Hadoop基础-网络拓扑机架感知及其实现
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.网络拓扑结构
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率,即带宽稀缺。这里的想法是将两个节点之间的带宽作为距离的衡量标准。不用衡量节点之间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中两两节点对数量是节点数量的平方),hadoop为此采用了一个简单的方法:把网络看作一棵树,两个节点之间的距离是他们到最近共同祖先的距离总和。该树中的层次是没有预先设定的, 但是相对与数据中心,机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个常见,可用带宽依次递减:
1>.同一节点上的进程;
2>.同一机架上的不同节点;
3>.同一数据中心中不同机架上的节点;
4>.不同数据中心的节点‘
举个例子,假设有数据中心d1,机架r1中的节点n1。该节点可以表示为“/d1/r1/n1”。利用这种标记,这里给出四种距离描述:
1>.distance(/d1/r1/n1,/d1/r1/n1)=0(同一节点上的进程);
2>.distance(/d1/r1/n1,/d1/r1/n2)=2(同一机架上的不同节点);
3>.distance(/d1/r1/n1,/d1/r2/n3)=4(同一数据中心中不同机架上的节点);
4>.distance(/d1/r1/n1,/d2/r3/n4)=6(不同数据中心中的节点);
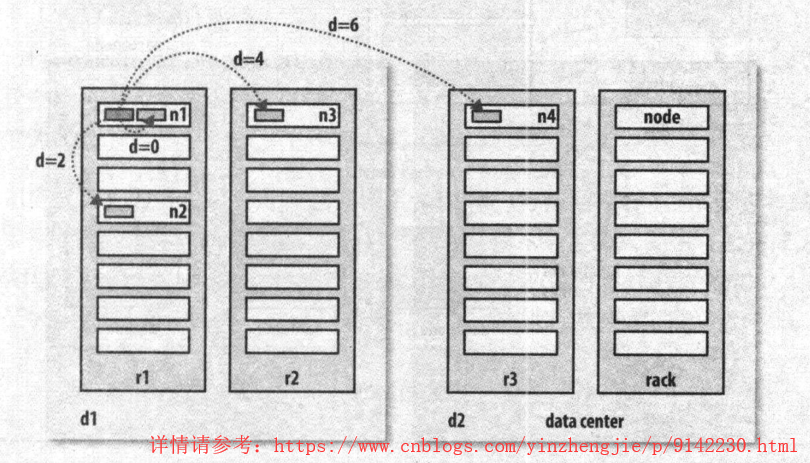
上图摘自《Hadoop权威指南第四版》。我们必须要意识到Hadoop无法自动发现你的网络拓扑结构。它需要一些帮助,不过在默认情况下,假设网络是扁平化的只有一层,换句话说,所有节点在同一数据中心的同一机架上。规模小的集群可能如此,不需要进一步配置。
二.机架感知
机架感知可以通过python和shell实现,详情请参考官方文档的案例:http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html。由于Hadoop是Java语言写的,因此本篇博客主要使用Java代码实现机架感知。在机架感知中,接受的数据(参数)是一个包含所有节点的ip或主机名的List,返回的数据也是一个List,是拓扑距离的list。
1>.编写机架感知自定义逻辑代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hdfs; 7 8 import org.apache.hadoop.net.DNSToSwitchMapping; 9 import java.util.ArrayList; 10 import java.util.List; 11 /** 12 *hadoop副本放置策略:(3副本情况) 13 * 1、在本地机架的一个节点放置一个副本 s101-s103 rack1 14 * 2、在其他机架的两个结点放置两个副本 s104-s105 rack2 15 */ 16 public class RackAware implements DNSToSwitchMapping { 17 public List<String> resolve(List<String> names) { 18 List<String> list = new ArrayList<String>(); 19 for(String name : names){ 20 Integer suffix = 0; 21 /** 22 * 第一种情况: names是主机名 23 */ 24 if(name.startsWith("s")){ 25 //将s101变为101 26 suffix = Integer.parseInt(name.substring(1)); 27 } 28 /** 29 * 第二种情况:names是ip 30 */ 31 else { 32 suffix = Integer.parseInt(name.substring(name.lastIndexOf(".") + 1)); 33 } 34 /** 35 * 我们的策略是主机位大于103的就放在第一个机会上,即"/rack1",否则就放在第二个机柜上上,即"/rack2" 36 */ 37 if(suffix <= 103){ 38 // /rack1/s102 39 list.add("/rack1"); 40 } 41 else { 42 // /rack2/s105 43 list.add("/rack2"); 44 } 45 } 46 return list; 47 } 48 /** 49 * 下面的两个方法空实现即可。不用搭理它们,咱们这里用不到他们两个方法 50 */ 51 public void reloadCachedMappings() {} 52 public void reloadCachedMappings(List<String> names) {} 53 }
2>.打包并上传至服务器端的/soft/hadoop/share/hadoop/common/lib目录下

3>.修改配置文件
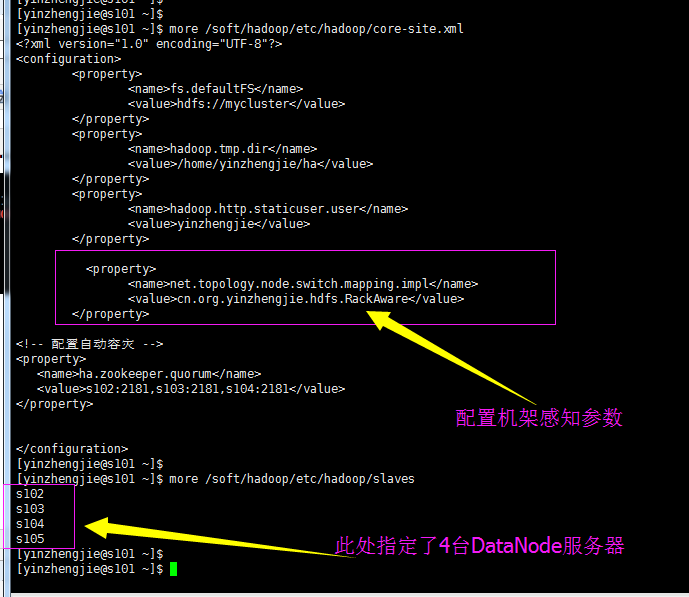
4>.分发配置文件
[yinzhengjie@s101 ~]$ more `which xrsync.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #获取文件路径 file=$@ #获取子路径 filename=`basename $file` #获取父路径 dirpath=`dirname $file` #获取完整路径 cd $dirpath fullpath=`pwd -P` #同步文件到DataNode for (( i=102;i<=105;i++ )) do #使终端变绿色 tput setaf 2 echo =========== s$i %file =========== #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 rsync -lr $filename `whoami`@s$i:$fullpath #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/etc/hadoop/core-site.xml =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 =========== s105 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/etc/hadoop/slaves =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 =========== s105 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/share/hadoop/common/lib/MyHbase-1.0-SNAPSHOT.jar =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 =========== s105 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$
5>.启动HDFS并查看NameNode日志
