通俗浅薄的解释一下CMDB
从上述百度百科的定义来看,还是有些苦涩难懂的。我们从应用场景切入来理解CMDB,可能更加容易一些:
场景一:应用运维工程师从业务线/产品线的角度去,去查看某个业务线/产品线有多少个应用系统、哪些是核心的应用系统,这些应用系统是不是部署那些主机上,是否存在单点问题,资源是否合理分布等等。在一般的运维过程中,每个应用系统的信息都存在,但这些关键信息可能都是散乱的,比如用物理机部署的可能在某一个工具上维护,用云主机部署的却是在云平台上进行维护,给整体的分析带来了不便,使得无法从更高的业务角度来判断和分析资源情况。
场景二:在日常的运维管理中,我们需要面临很多的IT资源,有物理形态的,比如机房、机柜、网络设备、安全设备、物理服务器、SAN存储、刀箱等等;有数字形态的,比如云平台、云主机、IP、操作系统、中间件、数据库、代码等等。其中的任何一个资源出现故障,可能都会影响到业务的稳定运行,那么我们怎么来统一管理这些IT资源、怎么来理清这些资源之间的关联关系、它们之间又是如何相互影响的。
CMDB的提出就是要解决这些问题的,以提高运维的效率、甚至以达到智能运维的目的。从管理角度看,CMDB的核心就是对这些IT资源进行管理。为了进行有效的管理,CMDB有这些IT资源必要的属性信息(注意不是最完整、最全面的信息),及这些IT资源之间是如何相互关联、相互影响的关联信息。从运维角度,可以一句话来简单描述就是:
