钟。
4.Experiments
4.1 Benchmarks
DukeMTMC 大尺度的跟踪数据集,在2.8k个身份实体上提取特征,有1.8k属于训练/测试集。 8个摄像头。每个摄像头视频长度是1 小时25分钟。在25分钟长度的test-easy序列和15分钟长度的test-hard序列上测试方法。Test-hard序列的特征是有4个摄像头,一组由50个人。用17分钟长度的验证序列做消融实验。 DukeMTMC-reID 有1404个身份实体在多于2个摄像头中出现,只有408个实体只出现在了一个摄像头中,(可看作是干扰物)。702个身份实体用于训练,702个用于测试。 Market-1501 1501 Identities 6个摄像头 用DPM检测器提取了32668个bbox。这个数据集很有挑战性,因为Bbox常常被误分配,视点也显著不同。751:training 750:testing
4.2 Evaluation
IDF1是MTMCT的主要指标。 单摄像头评估:MOTA,不足以报告多摄像头的error,因此只在单摄像头中使用。 对于re-id:rank accuracy + mAP
4.3 Model Training
为了训练,设置了P=18,K=4,m=1,分辨率resolution:256*128。前15000次迭代,学习率为xx,在迭代为25000时,学习率衰减为xx。在实验中,使用艰难身份挖掘技术,在迭代5000次时,一旦获得了特征,我们就构建the hard and random pools。然后,从这些pools中采样身份实体,直至最后迭代结束。这个hard identity pool的大小是H,并且发现相似的分数可以用30-100个实体获得。H为1,包含1个hard identity可能是an outlier。一个大的HN池接近于随机抽样。
5.Results
这里: 主要讨论了MTMCT的结果,在IDF1 score和身份召回率IDR上均表现很好。 研究了不同成分的影响,分析了常见的跟踪失败情况。 在reid上,所学的外观特征取得了很好的结果。
5.1 Impact of learning
评估了检测器和特征选择是如何在DukeMTMC 验证集上是如何影响多摄像头IDF1指标的。结果如下:
Baseline:BIPCC。检测器和特征对于性能的提升都很重要。
5.2 MTMC tracking
全部结果:
我们的方法提升的点蛮多的。多/单摄像头,IDF1,MOTA。Outperform all methods on IDF1 and MOTA。
5.3 Impact of loss and hard negative mining
Reid 展示的是基于相似度的ranking。
①自适应权重三重损失相较于batch-hard loss有所提升。 ②当用平方欧氏距离训练的时候,我们的loss在所有的场景中,对于离群点而言是鲁棒的。而batch-hard loss在duke 数据集上展示出了不稳定性。 ③所提的艰难身份挖掘模式是有用的。使用不同的batches,我们自适应权重的loss是既准确又稳定的。
5.4 accuracy of tracking vs. Ranking
因为越来越多的reid方法被用于MOT中,所以研究了ID测量和rank测量的关系。 在试验中,把真实的单摄像头轨迹给冻结,在训练时,使用不同时段的特征进行跨摄像头跟踪,导致了不同层次的排列准确度。 外观特征的训练使用了461个DukeMTMC-Reid样本。 跟踪的准确度在241个DukeMTMC验证序列上进行评估 Rank-1准确度在702个IDS的DukeMTMC-reid测试集和DukeMTMC 验证集上进行评估。 对于DukeMTMC-reID 测试集和DukeMTMC验证集而言,Rank-1 准确度是相关的。 具有中等rank-1性能的特征,在MTMCT任务中仍然可以表现良好。因为要比较的身份比较有限和多样化。此外,跟踪还有运动信息的帮助, MTMCT IDF1的性能随着rank1准确率的提升而有所提升。然而,达到一点后,进一步提升特征rank-1 准确率将会导致IDF1的收益递减。 过程如下: 开始时,reid模型学着分离正样本和负样本,跟踪性能随着rank-1性能的提升而线性增加。 一旦足够的相关性具有正确的符号,相关性聚类就可以通过强制执行传递性的方式来推断其余情况。因此,纠正剩余相关的符号对IDF1的影响较小。(即使在那个点之后,reid模型也会进一步将相同身份的样本和不同身份的样本分开。这些改变不影响相关性的符号,对IDF1影响很小) 窗体底端
