摘要:
1、 重塑一揽子数据:氮肥和磷肥用量对植物生长的影响。将上述数据转换为txt文件1.melt()函数,将宽数据转换为长数据,转换为NP数据集2.dcast()函数。将长数据转换为宽数据。Tidyr包处理整洁的数据:每列代表一个变量。每行表示一个与观察值相对应的变量。1.宽数据变成长数据。2.长数据变成宽数据。3 Dplyer包1.filter()函数,拦截合格数据2.distinct()
一、reshape2包
数据:氮肥和磷肥的用量对植物生长的影响
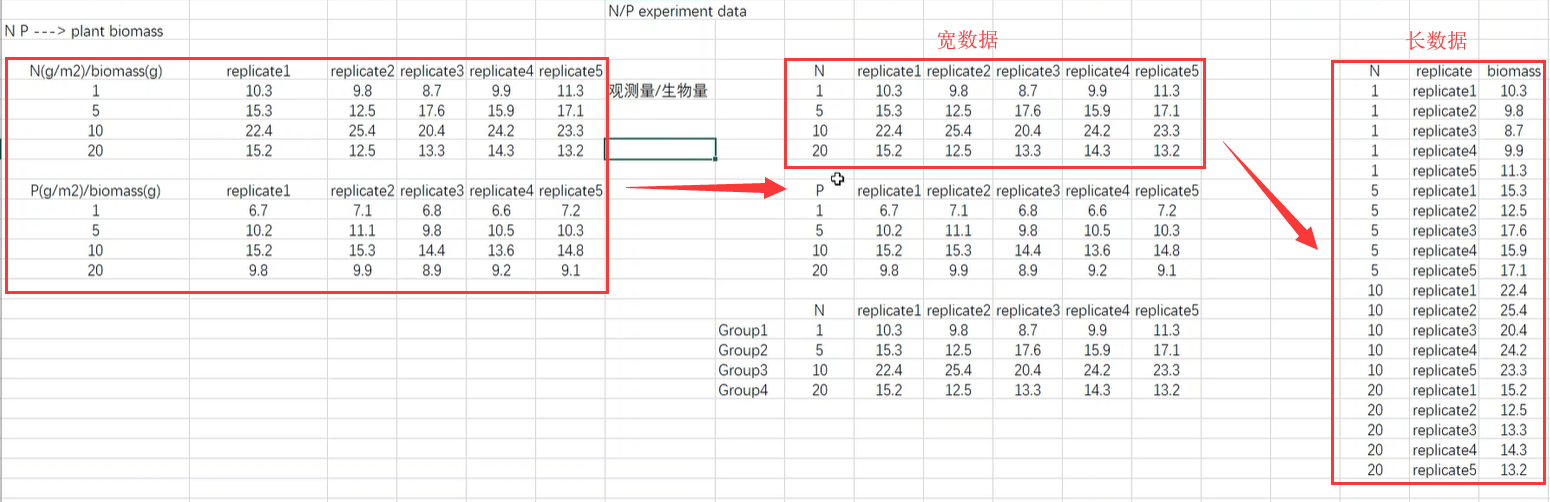
将上图数据做成txt文件


1.melt() 函数,将宽数据转换为长数据

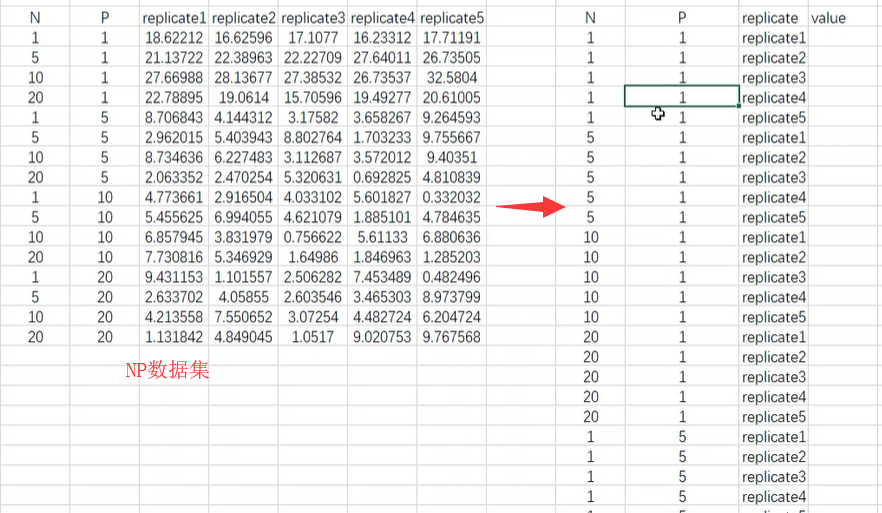
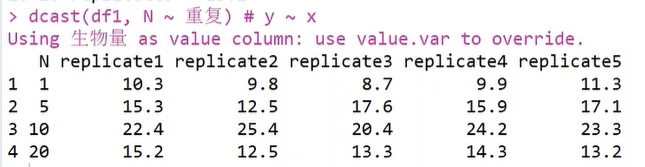
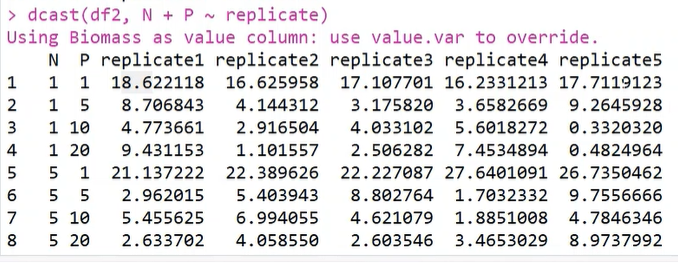
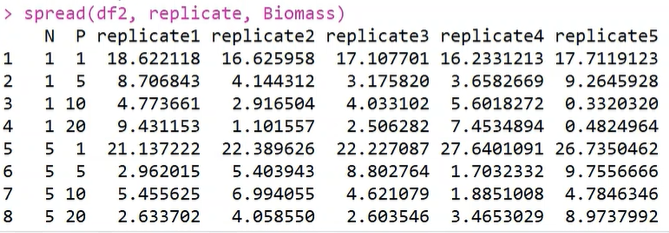
转换NP数据集
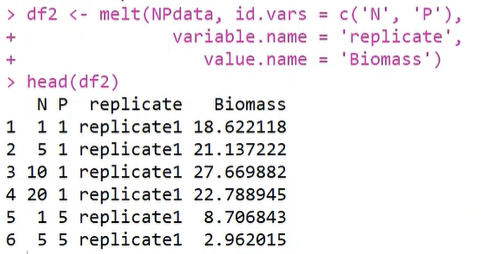