“CMDB知道一个IT资源的必要信息,也知道这个IT资源发生变动后,会影响到哪些IT资源及业务”
在CMDB中,还有两个比较费脑细胞的概念就是“模型”及“关联关系”:
- 模型:我们通过模型定义各个资源对象(可以理解为:对于这些资源对象,我们需要关注哪些信息--类似数据库中的表有哪些字段一样)。
- 关联关系:定义说明这些对象之间的关联关系,比如应用和云主机是运行关系,某某应用运行在某某云主机上,某某云主机运行了某某应用。
这就是CMDB的模型之说,文章的后面我们通过实际例子来正式说明。定义好了这些模型、关联关系后就要把这些模型实例化,类似我们往表中插入一行数据一样,这行数据有主键key、各个字段属性、各个外健等等。
下面,我们将从产品理念、产品架构、资源模型、原型设计、应用场景方面进行来说明我们如果构建一个符合多云架构、符合“双态运维”的轻量级CMDB产品。
产品理念和目标
产品理念:以应用场景为驱动,建立高效化、轻量化的运维数据枢纽。
产品目标:构建符合多云架构、符合“双态运维”的轻量级CMDB,并形成运维数据中心枢纽,该数据枢纽能够支持多种业务场景,比如资产管理、资源可视化、运维监控、自动化运维、多云管理等等。
产品框架规划设计
CMDB产品功能规划上,我们做了一个最简化的组成,即由模型管理、数据中心、资源管理、采集平台、资源可视化等组成,具体如下:
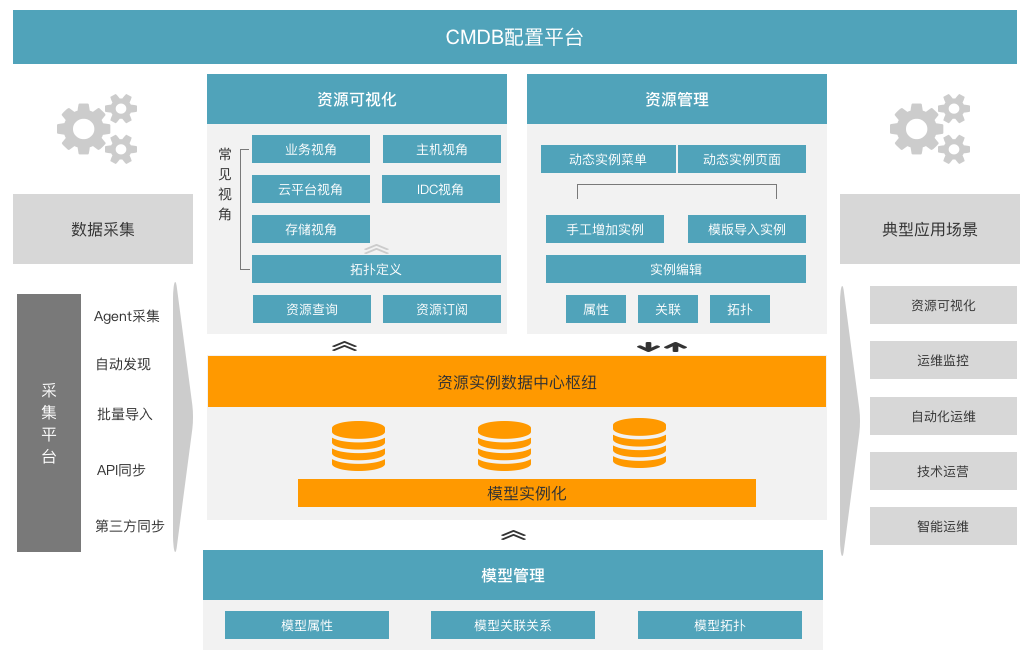