5.5 weakness analysis
因为单摄像头和多摄像头的ID映射不同,所以需要单独分析。 在单摄像头跟踪中,当发生显著的姿态变化,显著遮挡,突然运动的时候,相关性会很弱,所以会导致低的IDR。 在多摄像头跟踪中,碎片(轨迹片段)主要是由于盲点延迟和不可预计的运动造成的。 窗体底端 具有相似外观,外观和运动相关是很弱的,导致了在跟踪时的低的身份召回率IDR。
6.Conclusion
①A new triplet loss with real-valued adaptive weights
A new hard-identity mining technique(that mixes difficult and random identities) = Appearance features(MTMCT & Re-id,考虑的指标有IDF1,MOTA,rank-1 scores)
②阐明了rank-1 re-id score的变化与IDF1跟踪准确度变化之间的关系。这两种性能的测量刚开始时是线性相关的,但是这种依赖会趋于饱和,一旦rank-1 score足够好,以致于可以产生与正确标志相关的数据关联。
解读二:
1.本文的主要贡献
1、提出一种自适应的Triplet loss方法,与固定权重的方法相比,在准确率和效率方面均有提升.2、提出一种可以更好的提取特征的难例挖掘方法3、关于tracking和ranking的准确度之间的关系,提出新的见解4、在现有数据集上分别检测MTMCT和Re-ID的有关性能
2. 多目标多相机追踪(MTMCT)和行人再识别(Re-ID)的关系
2.1 两者的区别
MTMCT是在来自多个相机的视频中追踪多个行人,在人群分析,运动员姿势识别等领域均有非常广泛的应用,它比较的是分类性能。而Re-Id是从一个图片库里检索出与查询图片相似的任务,给出一个相似程度的排序,比较的是排列性能。
2.2 两者的联系
对于MTMCT的loss而言,任何两个身份相同特征之间的最大距离都要小于任何两个不同的特征之间的最小距离,在同一种身份和不同种身份的距离就称为间隔margin。
对于Re-ID的loss而言,对于任意一张查询图片a,图片a与身份相同的特征之间的最大距离要小于图片a与身份不同的特征之间的最小距离。因此,对于任意给定的查询图片,我们可以得到正确的特征排列。
因此, 由0-MTMCT loss我们可以得到0-reid loss,但是反之不成立。
2.3 模型的流程
为了实现MTMCT的相关性能,文章设计了下列流程。
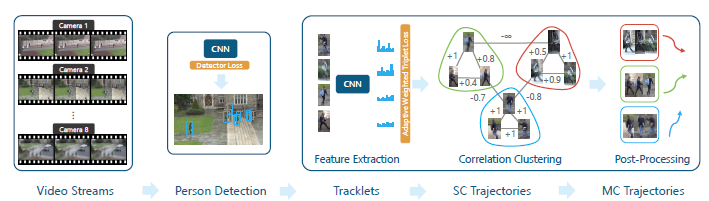
对于给定的视频流(video streams),首先用行人检测器对视频进行处理,从中提取相应的边界框Bbox。为了进行轨迹推断,特征提取器要从观测中提取运动特征和外观特征。将这些特征将转换成相关性并用相关聚类优化的方式打上标签。最后做一些后处理的工作:对缺失值进行插值处理,去除低置信度的轨迹。
3. 论文结论
我们使用了一个实值,自适应权重的triplet损失,联合能够混合困难和随机个体的新的困难个体挖掘技术,获得了外观特征。无论是使用IDF1,MOTA或者rank1分数衡量在MTMCT和Re-ID上都达到了最先进的表现。
我们的实验也说明了Re-ID的rank-1分数改变与追踪准确率的IDF1准确率改变之间的关系。这两种表现度量一开始就是线性相关的,但是一旦rank-1分数一旦足够好就会产生产生对于正确信号的关联,这种依赖就会饱和。
我们期待能够引进新的大规模数据集来进一步验证我们的想法。
来源:CVPR 2018(应该是来自知乎的某个大佬写的,侵删)