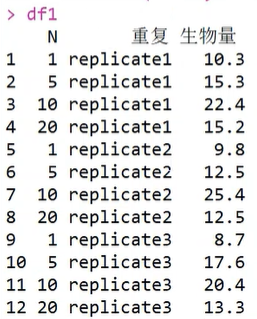
2.dcast() 函数,将长数据转换为宽数据
二、tidyr包
处理整洁的数据:
每一列代表一个变量
每一行代表一个观测
一个观测值对应的一个变量
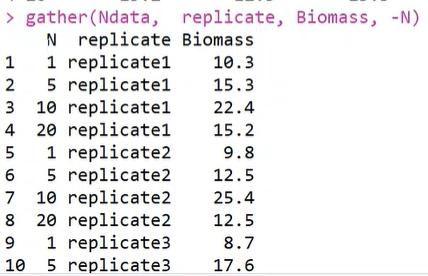
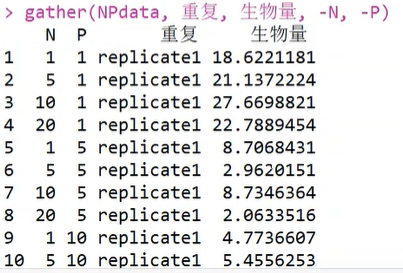
1.宽数据变为长数据
2.长数据变为宽数据

三、dplyr包
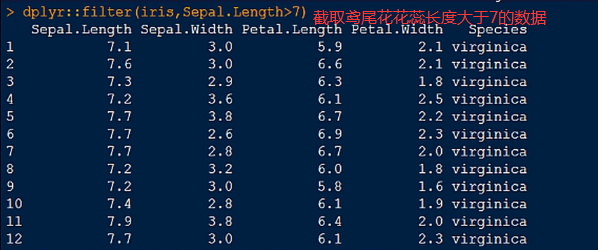
1.filter() 函数,截取满足条件的数据
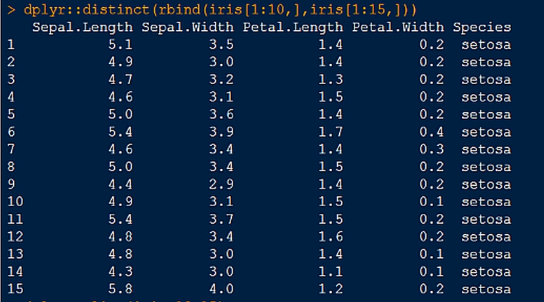
2.distinct() 函数,用于去除重复行
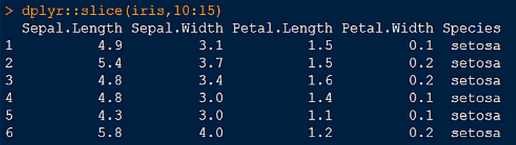
3.slice() 函数,用于切出任意行
4.sample_n() 函数,随机取样
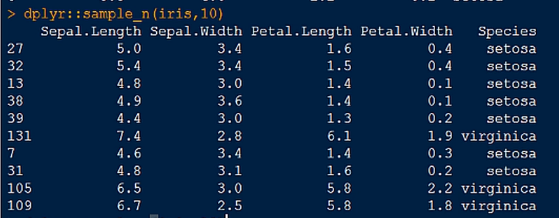
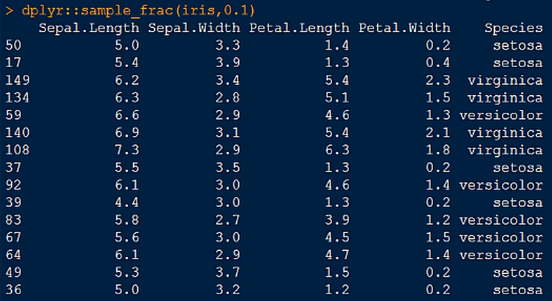
5.sample_frac() 函数,按比例随机抽样