CMDB 在功能架构上由如下核心内容组成:
- 模型管理:
- 模型定义:通过模型把需要管理的IT资源进行定义,描述IT资源的各种信息属性,以便用户能快速、清楚的了解资源情况。
- 关联关系:预先定义各种关联关系(比如运行、归属、组成、属于、默认关联、使用等),然后通过这些关联关系来描述各个模型之间的相互关系,比如某某应用运行在某某主机上。
- 模型拓扑:通过拓扑图形能够直观、便捷的对模型之间的关联关系进行展现和管理。
- 资源实例数据中心:
- 创建模型:根据模型定义,创建资源模型。如果数据中心建立在Mysql上,表现为创建Table;如果数据中心建立在MongoDB上,表现为创建collection。
- 存储数据:存储采集平台从各个地方采集过来的数据; 存储资源管理模块手工录入或者模板导入的数据。
- 资源管理
- 资源实例录入和编辑:提供一个可视化的界面,用户可以对资源实例的属性、关联关系进行增加、编辑和删除等。
- 资源可视化
- 资源查询,提供界面可以快速查找各种IT资源。
- 常见视图:从应用运维工程师角度(含业务系统客户),构建了业务视角;从云平台运维工程师角度,构建了云平台视角;从IDC运维工程师角度,构建了IDC视角;从存储工程师角度,构建了存储视角。
- 视角拓扑定义:可以从其他工作角色来自定义新的视图。
- 采集平台
- Agent : 通过在资源端安装Agent ,实时或者定时采集数据。
- 自动发现:通过规则自动发现模型之间的关联关系或补齐修改资源属性。
