摘要:
平行坐标通常用于可视化高维几何和分析多变量数据。要在n维空间中显示一组点,请绘制一个由n条平行线组成的背景,这些平行线通常垂直且等距。点N维空间表示为平行于多段线和顶点的轴;顶点在第i个轴上的位置对应于点的第i个坐标。这种可视化与时间序列的可视化密切相关,只是它应用于轴与时间点不对应的数据,因此没有自然顺序。此多段线是根据属性的索引值和属性值绘制的。
平行坐标是可视化高维几何和分析多元数据的常用方法。
为了在n维空间中显示一组点,绘制由n条平行线组成的背景,通常是垂直且等距的。所述的点N 维空间被表示为折线与顶点在平行的轴线; 第i 轴上顶点的位置对应于该点的第i个坐标。
此可视化与时间序列可视化密切相关,除了它应用于轴与时间点不对应的数据,因此没有自然顺序。因此,不同的轴布置可能是有意义的。
一、平行坐标图
平行坐标图(parallel coordinates plot)是对于具有多个属性问题的一种可视化方法,下图为平行坐标图的基本样式,数据集的一行数据在平行坐标图中用一条折线表示,纵向是属性值,横向是属性类别(用索引表示),如下图,一条数据[1 3 2 4]对应图中的折线。这条折线是根据属性的索引值和属性值画出来的。
二、平行坐标图的解读
首先我们用不同的颜色来标识不同的标签,那么关于属性与标签之间的关系,我们可以从图中获得哪些信息?
(1)折线走势“陡峭”与“低谷”只是表示在该属性上属性值的变化范围的大小,对于标签分类不具有决定意义,但是“陡峭“的属性上属性值间距较大,视觉上更容易区分出不同的标签类别
(2)标签的分类主要看相同颜色的折线是否集中,若在某个属性上相同颜色折线较为集中,不同颜色有一定的间距,则说明该属性对于预测标签类别有较大的帮助
(3)若某个属性上线条混乱,颜色混杂,则较大可能该属性对于标签类别判定没有价值
————————————————
版权声明:本文为CSDN博主「x-dusk」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wyfcode/article/details/82587440
python数据可视化代码和案列
import matplotlib.pyplot as plt
import pandas as pd
from pandas.tools.plotting import parallel_coordinates
data = pd.read_csv('E:/ProgramData/Anaconda3/pkgs/pandas-0.23.0-py36h830ac7b_0/Lib/site-packages/pandas/tests/data/iris.csv')