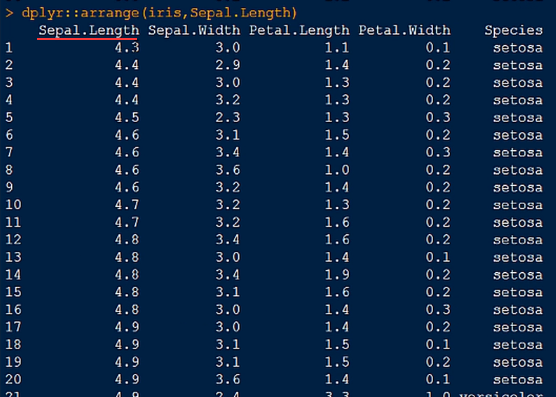
6.arrange() 函数,对某一指标进行排序
倒序
dplyr::arrange(iris,desc(Sepal.length))
7.select() 函数,对数据取子集
8.summarise() 函数,对数据进行统计

链式操作符 %>%
用于实现将一个函数的输出传递给下一个函数,作为下一个函数的输入
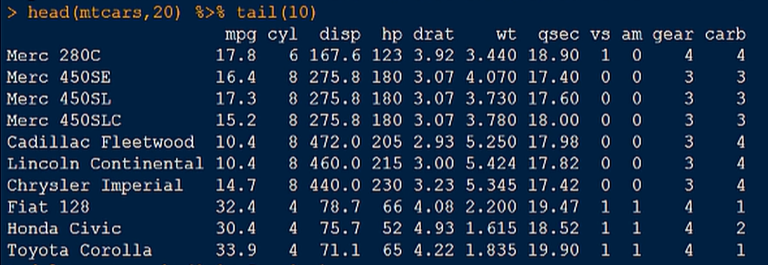
1.取出mtcars数据集的11-20行
2.对鸢尾花数据集的特征进行分组
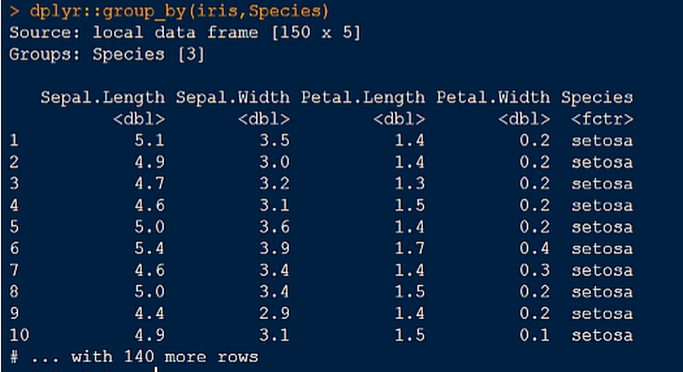
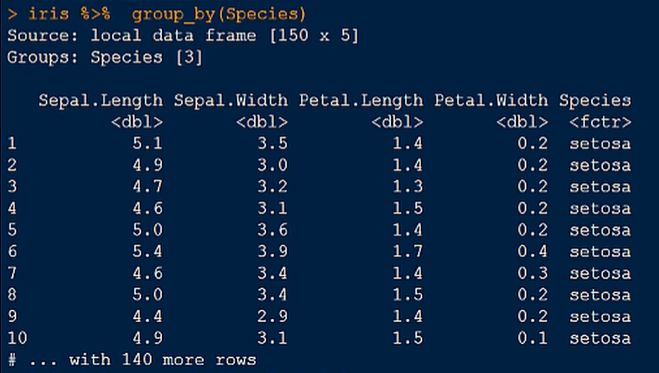
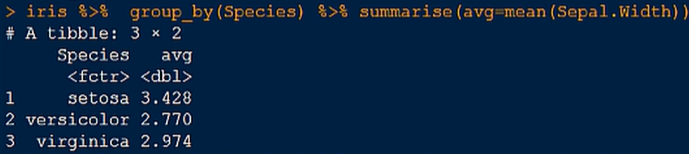
3.对鸢尾花数据集特征的花萼宽度进行分组统计
4.mutate() 函数,添加新的一列(花萼和花瓣长度的总和)
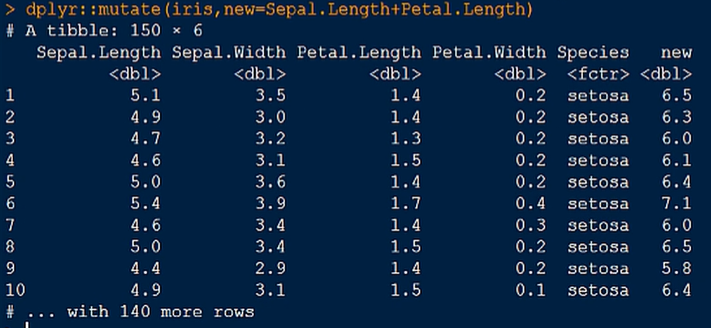
对表格进行整合
两个数据表
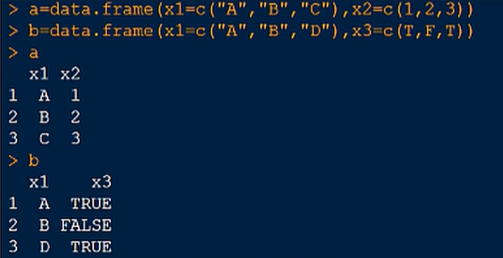