- 批量导入:支持数据的大批量导入。
- API同步:提供接口,让外部系统能够实时把资源属性进行更新。
- 第三方同步:比如通过ETL工具,从其他数据库同步。
当CMDB构建好后,就可以向各种应用场景提供服务,比如资源可视化、运维监控、自动化运维、技术运营、智能运维等等。
核心流程规划设计
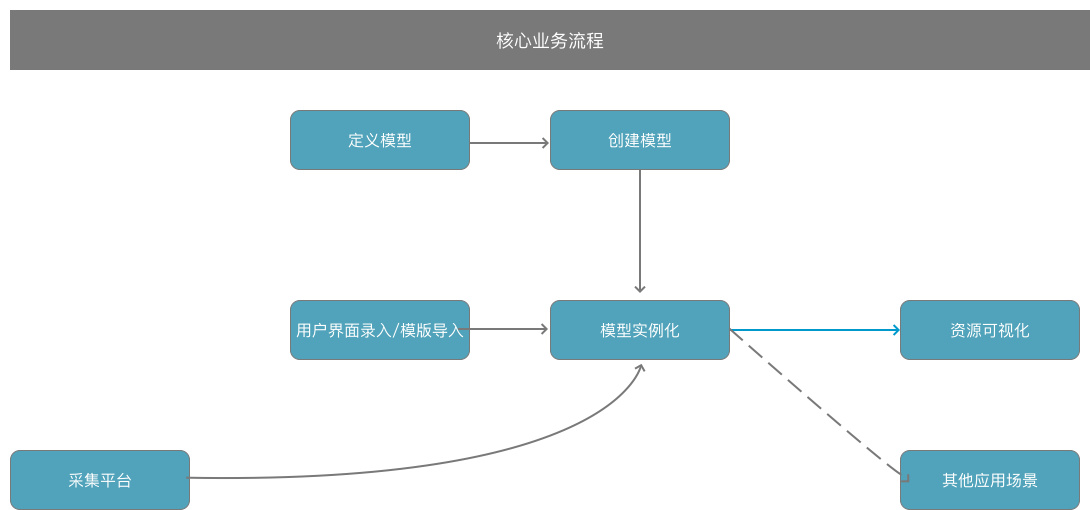
从业务操作流程来看其实并不复杂:
- 模型管理模块定义好模型
- 数据中心根据定义,创建模型。
- 从过手工录入或者自动采集实例化资源。
- 通过数据中心构建各种可视化应用,包括资源查阅、资源拓扑展现、运维大屏之类的可视化应用。
- 通过数据中心提供其他应用。
模型规划设计(核心部分)
传统CMDB模型的缺点
在传统CMDB项目的实施过程中,大家都是看了仿佛都是各种各样的模型、五花八门的配置项目,然后,项目工作都落入定义各种配置项中去,笔者了解到之前的CMDB项目中也s落入这个陷阱而导致项目失败。虽然我们看到项目过于关注模型而导致失败,但是也从侧面说明了模型的重要性。开发一套CMDB系统并不是一件困难的事,但是用好一个CMDB系统却是一件困难的事。如何用好CMDB系统,规划设计一套可用的CMDB模型是一个关键。那么,我们又应该如何规划CMDB模型才能满足我们的产品目标呢?