data_1 =data[['Name','SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth']]
parallel_coordinates(data_1,'Name')
plt.legend(loc='upper center', bbox_to_anchor=(0.5,-0.1),ncol=3,fancybox=True,shadow=True)
plt.show()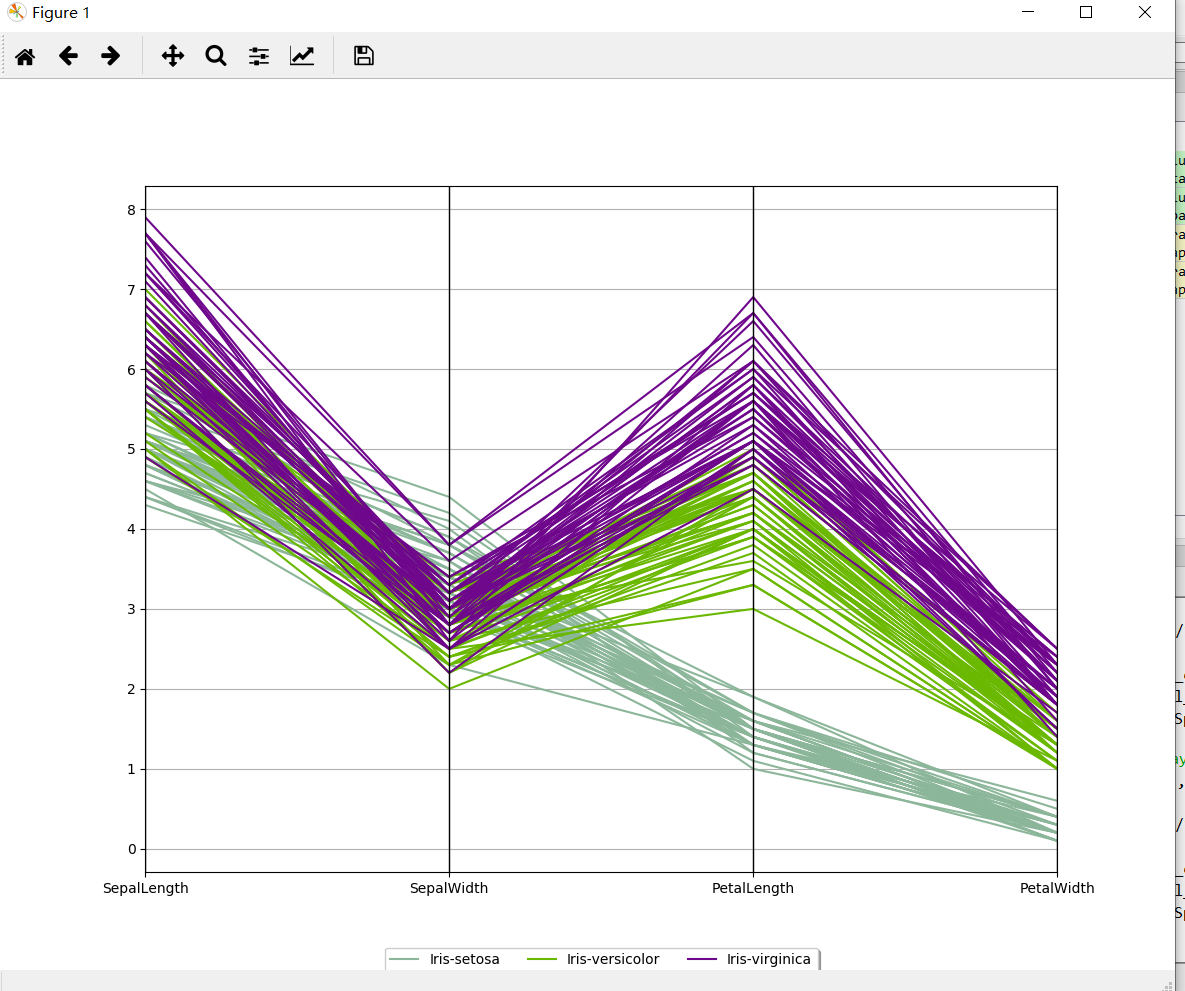

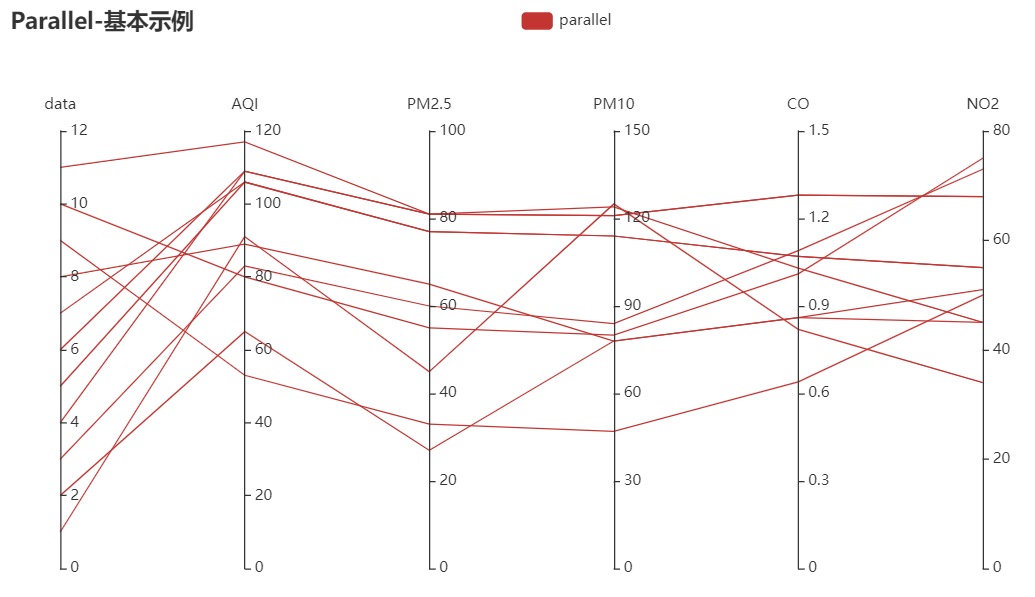
from pyecharts import options as opts from pyecharts.charts import Page, Parallel data = [ [1, 91, 45, 125, 0.82, 34], [2, 65, 27, 78, 0.86, 45], [3, 83, 60, 84, 1.09, 73], [4, 109, 81, 121, 1.28, 68], [5, 106, 77, 114, 1.07, 55], [6, 109, 81, 121, 1.28, 68], [7, 106, 77, 114, 1.07, 55], [8, 89, 65, 78, 0.86, 51, 26], [9, 53, 33, 47, 0.64, 50, 17], [10, 80, 55, 80, 1.01, 75, 24], [11, 117, 81, 124, 1.03, 45], ] c = ( Parallel() .add_schema( [ {"dim": 0, "name": "data"}, {"dim": 1, "name": "AQI"}, {"dim": 2, "name": "PM2.5"}, {"dim": 3, "name": "PM10"}, {"dim": 4, "name": "CO"}, {"dim": 5, "name": "NO2"}, ] ) .add("parallel", data) .set_global_opts(title_opts=opts.TitleOpts(title="Parallel-基本示例")) ) c.render("平行坐标系图1.html")
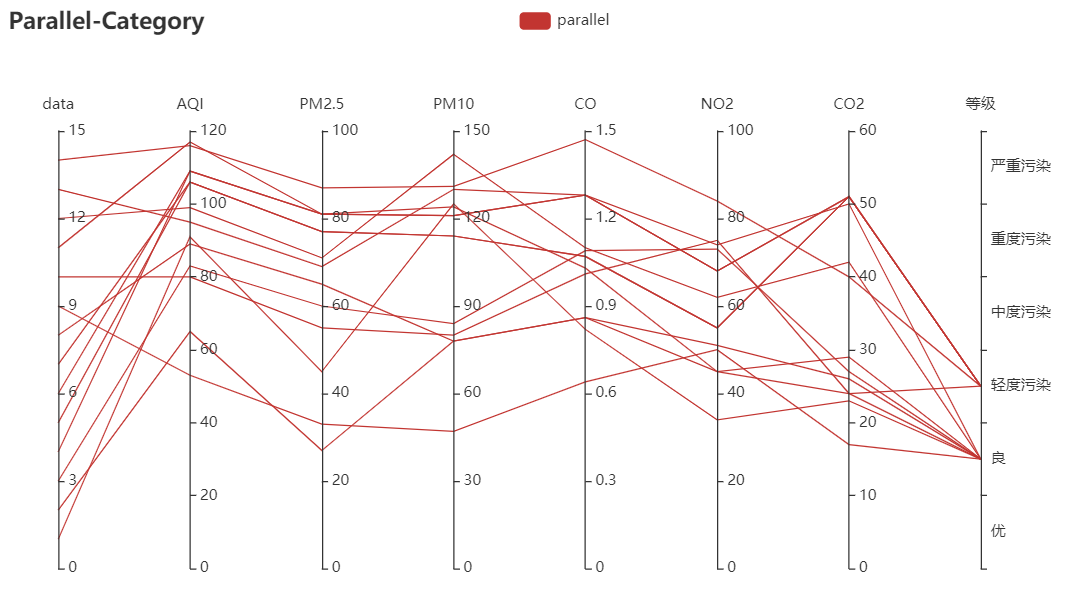