1.左连接(以左边的表为基础)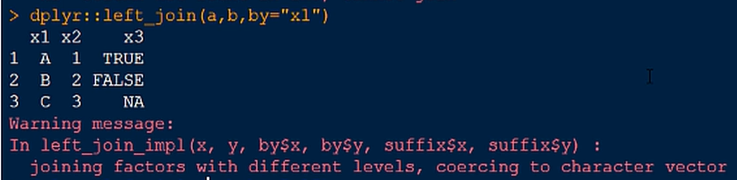
2.右连接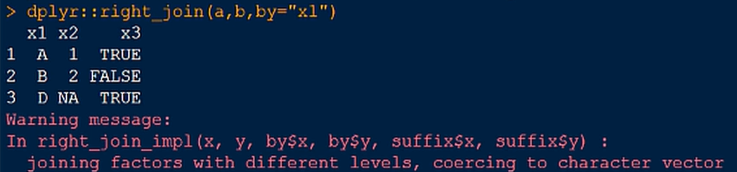
3.全连接(并集)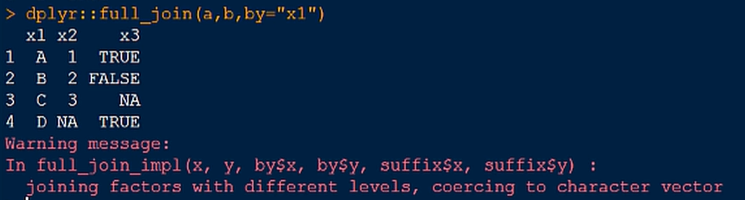
4.半连接(取出交集)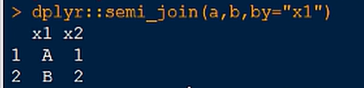
5.反连接(取出补集)
对 mtcars 进行数据集合操作
#添加一个名字列
mtcars <- mutate(mtcars,Model = rownames(mtcars))
#截取两个数据集1-20条和10-30条
first <- slice(mtcars,1:20)
second <- slice(mtcars,10:30)
#取两者交集
intersect(first,second)
#取并集
dplyr::union_all(first,second)
#取非冗余的并集
dplyr::union(first,second)
#取 first 的补集
setdiff(first,second)
#取 second 的补集
setdiff(second,first)