在如何规划设计CMDB模型前,我们先先说说传统的CMDB模型,传统的CMDB基本都是由国外的大厂家开发的,产品围绕数据中心以基础资源管理为主,模型配置项也极其繁杂,比如明细到了某个插座的型号、位置之类的,似乎要穷举所有资源的所有属性才摆休。传统CMDB常常需要运维人员进行各种配置项后才能使用,即没有一个可以开箱即用的模型,这个配置的过程基本把运维人员挡在系统门外,最后,肯定是不如Excel来得方便。另外是过分依赖人工维护,缺少自动化发现及自动采集功能,数据维护工作量巨大,系统投入产出比严重失调,最后也是不了了之。对于敏态运维DevOps的支持,更是无从谈起。
新一代CMDB模型的出发点
为此,在规划设计CMDB模型时,我们可以如下几点出发
- 要从业务应用角度出发,不能从IDC的资源管理出发,毕竟所以的IT资源归根到底都是为业务服务的。
- 至少要存在一套可以开箱使用的模型,不能只是提供一个工具的平台,而把难题丢给了用户。谨记“开发一套CMDB系统并不是一件困难的事,但是用好一个CMDB系统却是一件困难的事”
- 模型属性尽量精简化,只需要必要属性信息,而不是穷举所有属性信息。
- 人工维护是必要的,但是能够系统自动化就要系统自动化,手工录入是一个迫不得已的手段。
- 要场景应用为驱动,反推和检验模型。
- 模型要考虑多云架构、考虑内外部资源
- 模型是为了管理,不能为了模型而模型,不能因为各种配置项、各种配置属性,而把精力放在库表的设计和管理上。
一个开箱即用的CMDB模型
如下是笔者为了满足多云架构及“双态运维”初步规划的CMDB模型规划:

当然,笔者只是做一个开箱即用的简要模型,但可以满足80%以上的运维管理要求。
常见的关联关系
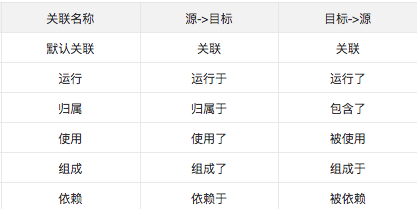
比如,应用和云主机是运行关系,某某应用运行于某某云主机上,某某云主机运行了某某应用,其中应用是源、主机是目标。
如何定义模型属性
重复一句:“尽量精简化,只需要必要属性信息,而不是穷举所有属性信息。”
如何定义模型关联关系
建立源与目标的概念,任何一个对象在不同关联关系中都不同的定位。下面以云主机为例,
- 云主机与云平台是归属关系,云主机是源,云平台是目标。
- 云主机与应用是运行关系,云主机却是目标,应用却是源。
如下图:
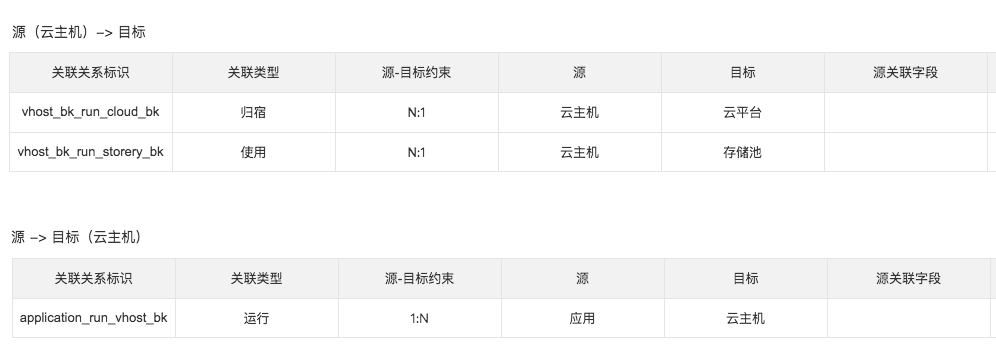
当然,我们也可以通过拓扑方式更加直观来管理这些关联关系:
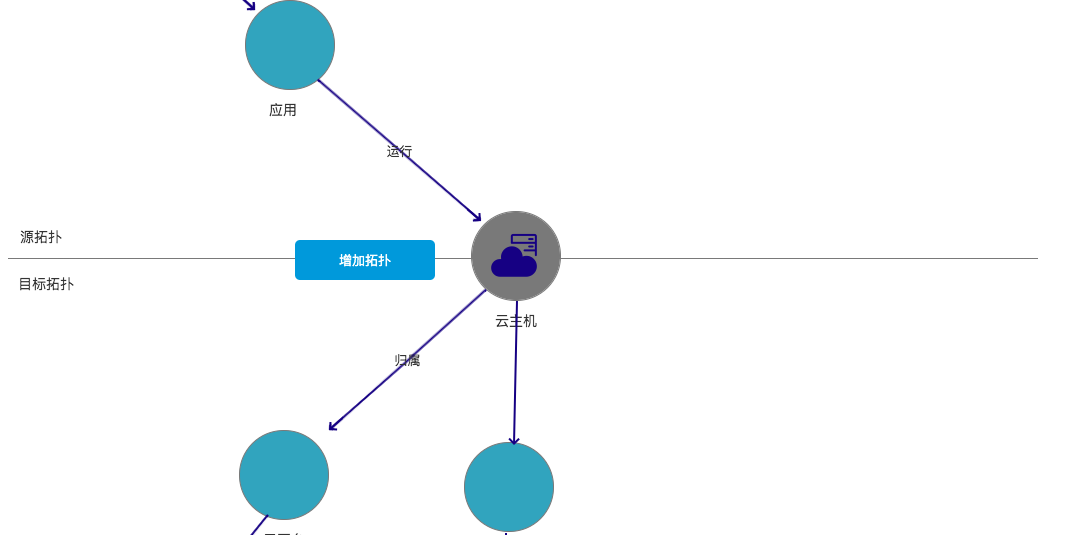
确定好有哪些模型,如何定义这些模型及模型之间的关联关系,那么模型工作基本就可以告一段落了。接下来就是如何根据定义实例化这些模型。
实例化模型有些需要注意的地方
实例化数据库的选择
传统的CMDB是基于关系型数据库实现的,使得整个库表架构极其复杂,可读性极差,对外接口更是复杂了。新一代CMDB利用MongoDB这非结构化数据库能够更加适合CMDB的建模,推荐的做法是:
- 利用Mysql等关系型数据库,存储模型的定义。
- 利用MongoDB等NOSQL文档存储数据库,以json的格式存储资源实例。
实例和视图分开
CMDB数据中心同时事务数据库及数据仓库的功能,为了能够满足数据实时更新的同时,也要满足各种运维的监控及分析。因此,建议分成实例库和视图库:
尽量减少人工录入
手工录入是一个迫不得已的手段,能够采集就自动采集,能够自定发现的就自动发现。
常见资源可视化视角需求
实现核心模型,即业务、应用和主机Host的关系。运维人员可以
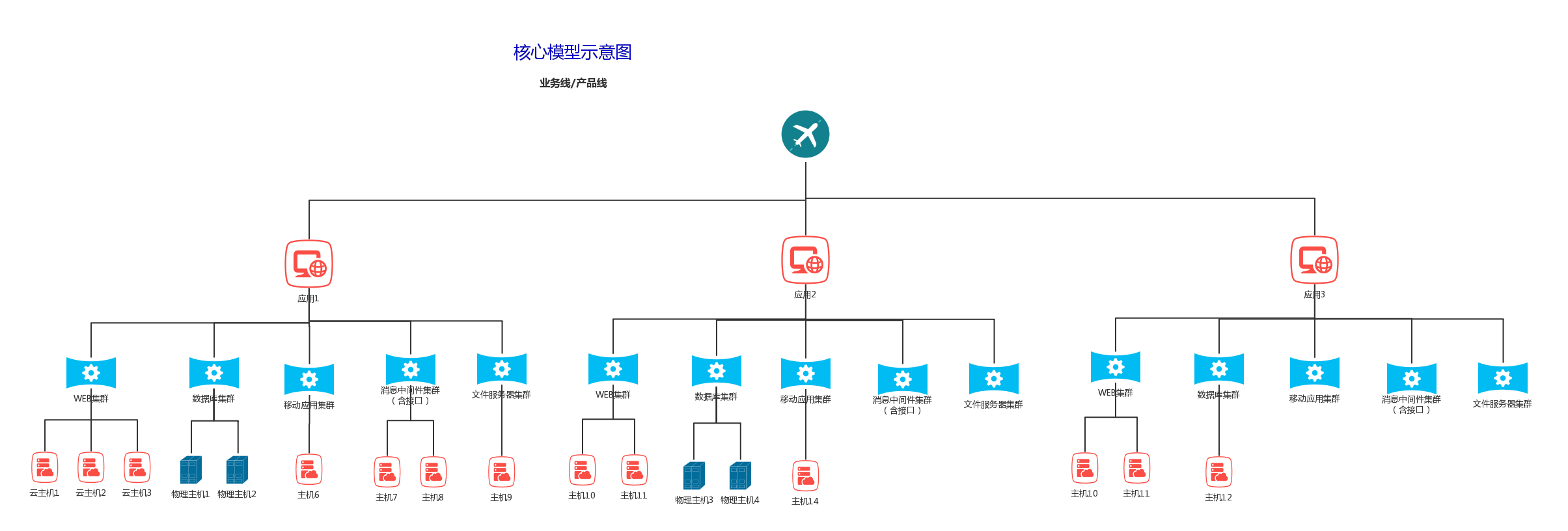
从云主机host 为起点向拓展云平台、宿主机、网络设备、存储等。
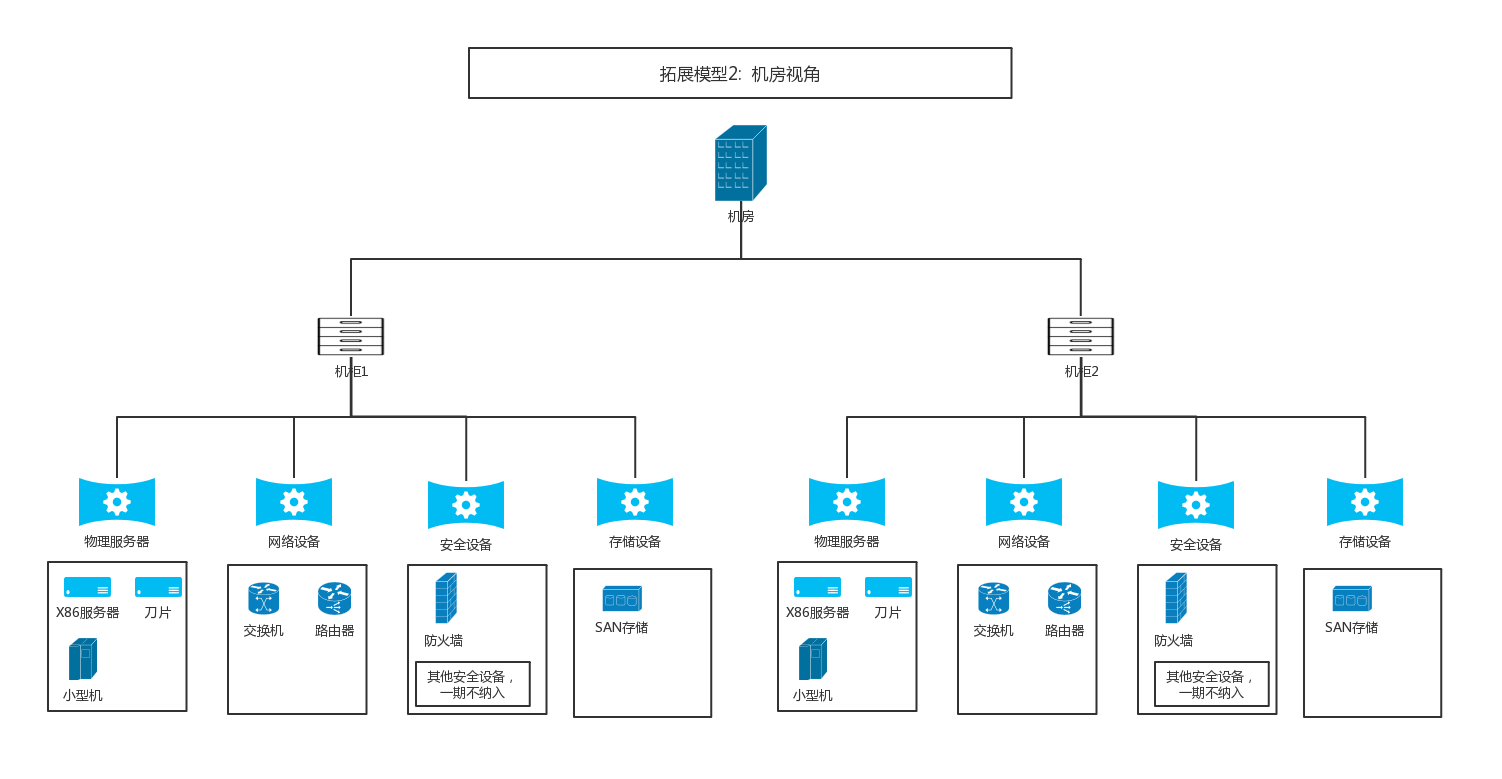
扩展模型3,以机房为起点拓展机柜、网络设备、安全设备、物理主机、存储设备、云平台。
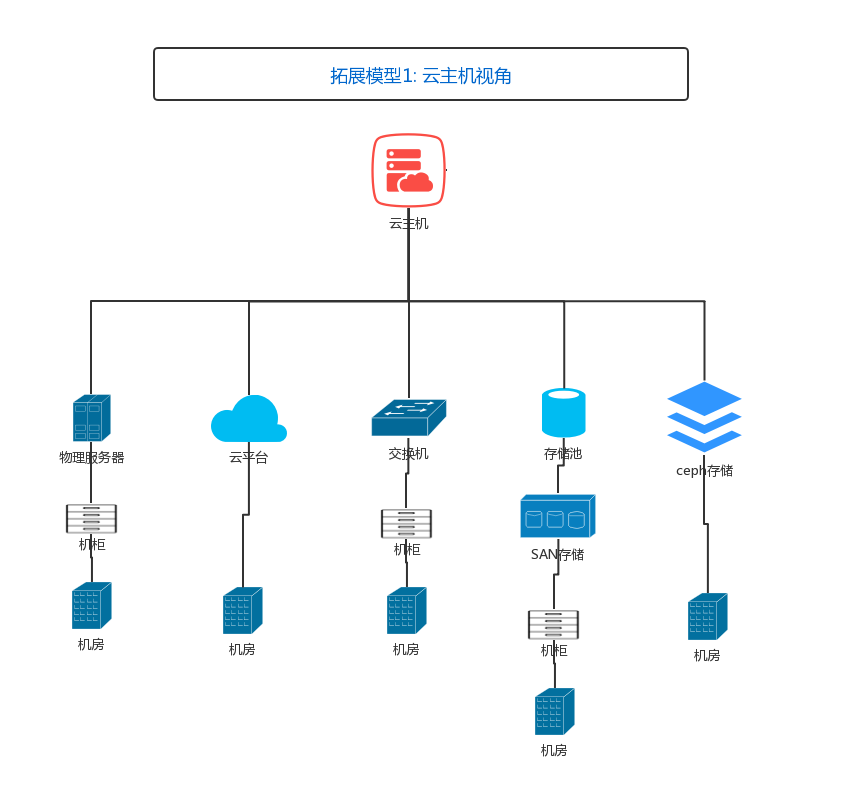
以云平台为起点拓展机柜、机房、网络设备、存储设备、物理主机。
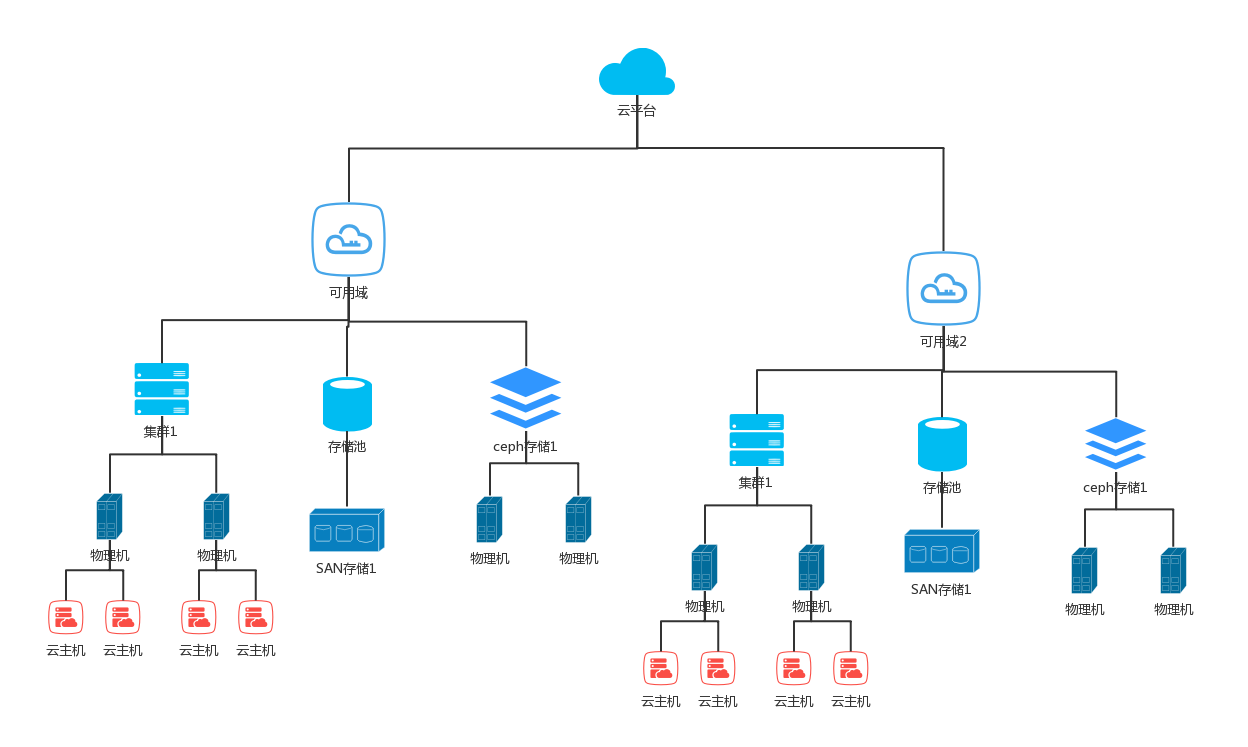
通过不同的视图可以满足不同用户对资源整体管控。
总结
一句话:开发一套CMDB系统并不是一件困难的事,但是用好一个CMDB系统却是一件困难的事。
作者:老格,擅长产品规划和设计,擅长解决方案,擅长PPT制作,是一个懂技术的产品PM,会设计的售前咨询。