摘要:
1. Hadoop集群介绍1.Hadoop集群介绍Hadoop集群部署,就是以Clustermode方式进行部署。
Hadoop集群部署,就是以Cluster mode方式进行部署。
Hadoop的节点构成如下:
HDFS daemon: NameNode, SecondaryNameNode, DataNode
YARN damones: ResourceManager, NodeManager, WebAppProxy
MapReduce Job History Server
2. 集群部署本次测试的分布式环境为:Master 1台 (test166),Slave 1台(test167)
2.1 首先在各节点上安装Hadoop
安装方法参照Hadoop系列之(一):Hadoop单机部署
2.2 在各节点上设置主机名
# cat /etc/hosts 10.86.255.166 test166 10.86.255.167 test167
2.3 在各节点上设置SSH无密码登录
2.4 设置Hadoop的环境变量
# vi /etc/profile export HADOOP_HOME=/usr/local/hadoop-2.7.0 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/Hadoop
让设置生效
# source /etc/profile
2.5 Hadoop设定
2.5.1 在Master节点的设定文件中指定Slave节点
# vi etc/hadoop/slaves test167
2.5.2 Master,Slave所有节点共同设定
# vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://test166:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.0/tmp</value>
</property>
</configuration>
# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.5.3 在各节点指定HDFS文件存储的位置(默认是/tmp)
Master节点: namenode
创建目录并赋予权限
# mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/name # chmod -R 777 /usr/local/hadoop-2.7.0/tmp
# vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop-2.7.0/tmp/dfs/name</value>
</property>Slave节点:datanode
创建目录并赋予权限
# mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/data # chmod -R 777 /usr/local/hadoop-2.7.0/tmp
# vi etc/hadoop/hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop-2.7.0/tmp/dfs/data</value>
</property>2.5.4 YARN设定
Master节点: resourcemanager
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>test166</value>
</property>
</configuration>
Slave节点: nodemanager
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>test166</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>2.5.5 Master上启动job history server,Slave节点上指定
Slave节点:
# vi etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>test166:10020</value>
</property>2.5.6 格式化HDFS(Master,Slave)
# hadoop namenode -format
2.5.7 在Master上启动daemon,Slave上的服务会一起启动
启动HDFS
# sbin/start-dfs.sh

启动YARN
# sbin/start-yarn.sh

启动job history server
# sbin/mr-jobhistory-daemon.sh start historyserver
确认
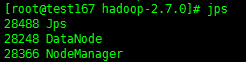
Master节点:
# jps

Slave节点:
# jps
2.5.8 创建HDFS
# hdfs dfs -mkdir /user # hdfs dfs -mkdir /user/test22
2.5.9 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop /user/test22/input
查看
# hdfs dfs -ls /user/test22/input
2.5.10 执行hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test22/input output 'dfs[a-z.]+'
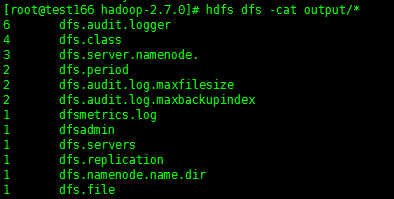
确认执行结果
# hdfs dfs -cat output/*
本次集群部署主要是为了测试验证,生产环境中的HA,安全等设定,接下来会进行介绍。