from pyecharts import options as opts from pyecharts.charts import Page, Parallel data = [ [1, 91, 45, 125, 0.82, 34, 23, "良"], [2, 65, 27, 78, 0.86, 45, 29, "良"], [3, 83, 60, 84, 1.09, 73, 27, "良"], [4, 109, 81, 121, 1.28, 68, 51, "轻度污染"], [5, 106, 77, 114, 1.07, 55, 51, "轻度污染"], [6, 109, 81, 121, 1.28, 68, 51, "轻度污染"], [7, 106, 77, 114, 1.07, 55, 51, "轻度污染"], [8, 89, 65, 78, 0.86, 51, 26, "良"], [9, 53, 33, 47, 0.64, 50, 17, "良"], [10, 80, 55, 80, 1.01, 75, 24, "良"], [11, 117, 81, 124, 1.03, 45, 24, "轻度污染"], [12, 99, 71, 142, 1.1, 62, 42, "良"], [13, 95, 69, 130, 1.28, 74, 50, "良"], [14, 116, 87, 131, 1.47, 84, 40, "轻度污染"], ] c = ( Parallel() .add_schema( [ opts.ParallelAxisOpts(dim=0, name="data"), opts.ParallelAxisOpts(dim=1, name="AQI"), opts.ParallelAxisOpts(dim=2, name="PM2.5"), opts.ParallelAxisOpts(dim=3, name="PM10"), opts.ParallelAxisOpts(dim=4, name="CO"), opts.ParallelAxisOpts(dim=5, name="NO2"), opts.ParallelAxisOpts(dim=6, name="CO2"), opts.ParallelAxisOpts( dim=7, name="等级", type_="category", data=["优", "良", "轻度污染", "中度污染", "重度污染", "严重污染"], ), ] ) .add("parallel", data) .set_global_opts(title_opts=opts.TitleOpts(title="Parallel-Category")) ) c.render("平行坐标系图2.html")
pyecharts画图更多请查看官方文档: