- STL是什么
- OOP与GP
- Malloc
- STL中共有几种类型的迭代器
- 随机访问意味着内存连续吗
- 逆向迭代器rbegin是否等于end
- 类型萃取
- std::remove_if,std::find_if,std::find和std::find_if的区别是什么
- 头文件algorithm中有哪些好用的算法
- std::distance,求迭代器间的距离
- std::search,搜寻子序列
- std::find_end,std::find_first_of
- std::all_of,std::any_of,std::none_of
- std::count,查目标元素在序列中出现的次数
- std::next,std::prev,返回移动n位后的迭代器
- std::copy,从源序列拷贝到目标序列
- std::move,从源序列移动到目标序列
- std::transform,对1-2个序列进行变换,结果存入新序列
- std::replace,对源序列元素进行替换
- std::fill,对源序列进行批量赋值
- std::generate,调用Generator来产生序列
- std::unique,将相邻且相同的值移到结尾
- std::reverse,倒置一个序列
- std::rotate,进行元素范围上的旋转
- std::shuffle
- std::accumulate,std::reduce:求数列的“和”
- 二分查找,针对有序序列的查找
- std::merge,合并操作 对有序序列
- std::set_xxx,集合运算
- sort系列
- initializer_list相关问题
- vector相关问题
- List相关问题
- deque相关问题
- map,set等关联式容器相关问题
- 一句话系列
standard-template-libary,标准模板库。
算法库,容器库,函数对象库,迭代器库,智能指针库等都属于STL
OOP与GP在C++标准中,STL被组织为下面的13个头文件:<algorithm>、<deque>、<functional>、<iterator>、<vector>、<list>、<map>、<memory>、<numeric>、<queue>、<set>、<stack>和<utility>。
我认为type_traits也是STL当中重要的一部分

全局sort中使用的迭代器指针是要求支持随机访问的(RandomAccessIterator),也就是说该泛型指针支持++操作。而list是双向链表,每个节点在内存空间上的分布不是连续的,所以不支持使用全局的sort方法。
malloc操作具有一定的开销,其申请的内存大小其实略大于程序员要求的大小,因为包含了一定大小的头部和尾部,成为Cookies,用来记录一些必要的信息(比如这块被申请的内存的长度)。所以说,当程序员申请的内存空间非常小时,Cookies的占比就会非常的高。若程序员多次申请非常小的内存,例如一百万次,那么就会产生难以忍受的额外开销。解决这种问题的方法之一是内存池(一次性申请一大块,然后自己写一个类来分配)
所以假设容器中有一百万个小元素,那么使用相应的allocator去申请一百万次内存空间,而该allocator只是对malloc的简单包装,没有做任何相关的优化,也就是说调用了一百万次malloc,那么效率会很低,导致总的Cookies占量非常高。
STL中共有五种类型的迭代器(c++20前)
LegacyInputIterator:输入迭代器,例如std::istream_iteratorLegacyOutputIterator:输出迭代器,例如std::ostream_iterator,std::back_insert_iterator和std::front_insert_iteratorLegacyForwardIterator:前向迭代器,同时它也是输入迭代器LegacyBidirectionalIterator:双向迭代器,同时它也是前向迭代器LegacyRandomAccessIterator:随机访问迭代器,这是唯一一个支持比较大小的迭代器,同时也是双向迭代器
而这五种类型,分别代表了五种空结构体标签(通过标签调用到不同的重载函数)
当遗留向前迭代器(LegacyForwardIterator)、遗留双向迭代器(LegacyBidirectionalIterator)或遗留随机访问迭代器(LegacyRandomAccessIterator)在自身的要求之外还满足遗留输出迭代器(LegacyOutputIterator)的要求时,它即被描述为可变的(mutable)
贴几张cppreference的定义
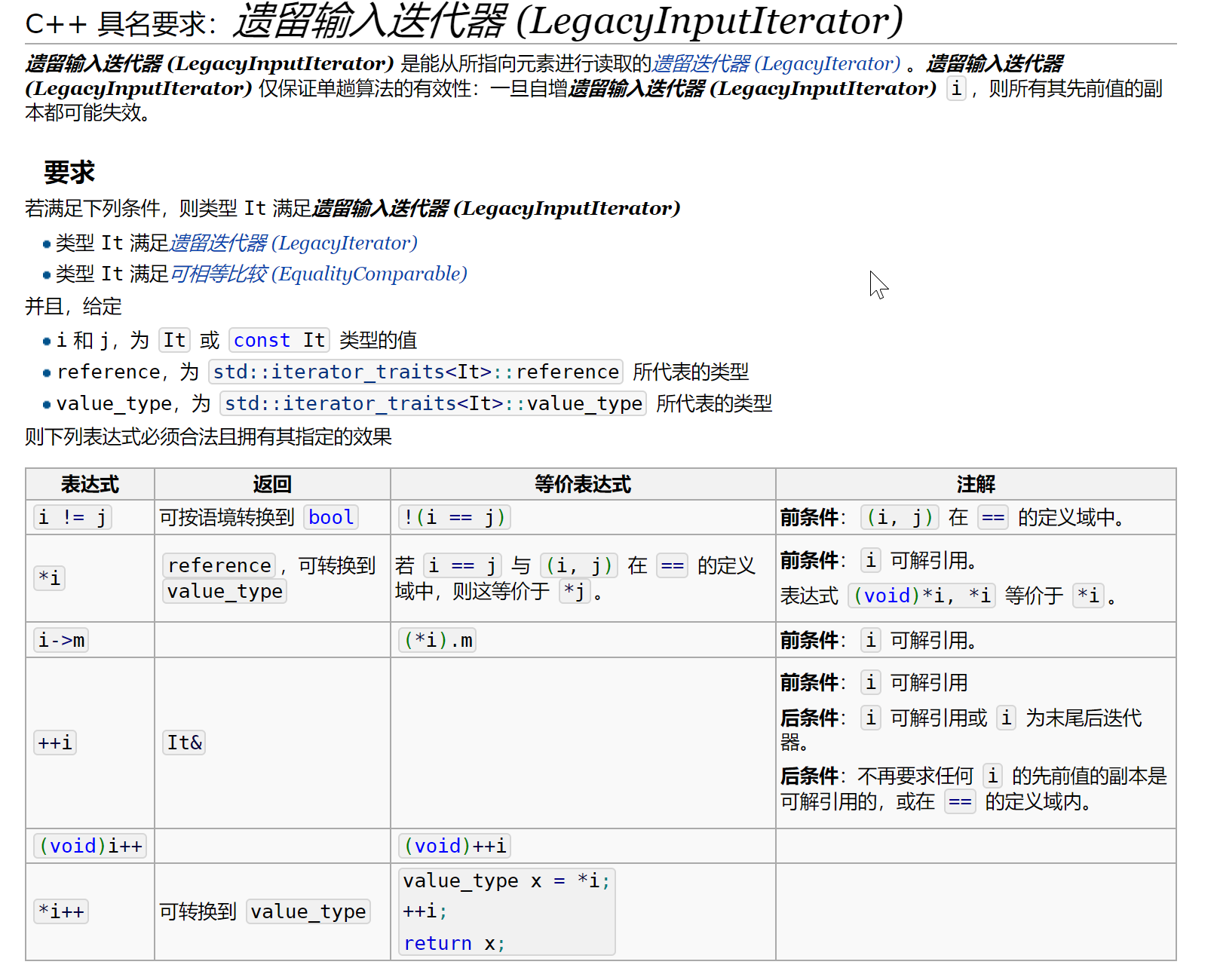
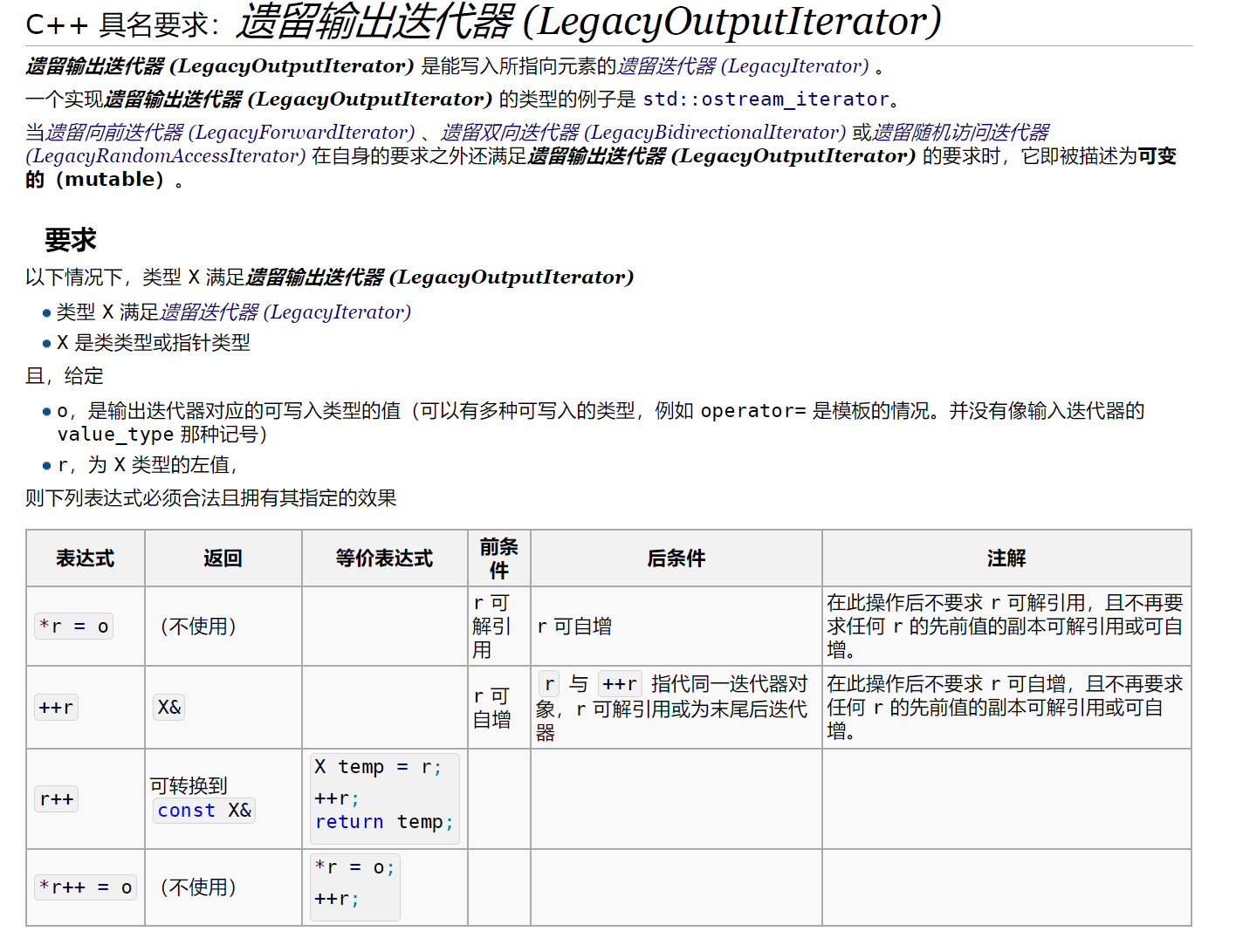

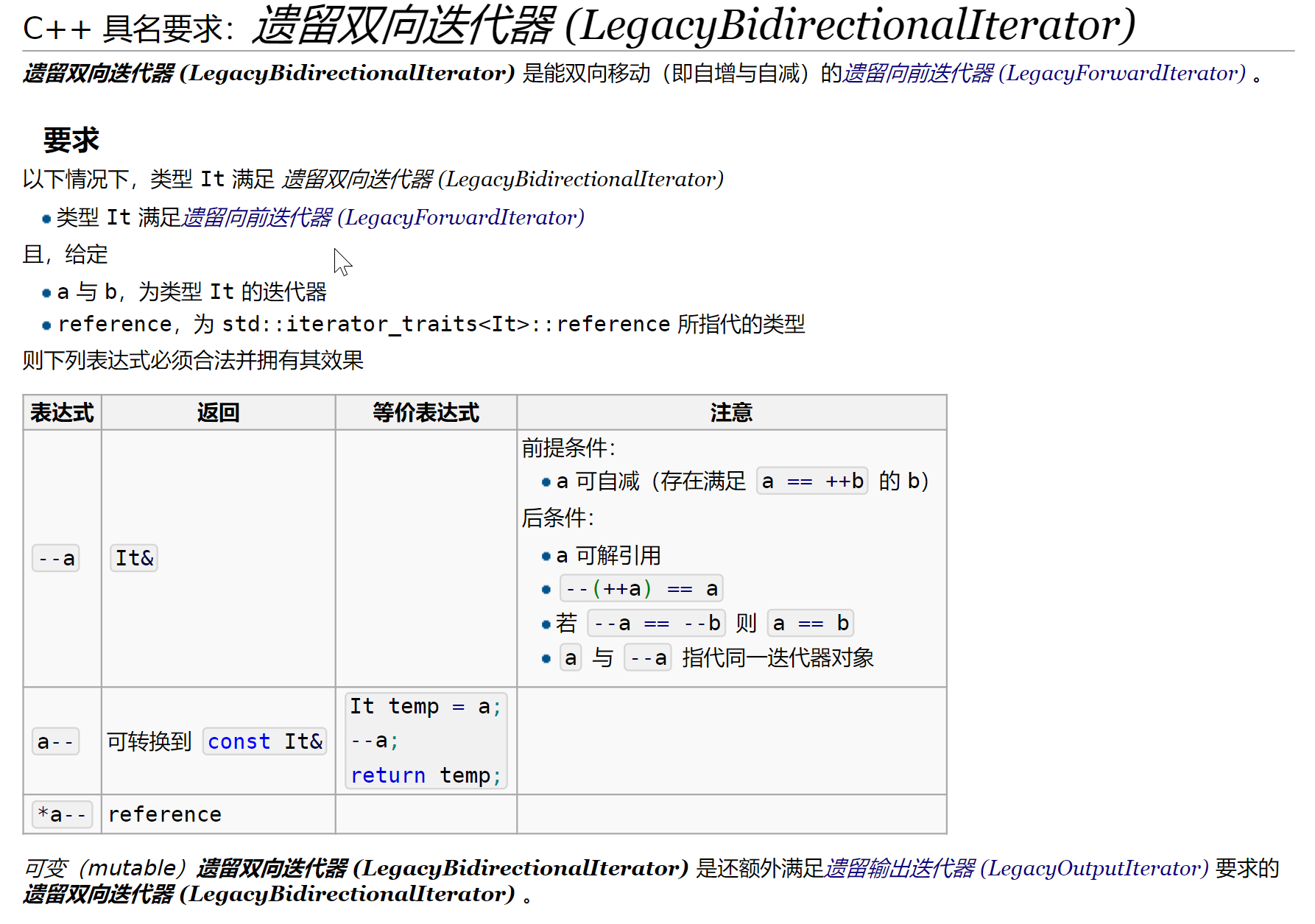
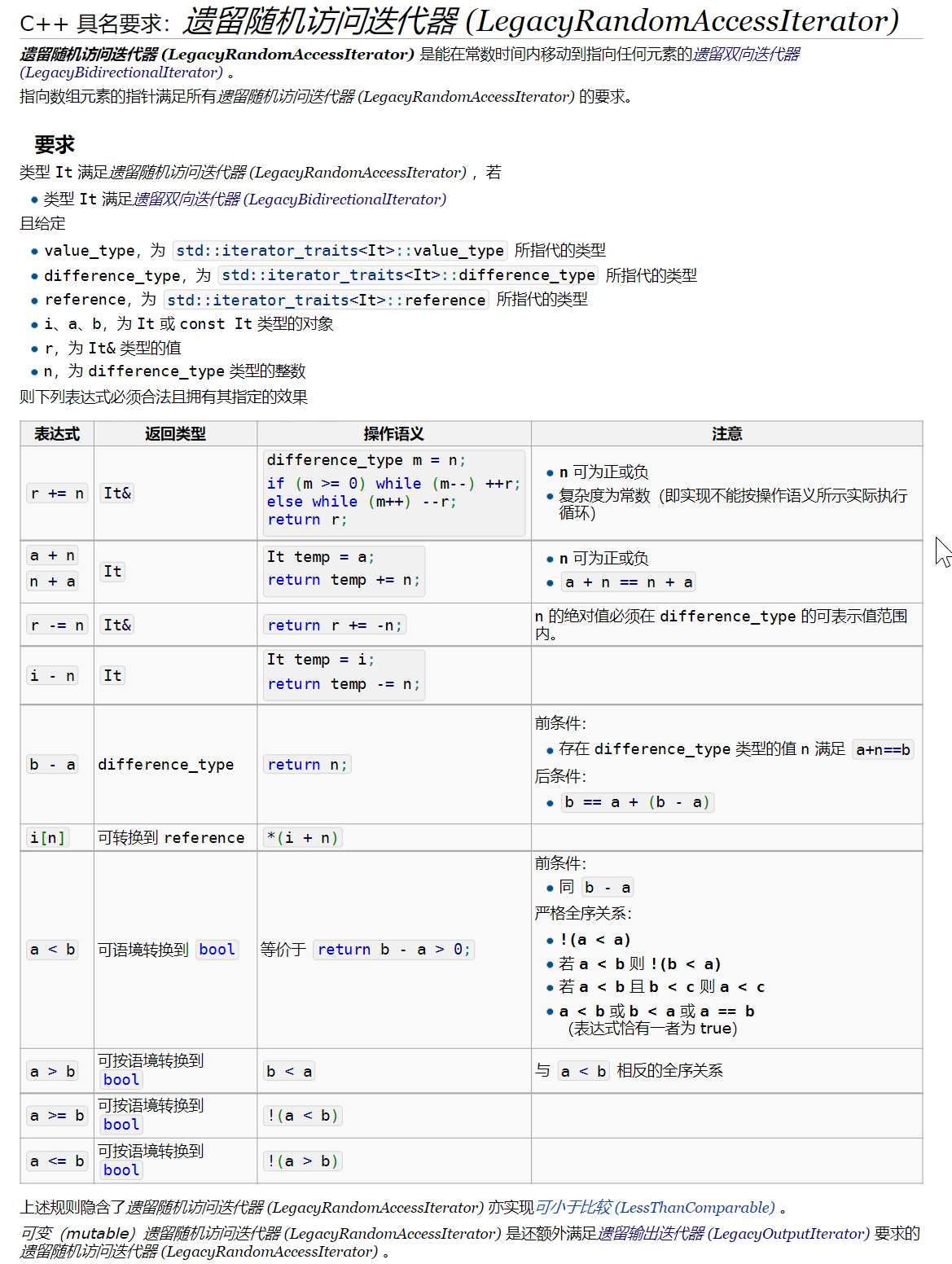
那么我们可以利用这个特性,这么干
void display_category(std::random_access_iterator_tag)
{
std::cout << "random_access_iterator" << std::endl;
}
int main()
{
using it_tag_type = typename std::vector<int>::iterator::iterator_category;
display_category(it_tag_type());
}
实现了一个简单的方法用于输出容器的迭代器类型
template<typename T>
void display_category()
{
using it_tag = typename iterator_traits<T>::iterator_category;
std::cout << typeid(it_tag).name() << std::endl;
}
int main()
{
// struct std::bidirectional_iterator_tag
display_category<std::list<int>::iterator>();
// struct std::bidirectional_iterator_tag
display_category<std::list<int>::const_iterator>();
// struct std::forward_iterator_tag
display_category<std::forward_list<int>::iterator>();
// struct std::bidirectional_iterator_tag
display_category<std::unordered_map<std::string, int>::iterator>();
// struct std::random_access_iterator_tag
display_category<std::deque<int>::iterator>();
}
不是,对于std::vector而言,由于它的本质是动态数组,所以它的iterator是random-access-iterator,且每两个相邻元素之间是内存连续的
逆向迭代器rbegin是否等于endrandom-access-iterator代表我们对迭代器进行加减操作以访问元素的时间复杂度为O(1),例如数组支持随机访问;而链表(
std::list)不支持,访问的时间复杂度为O(n)
不等于,逆序迭代器重载了++和--操作,逆序的++操作其实相当于正序迭代器的--
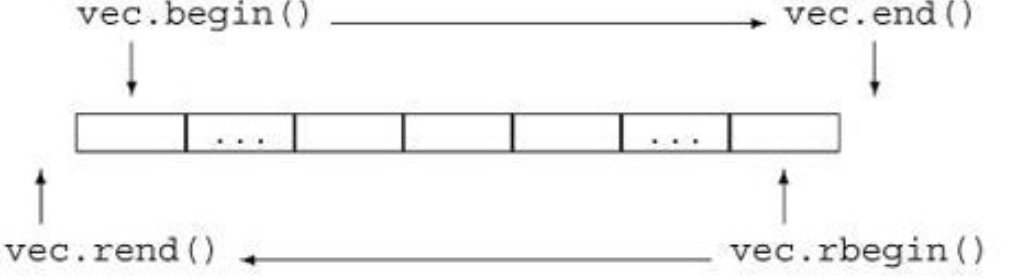
利用逆序迭代器可以反向排序数组
int main()
{
std::vector<int> vec = { 3, 6, 1, -9, 4 };
// 4 -9 1 6 3
for (auto it = vec.rbegin(); it != vec.rend(); ++it)
std::cout << *it << std::endl;
// 使用greater仿函数 代表左大于右 也就是降序数组
std::sort(vec.rbegin(), vec.rend(), greater<int>());
// 逆序排列后结果 升序数组
for (int num : vec)
std::cout << num << std::endl;
}
iterator_traits的简单机理实现
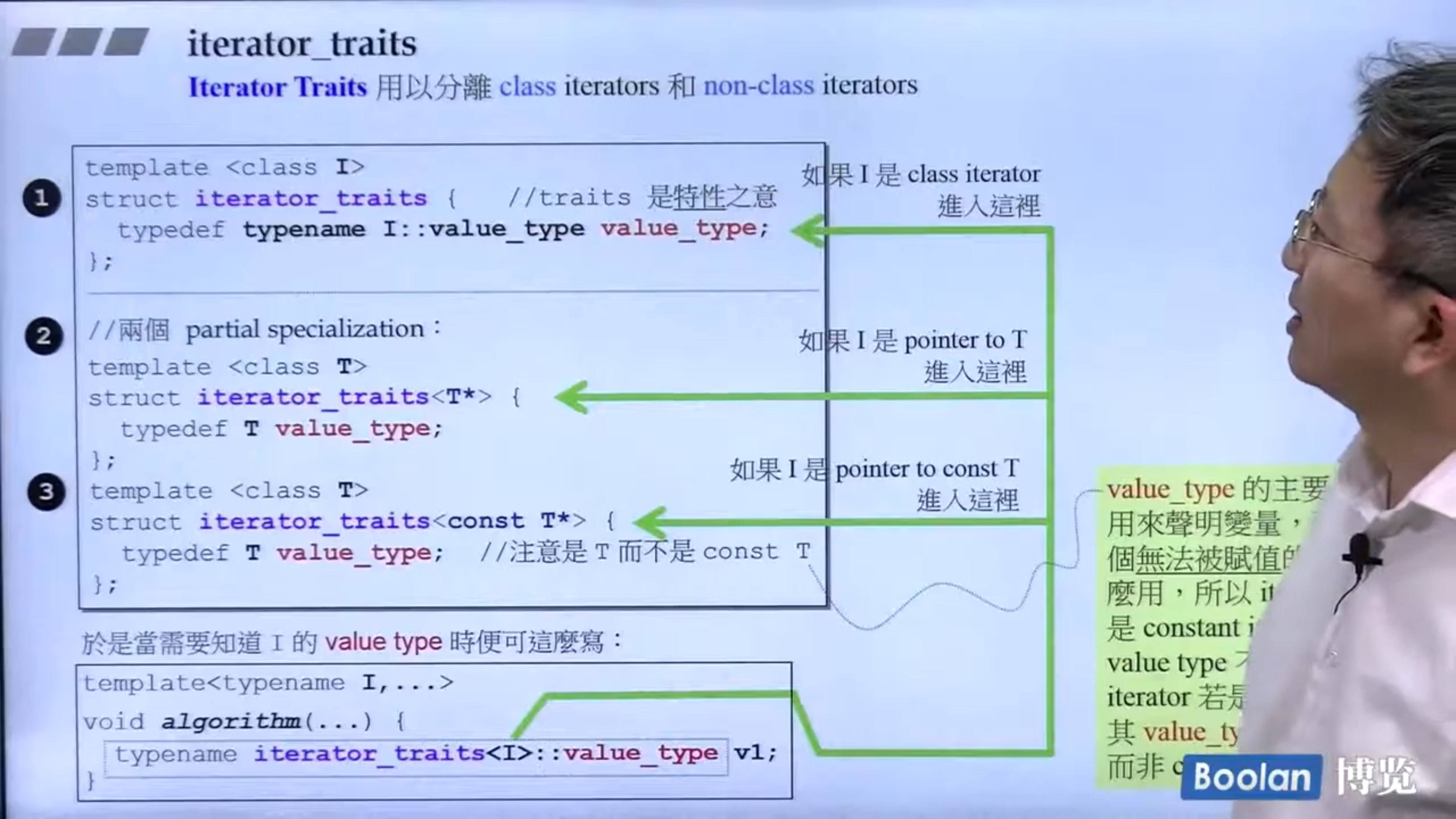
更多相关内容可以参考我的博客:C++ 11中的可变模板参数,C++中的模板元编程(待发布)
std::remove_if,std::find_if,std::find和std::find_if的区别是什么侯捷曾经说过,如果容器中有自己的find函数,那么它一定比<algorithm>中的std::find要更高效。一般情况下,非关联容器(比如std::set,std::unorder_map)都实现了find。这里主要介绍<algorithm>中的std::find和std::find_if
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "John", "Dragon"};
// 在容器中找John 找到了则输出John
if (auto it = std::find(vec.cbegin(), vec.cend(), "John"); it != vec.cend())
std::cout << *it << std::endl;
使用find时传进的时容器元素的类型,而使用find_if时参数传入的是函数对象
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "John", "Dragon"};
if (auto it = std::find_if(vec.cbegin(), vec.cend(), [](const auto& str) { return str == "John"; }); it != vec.cend())
std::cout << *it << std::endl;
引用SOF上的一个问题和回答
Q: Why does the standard library have
findandfind_if? Couldn'tfind_ifjust be an overload offind?A: Consider
find_ifis renamedfind, then you have:template <typename InputIterator, typename T> InputIterator find(InputIterator first, InputIterator last, const T& value); template <typename InputIterator, typename Predicate> InputIterator find(InputIterator first, InputIterator last, Predicate pred);If
find()andfind_if()had the same name, surprising abmiguities would have resulted. In general, the_ifsuffix is used to indicate that an algrithm takes a predicate.
再来看看remove和remove_if。两者的区别和find系列类似,一个接受容器类型,一个接受函数对象。下文中的某个话题讲过,由于remove和remove_if操作是<algorithm>中的方法,因此他们并不能直接删除容器里的元素,因此为了实现删除功能它们时常和成员函数erase搭配使用
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "John", "Mike"};
auto it = std::remove(vec.begin(), vec.end(), "Mike");
// 输出一个空的字符串 因为移动赋值使原字符串置空
std::cout << *it << std::endl;
// "Jelly", "Zed", "John", "", "Mike"
// it
for (const auto& str : vec)
std::cout << str << std::endl;
std::remove操作的返回值有三种情况
- 当要“移除”的元素不在容器中时,会返回
end - 当要移除的元素在最末尾时,无法执行覆盖操作,所以无法“移除”,也会返回末尾元素所在的迭代器
- 当能正常“移除”时,会根据移除的元素的数量,返回倒数第N个元素的迭代器
那么你能猜出这两种情况的结果是什么吗,是的答案就是这么的神奇。但不管结果怎么样,它保证了数组的前部分是我们想要的数据
// "Jelly", "Zed", "John", "Jane", "", ""
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "Mike", "John", "Jane"};
// "Jelly", "Zed", "John", "Jane", "Mike", ""
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "John", "Mike", "Jane"};
std::remove和erase搭配使用能够真正删除容器中的元素,这种搭配也称之为erase-remove_idiom
std::vector<std::string> vec{"Jelly", "Mike", "Zed", "John", "Mike", "Jane"};
vec.erase(std::remove(vec.begin(), vec.end(), "Mike"), vec.end());
// "Jelly", "Zed", "John", "Jane"
for (const auto& str : vec)
std::cout << str << std::endl;
对于没有移动赋值的内置类型来说
// std::remove前
// 1 2 3 4 5
// std::remove第二个元素
// 1 3 4 5 5
erase和std::remove会优先调用移动赋值函数,没有的话再调用拷贝赋值函数。以std::string为例,当A移动赋值给B时,B会获得A的值,同时A置空
std::remove的实现
template<class ForwardIt, class T >
ForwardIt remove(ForwardIt first, ForwardIt last, const T& value)
{
first = std::find(first, last, value);
// 如果找得到符合条件的元素
if (first != last)
{
// 开始逐个遍历后续元素然后进行移动赋值
for (ForwardIt i = first; ++i != last; )
{
// 跳过满足条件的元素
if (*i != value)
*(first++) = std::move(*i);
}
}
return first;
}
std::remove_if的实现
和std::remove的实现几乎是一致的
template<class ForwardIt, class UnaryPredicate>
ForwardIt remove_if(ForwardIt first, ForwardIt last, UnaryPredicate p)
{
first = std::find_if(first, last, p);
if (first != last)
for(ForwardIt i = first; ++i != last; )
if (!p(*i))
*first++ = std::move(*i);
return first;
}
std::distance,求迭代器间的距离
template<class It>
constexpr typename std::iterator_traits<It>::difference_type my_distance(It first, It last)
{
// 先获取迭代器的类型
using category = typename std::iterator_traits<It>::iterator_category;
// 只允许求输出迭代器的distance
static_assert(std::is_base_of_v<std::input_iterator_tag, category>);
// 如果是随机访问迭代器 那么距离直接相减
if constexpr (std::is_base_of_v<std::random_access_iterator_tag, category>)
return last - first;
else
{
// 初始值为0
typename std::iterator_traits<It>::difference_type result = 0;
// 一步一步计算
while (first != last)
{
first++;
result++;
}
return result;
}
}
该算法的时间复杂度为O(1)或者O(n)
std::map<int, int> m{ {1, 1}, {2, 3}, {3, 4}, {4, 5} };
// 4
std::cout << std::distance(m.begin(), m.end()) << std::endl;
std::search,搜寻子序列
源码就是两层for循环
template<class ForwardIt1, class ForwardIt2>
ForwardIt1 search(ForwardIt1 first, ForwardIt1 last, ForwardIt2 s_first, ForwardIt2 s_last);
// 自定义二元比较器
template<class ForwardIt1, class ForwardIt2, class BinaryPredicate>
ForwardIt1 search(ForwardIt1 first, ForwardIt1 last, ForwardIt2 s_first, ForwardIt2 s_last, BinaryPredicate p);
指向范围中
[first, last - (s_last - s_first)),首个子序列[s_first, s_last)起始的迭代器。若找不到这种子序列,则返回last
std::string sourceStr = "Hi Mike, Hello Jelly, Hello Zed, Hello Tomas";
std::string data = "Hello";
auto resultIterInSource = std::search(sourceStr.begin(), sourceStr.end(), data.begin(), data.end());
if (resultIterInSource == sourceStr.end())
std::cout << "无法找到匹配项" << std::endl;
else
std::copy(resultIterInSource, sourceStr.end(), std::ostream_iterator<char>(std::cout));
// Hello Jelly, Hello Zed, Hello Tomas
std::find_end,std::find_first_of
std::find_end,在一个序列中找到最后出现的目标序列
指向范围
[first, last)中[s_first, s_last)最后一次出现的起始的迭代器
std::string sourceStr = "Hello Mike, Hello Jelly, Hello Zed, Hello Tomas";
std::string data = "Hello";
auto resultIterInSource = std::find_end(sourceStr.begin(), sourceStr.end(), data.begin(), data.end());
if (resultIterInSource == sourceStr.end())
std::cout << "无法找到匹配项" << std::endl;
else
std::copy(resultIterInSource, sourceStr.end(), std::ostream_iterator<char>(std::cout));
// Hello Tomas
std::find_first_of,在一个序列中找到最先出现在目标序列的数
源码就是两层for循环
指向范围
[first, last)中等于来自范围[s_first; s_last)中一个元素的首个元素。若找不到这种元素,则返回last
template<class InputIt, class ForwardIt>
InputIt find_first_of(InputIt first, InputIt last, ForwardIt s_first, ForwardIt s_last)
{
for (; first != last; ++first) {
for (ForwardIt it = s_first; it != s_last; ++it) {
if (*first == *it)
return first;
}
}
return last;
}
template<class InputIt, class ForwardIt, class BinaryPredicate>
InputIt find_first_of(InputIt first, InputIt last, ForwardIt s_first, ForwardIt s_last, BinaryPredicate p);
测试案例
// arr中的元素2在vec中最先出现
std::vector<int> vec{0, 2, 3, 25, 5};
int arr[] = {3, 19, 10, 2};
auto resultIterInVec = std::find_first_of(vec.begin(), vec.end(), std::begin(arr), std::end(arr));
if (resultIterInVec == vec.end())
std::cout << "无法找到匹配项" << std::endl;
else
std::cout << "在vec中第" << std::distance(vec.begin(), resultIterInVec) << "处找到arr中的项" << std::endl;
std::all_of,std::any_of,std::none_of
std::all_of:检查一元谓词p是否对范围[first, last)中所有元素返回 true
std::any_of:检查一元谓词p是否对范围[first, last)中至少一个元素返回 true
std::none_of:检查一元谓词p是否不对范围[first, last)中任何元素返回 true
// 若没有不满足条件的 那么说明全部都满足条件
template< class InputIt, class UnaryPredicate >
bool all_of(InputIt first, InputIt last, UnaryPredicate p)
{
return std::find_if_not(first, last, p) == last;
}
// 如果能找到满足条件的 那么说明起码有一个能满足条件
template< class InputIt, class UnaryPredicate >
bool any_of(InputIt first, InputIt last, UnaryPredicate p)
{
return std::find_if(first, last, p) != last;
}
// 如果找不到能满足条件的 那么说明全部都不满足条件
template< class InputIt, class UnaryPredicate >
bool none_of(InputIt first, InputIt last, UnaryPredicate p)
{
return std::find_if(first, last, p) == last;
}
照搬cppreference的代码
std::vector<int> v(10, 2);
// 逐个累加 类似dp
// 2 4 6 8 10 12 14 16 18 20
std::partial_sum(v.cbegin(), v.cend(), v.begin());
std::copy(v.cbegin(), v.cend(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
if (std::all_of(v.cbegin(), v.cend(), [](int i) { return i % 2 == 0; }))
std::cout << "所有的数都是偶数" << std::endl;
if (std::none_of(v.cbegin(), v.cend(), std::bind(std::modulus<>{}, std::placeholders::_1, 2)))
std::cout << "没有数是奇数" << std::endl;
if (std::any_of(v.cbegin(), v.cend(), [](auto&& data) { return std::modulus<>{}(std::forward<decltype(data)>(data), 7); }))
std::cout << "至少有一个数能被7整除" << std::endl;
std::count,查目标元素在序列中出现的次数
std::string sourceStr = "Hi Mike, Hello Jelly, Hello Zed, Hello Tomas";
// 4
std::cout << std::count(sourceStr.begin(), sourceStr.end(), 'H') << std::endl;
std::next,std::prev,返回移动n位后的迭代器
对于非随机访问迭代器的容器而言,通过for循环来遍历n位之后的元素显然并不是很雅观。因此STL中给出了一个封装
template<class InputIt>
constexpr InputIt next(InputIt it, typename std::iterator_traits<InputIt>::difference_type n = 1) {
std::advance(it, n);
return it;
}
template<class BidirIt>
constexpr BidirIt prev(BidirIt it, typename std::iterator_traits<BidirIt>::difference_type n = 1) {
std::advance(it, -n);
return it;
}
template<class It, class Distance>
constexpr void advance(It& it, Distance n)
{
// 判断迭代器的类型
using category = typename std::iterator_traits<It>::iterator_category;
// 只允许输入迭代器进行计算
static_assert(std::is_base_of_v<std::input_iterator_tag, category>);
auto dist = typename std::iterator_traits<It>::difference_type(n);
// 根据不同的迭代器进行不同的计算
if constexpr (std::is_base_of_v<std::random_access_iterator_tag, category>)
it += dist;
else {
while (dist > 0) {
--dist;
++it;
}
if constexpr (std::is_base_of_v<std::bidirectional_iterator_tag, category>) {
while (dist < 0) {
++dist;
--it;
}
}
}
}
std::list<int> l(20);
std::iota(l.begin(), l.end(), 1);
std::cout << *std::next(l.begin(), 0) << std::endl; // 1
std::cout << *std::next(l.begin()) << std::endl; // 2
std::cout << *std::next(l.begin(), 5) << std::endl; // 6
std::cout << *std::next(l.end(), -1) << std::endl; // 20
std::cout << *std::prev(l.end(), 1) << std::endl; // 20
std::copy,从源序列拷贝到目标序列
std::iota
在此之前先来看看std::iota,它包含在头文件<numeric>中
// 10个0
std::vector<int> vec(10);
// 从开始递增 修改区间中的值
std::iota(vec.begin(), vec.end(), 1);
// 输出1-10
for (auto& data : vec)
std::cout << data << std::endl;
这和算法主要用于构建整形,如int,unsigned int,或者是重置了前置++操作的自定义类型。它的实现为
template<class ForwardIterator, class T>
constexpr // C++20 起
void iota(ForwardIterator first, ForwardIterator last, T value)
{
while(first != last) {
*first++ = value++;
}
}
std::copy
std::copy和std::copy_if所干的事情就是拷贝赋值/拷贝构造,它们并不负责申请内存
template<class InputIt, class OutputIt>
OutputIt copy(InputIt first, InputIt last, OutputIt d_first)
{
while (first != last) {
*d_first++ = *first++;
}
return d_first;
}
std::vector<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> result(5);
// 第三个参数为一个能用于添加元素到容器result尾端的std::back_insert_iterator
std::copy(vec.begin(), vec.end(), std::back_inserter(result));
// 0 0 0 0 0 1 2 3 ... 10 共15个元素
for (int data : result)
std::cout << data << std::endl;
std::back_insert_iterator可以对应为容器的push_back操作,反过来说:只有支持push_back的容器才支持std::back_insert_iterator
如果我们想push_front的话那么可以这么做,因为std::vector不支持push_front操作所以测试用例换为std::list
std::list<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::list<int> result(5);
// 使用拷贝构造向result头部插入10个元素
std::copy(vec.begin(), vec.end(), std::front_inserter(result));
// 10 9 8 ... 1 0 0 0 0 0 共15个元素
for (int data : result)
std::cout << data << std::endl;
特殊的,如果能确保result的容量大于等于vec,那么使用begin也是可以的
std::vector<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> result(15);
// 使用拷贝赋值修改result的前十位
std::copy(vec.begin(), vec.end(), result.begin());
// 1 2 3 ... 10 0 0 0 0 0 共15个元素
for (int data : result)
std::cout << data << std::endl;
std::copy_if
std::copy_if中的if可以理解为“如果”,顾名思义,第四个参数传入的肯定就是一个用于判断的函数对象了
template<class InputIt, class OutputIt, class UnaryPredicate>
OutputIt copy_if(InputIt first, InputIt last, OutputIt d_first, UnaryPredicate pred)
{
while (first != last) {
if (pred(*first))
*d_first++ = *first;
++first;
}
return d_first;
}
令result只拷贝源数组中的偶数
std::vector<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> result;
// 只拷贝偶数
std::copy_if(vec.begin(), vec.end(), std::back_inserter(result), [](int data) { return data % 2 == 0; });
// 2 4 6 8 10
for (int data : result)
std::cout << data << std::endl;
std::move,从源序列移动到目标序列
C++中的operator=共有两种形式,一种是拷贝,另一种是移动。当我们遇到不可复制的类时,就得使用std::move
这里实现一个只支持移动拷贝的类
class NonCopyClass
{
private:
std::string name;
public:
NonCopyClass() = default;
NonCopyClass(std::string _name) : name(std::move(_name)) {}
NonCopyClass(const NonCopyClass& _copy) = delete;
NonCopyClass(NonCopyClass&& _copy) : name(std::move(_copy.name)) {}
NonCopyClass& operator=(const NonCopyClass& _copy) = delete;
NonCopyClass& operator=(NonCopyClass&& _copy) = delete;
};
// 调用到移动构造
std::vector<NonCopyClass> vec(10);
std::vector<NonCopyClass> result;
std::move(vec.begin(), vec.end(), std::back_inserter(result));
// 调用到移动赋值 而它已经被删除了 故无法通过编译
// std::vector<NonCopyClass> temp(10);
// std::move(vec.begin(), vec.end(), temp.begin());
C++中的线程类(std::thread)就是不可被拷贝的,这里放一个cppreference的例子
#include <iostream>
#include <vector>
#include <list>
#include <iterator>
#include <thread>
#include <chrono>
void f(int n)
{
std::this_thread::sleep_for(std::chrono::seconds(n));
std::cout << "thread " << n << " ended" << std::endl;
}
int main()
{
std::vector<std::thread> vec;
vec.emplace_back(f, 1);
vec.emplace_back(f, 2);
vec.emplace_back(f, 3);
std::list<std::thread> l;
// copy()无法编译,因为std::thread不可复制
std::move(v.begin(), v.end(), std::back_inserter(l));
for (auto& t : l)
t.join();
}
再来看一个例子,主要是为了体现关联式容器的特性
struct MoveStructStr
{
std::string data;
MoveStructStr(const char* _data) : data(_data) {}
// 两种构造函数缺一不可
MoveStructStr(MoveStructStr&& _move) noexcept : data(std::move(_move.data)) {}
MoveStructStr(const MoveStructStr& _copy) : data(_copy.data) {};
// 本例中并不需要移动赋值
MoveStructStr& operator=(MoveStructStr&& _move) = delete;
// 迭代器解引用是const volatile std::pair<const, non-const>&类型
// 定义为常函数使pair.first能调用到
bool operator<(const MoveStructStr& _other) const { return data < _other.data; }
};
int main()
{
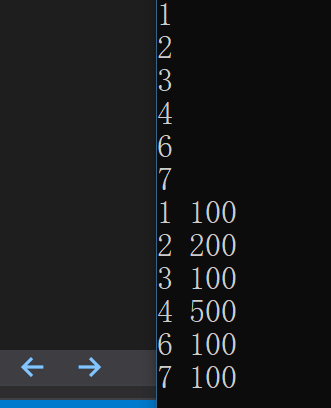
std::map<MoveStructStr, MoveStructStr> m{ {"1", "100"}, {"2", "200"}, {"3", "100"}, {"4", "500"}, {"6", "100"}, {"7", "100"} };
std::map<MoveStructStr, MoveStructStr> result;
std::move(m.begin(), m.end(), std::inserter(result, result.end()));
for (auto& p : m)
std::cout << p.first.data << " " << p.second.data << std::endl;
for (auto& p : result)
std::cout << p.first.data << " " << p.second.data << std::endl;
}
运行的结果为,对key调用到拷贝赋值,对value调用到移动赋值
std::transform,对1-2个序列进行变换,结果存入新序列
如果说前两者都是照抄,那么std::tranform就是在抄的基础上加点花样
int main()
{
std::vector<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> result;
// 调用到元素的拷贝/移动构造
std::transform(vec.begin(), vec.end(), vec.begin(), std::back_inserter(result), std::multiplies<>{});
// 1 4 9 16 25 ... 100
for (int data : result)
std::cout << data << std::endl;
}
因为std::multiplies<>是二元函数对象,所以需要调用到此重载。因为没有限定first2的结束界限,所以在使用过程中需要格外注意
template<class InputIt1, class InputIt2, class OutputIt, class BinaryOperation>
OutputIt transform(InputIt1 first1, InputIt1 last1, InputIt2 first2, OutputIt d_first, BinaryOperation binary_op)
{
while (first1 != last1) {
*d_first++ = binary_op(*first1++, *first2++);
}
return d_first;
}
对应的一元函数版本为,实现极其相似
template<class InputIt, class OutputIt, class UnaryOperation>
OutputIt transform(InputIt first1, InputIt last1, OutputIt d_first, UnaryOperation unary_op)
{
while (first1 != last1) {
*d_first++ = unary_op(*first1++);
}
return d_first;
}
上述两个视线中的OutputIt d_first可以使用std::back_inserter,std::front_inserter,又或是容器中的迭代器,具体情况应根据项目需求走。
std::vector<int> vec(10);
std::iota(vec.begin(), vec.end(), 1);
std::vector<int> result(10);
// 调用到operator= 尽管对于int类型而言赋值和构造并没有区别
std::transform(vec.begin(), vec.end(), result.begin(), [](int data) { return data * data * data; });
// 数的立方
for (int data : result)
std::cout << data << std::endl;
std::replace,对源序列元素进行替换
std::replace
故名思意,替换,一切还是老套路
template<class ForwardIt, class T>
void replace(ForwardIt first, ForwardIt last, const T& old_value, const T& new_value)
{
for (; first != last; ++first) {
if (*first == old_value) {
*first = new_value;
}
}
}
std::vector<int> vec{1, 2, 3, 4, 4, 6, 7, 8};
// replace 4 as 100
std::replace(vec.begin(), vec.end(), 4, 100);
// 1 2 3 100 100 6 7 8
for (int i : vec)
std::cout << i << std::endl;
std::replace_if
std::replace_if则支持传入自定义函数对象,来判断替换的元素是否满足条件
template<class ForwardIt, class UnaryPredicate, class T>
void replace_if(ForwardIt first, ForwardIt last, UnaryPredicate p, const T& new_value)
{
for (; first != last; ++first) {
if(p(*first)) {
*first = new_value;
}
}
}
std::vector<int> vec{1, 2, 3, 4, 4, 6, 7, 8};
// 将小于4的数替换为100
std::replace_if(vec.begin(), vec.end(), std::bind(std::less<int>{}, std::placeholders::_1, 4), 100);
// 100 100 100 4 4 6 7 8
for (auto i : vec)
std::cout << i << std::endl;
std::fill,对源序列进行批量赋值
std::fill
更简单了,直接放实现
template< class ForwardIt, class T >
void fill(ForwardIt first, ForwardIt last, const T& value)
{
for (; first != last; ++first) {
*first = value;
}
}
将数组的元素全部填充为100
std::vector<int> vec(10);
std::fill(vec.begin(), vec.end(), 100);
std::fill_n
std::fill_n则是从开头开始,填充n个元素
template<class OutputIt, class Size, class T>
OutputIt fill_n(OutputIt first, Size count, const T& value)
{
for (Size i = 0; i < count; ++i) {
*first++ = value;
}
return first;
}
因此我们可以做出这么一件“无聊”的事情
// std::vector<int> vec(10, 100);
std::vector<int> vec;
vec.reserve(10);
std::fill_n(std::back_inserter(vec), 10, 100);
for (int i : vec)
std::cout << i << std::endl;
std::generate,调用Generator来产生序列
std::generate
源码实现也是非常的简单,通过传递进来的函数对象,对容器中的每个元素执行一次
template<class ForwardIt, class Generator>
constexpr // Since C++20
void generate(ForwardIt first, ForwardIt last, Generator g)
{
while (first != last) {
*first++ = g();
}
}
std::generate_n
// Since C++20
template<class OutputIt, class Size, class Generator >
constexpr OutputIt generate_n(OutputIt first, Size count, Generator g)
{
for (Size i = 0; i < count; ++i)
*first++ = g();
return first;
}
应用场景如下
std::unordered_map<int, int> create_unordered_map(std::size_t size, int data)
{
std::unordered_map<int, int> result;
auto lambda = [&]() -> std::pair<int, int> { return { data++, data }; };
std::generate_n(std::inserter(result, result.end()), size, lambda);
return result;
}
int main()
{
auto m = create_unordered_map(30, 1);
// {1, 2} {2, 3} {3, 4} {4, 5} ... {30, 31}
for (auto& p : m)
std::cout << p.first << " " << p.second << std::endl;
}
cppreference中的例子,利用输出迭代器输出随机数
#include <random>
#include <iostream>
#include <iterator>
#include <algorithm>
int main()
{
// 默认构造,以固定的种子播种
std::mt19937 rng;
std::generate_n(std::ostream_iterator<std::mt19937::result_type>(std::cout, " "),
5, std::ref(rng));
// 种子固定 每次输出的结果固定
// 3499211612 581869302 3890346734 3586334585 545404204
std::cout << '
';
}
std::unique,将相邻且相同的值移到结尾
std::unique
std::unique有两个重载版本,第一个版本直接使用==判断相等,第二个版本使用自定义函数对象判断是否相等
template<class ForwardIt>
ForwardIt unique(ForwardIt first, ForwardIt last)
{
if (first == last)
return last;
ForwardIt result = first;
while (++first != last) {
if (!(*result == *first) && ++result != first) {
*result = std::move(*first);
}
}
return ++result;
}
template<class ForwardIt, class BinaryPredicate>
ForwardIt unique(ForwardIt first, ForwardIt last, BinaryPredicate p)
{
if (first == last)
return last;
ForwardIt result = first;
while (++first != last) {
if (!p(*result, *first) && ++result != first) {
*result = std::move(*first);
}
}
return ++result;
}
为什么第二个版本不命名为
std::unique_if?我也不知道
cppreference上的测试案例很有教育意义
// 含有数个重复元素的 vector
std::vector<int> v{ 1, 2, 1, 1, 3, 3, 3, 4, 5, 4 };
// 移除相继(毗邻)的重复元素
auto last = std::unique(v.begin(), v.end());
// v 现在保有 {1 2 1 3 4 5 4 x x x} ,其中 x 不确定
// 注:这里的不确定是指我们并不需要去关心它的值是什么 并不是出现不确定的值
v.erase(last, v.end());
// {1 2 1 3 4 5 4}
for (int i : v)
std::cout << i << std::ends;
std::cout << std::endl;
// sort 后 unique 以移除所有重复
std::sort(v.begin(), v.end());
v.erase(std::unique(v.begin(), v.end()), v.end());
// {1 2 3 4 5}
for (int i : v)
std::cout << i << std::ends;
std::cout << std::ends;
所以如果我们想消除容器中所有相同的元素,那么我们应该先排序再清除
下面介绍一个坑点,对关联式容器使用std::unique
struct is_pair_the_same
{
bool operator()(const std::pair<int, int> p1, const std::pair<int, int> p2)
{
return p1.second == p2.second;
}
};
int main()
{
std::map<int, int> m{ {1, 100}, {2, 200}, {3, 100}, {4, 500}, {6, 100}, {7, 100} };
m.erase(std::unique(m.begin(), m.end(), is_pair_the_same{}), m.end());
for (auto& p : m)
std::cout << p.first << " " << p.second << std::endl;
}
对于关联式容器,它的键值对是const and volatile的,因此也不满足move-assignable,所以以上代码无法通过编译
同理,std::remove系列也无法在关联式容器上使用

std::unique_copy
std::unique_copy是将裁剪后的结果存放到一个新容器中,例如
// 使用std::unique
std::string str1 = "The string with many spaces!";
str1.erase(std::unique(str1.begin(), str1.end(), [](char c1, char c2) { return c1 == ' ' && c2 == ' '; }), str1.end());
// The string with many spaces!
std::cout << str1 << std::endl;
// 使用std::unique_copy
std::string str1 = "The string with many spaces!";
std::string result;
std::unique_copy(str1.begin(), str1.end(), std::back_inserter(result), [](char c1, char c2) { return c1 == ' ' && c2 == ' '; });
// The string with many spaces!
std::cout << result << std::endl;
至于拷贝操作使用的是拷贝构造函数还是拷贝赋值函数,要根据使用的迭代器的类型分析。上例中拷贝前result为空,且使用尾插迭代器,故调用到拷贝构造函数(尽管对于内置类型char来说两者没有区别)
所以对于关联性容器,应该对其使用std::unique_copy
struct is_pair_the_same
{
bool operator()(const std::pair<int, int>& p1, const std::pair<int, int>& p2)
{
return p1.second == p2.second;
}
};
int main()
{
std::map<int, int> m{ {1, 100}, {2, 200}, {3, 100}, {4, 500}, {6, 100}, {7, 100} };
std::map<int, int> result;
std::unique_copy(m.begin(), m.end(), std::inserter(result, result.end()), is_pair_the_same{});
// {1, 100} {2, 200} {3, 100} {4, 500} {6, 100}
for (auto& p : result)
std::cout << p.first << " " << p.second << std::endl;
}
std::reverse,倒置一个序列
一般有rbegin和rend这两个成员函数的容器才能被std::reverse,如std::map,std::unordered_set就不可以。此算法的时间复杂度为(last - first) / 2
但是一般情况下要逆序操作一个序列更推荐使用逆向迭代器进行遍历
int arr[] = {1, 2, 3, 4, 5, 63, 4};
// 4 63 5 4 3 2 1
std::reverse(std::begin(arr), std::end(arr));
std::vector<int> vec{1, 2, 3, 4, 5, 63, 4};
for (auto it = vec.rbegin(); it != vec.rend(); ++it)
std::cout << *it << std::endl;
std::rotate,进行元素范围上的旋转
// C++20 起
template<class ForwardIt>
constexpr ForwardIt rotate(ForwardIt first, ForwardIt n_first, ForwardIt last)
{
if(first == n_first) return last;
if(n_first == last) return first;
auto read = n_first;
auto write = first;
auto next_read = first; // "read" 撞击 "last" 时的读取位置
while(read != last) {
if(write == next_read) next_read = read; // 跟踪 "first" 所至
std::iter_swap(write++, read++);
}
// 旋转剩余序列到位置中
(rotate)(write, next_read, last);
return write;
}
具体而言, std::rotate 交换范围 [first, last) 中的元素,方式满足元素 n_first 成为新范围的首个元素,而 n_first - 1 成为最后元素
此函数的前提条件是 [first, n_first) 和 [n_first, last) 为合法范围
std::vector<int> vec{1, 2, 3, 4, 5, 6, 7, 8, 9};
// 4 5 6 7 8 9 1 2 3
std::rotate(vec.begin(), vec.begin() + 3, vec.end());
使用std::rotate实现插入排序
for (auto i = v.begin(); i != v.end(); ++i)
std::rotate(std::upper_bound(v.begin(), i, *i), i, i + 1);
std::shuffle
用于重新随机排列一个序列
在C++17之前
std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::random_device rd;
std::mt19937 g(rd());
for (int i = 0; i < 3; i++)
{
std::shuffle(v.begin(), v.end(), g);
std::copy(v.begin(), v.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
}
C++20
std::vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::random_device rd;
std::mt19937 g(rd());
for (int i = 0; i < 3; i++)
{
std::ranges::shuffle(v.begin(), v.end(), g);
std::copy(v.begin(), v.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
}
std::accumulate,std::reduce:求数列的“和”
std::vector<int> vec = {1, 2, 3, 4};
// 0 + 1 + 2 + 3 + 4 = 10
std::cout << std::accumulate(vec.begin(), vec.end(), 0) << std::endl;
// 100 * 1 * 2 * 3 * 4 = 2400
std::cout << std::accumulate(vec.begin(), vec.end(), 100, std::multiplies{}) << std::endl;
// 1-2-3-4
std::cout << std::accumulate(std::next(vec.begin()), vec.end(), std::to_string(vec[0]),
[](std::string preStr, int data) { return std::move(preStr) + "-" + std::to_string(data); }) << std::endl;
std::reduce和std::accumulate非常相似,只是std::reduce在计算的过程中不保证会从头到尾按序结算;同时std::reduce支持多线程计算,依赖于库<execution>,更多的多线程算法库会在中介绍
auto vec = generate_random_container_multi_thread<std::vector>(10000000, 0, 1000);
InTime it;
// 耗时0.039s
std::cout << std::accumulate(vec.begin(), vec.end(), 0ll) << std::endl;
it.Stop();
it.ReStart();
// 耗时0.016s
std::cout << std::reduce(std::execution::par, vec.begin(), vec.end(), 0ll) << std::endl;
it.Stop();
二分查找,针对有序序列的查找
std::lower_bound,std::upper_bound
在STL中,有lower_bound和upper_bound两种,两者默认操作升序数组(默认为less<T>())。对于自定义类型而言,需要重载operator<或者传入比较函数
std::vector<int> vec = {1, 2, 3, 3, 3, 5, 6, 9};
// 找大于等于
std::cout << *std::lower_bound(vec.begin(), vec.end(), 5) << std::endl; // 5
// 找大于
std::cout << *std::upper_bound(vec.begin(), vec.end(), 5) << std::endl; // 6
- 如果找的是数3,那么
lower_bound会返回指向第一个3的指针,upper_bound会返回指向5的指针 - 如果找的是数4,那么
lower_bound,upper_bound都会返回指向数字5的指针 - 如果找的是数-100,那么两者都会返回指向数组第一个元素的指针;如果找的是数100,那么两者都会返回
vec.end()。因此在查找的时候应该把数据限制在该数组的最大最小范围内
// 找小于等于
std::lower_bound(vec.begin(), vec.end(), 5, std::greater<int>());
// 找小于
std::upper_bound(vec.begin(), vec.end(), 5, std::greater<int>());
std::binary_search
经典的二分查找,它是对std::lower_bound的一层封装
// 针对升序数组
template<class ForwardIt, class T>
bool binary_search(ForwardIt first, ForwardIt last, const T& value)
{
first = std::lower_bound(first, last, value);
return (!(first == last) && !(value < *first));
}
// 根据Compare可应用于升序或降序数组
template<class ForwardIt, class T, class Compare>
bool binary_search(ForwardIt first, ForwardIt last, const T& value, Compare comp)
{
first = std::lower_bound(first, last, value, comp);
return (!(first == last) && !(comp(value, *first)));
}
针对降序数组的二分查找
std::vector<int> vec = {1, 2, 3, 3, 3, 5, 6, 9};
auto it = std::binary_search(vec.rbegin(), vec.rend(), 5, greater<>{});
// true
std::cout << std::boolalpha << it << std::endl;
std::equal_range
这是对std::lower_bound和std::upper_bound的封装,目的是为了找出某个重复的数的区间
std::vector<int> vec = {1, 2, 3, 3, 3, 5, 6, 9};
// 默认为less<>{} 操作升序数组
auto [first, second] = std::equal_range(vec.begin(), vec.end(), 3);
// 3 5
std::cout << *first << " " << *second << std::endl;
具体实现为
template<class ForwardIt, class T>
std::pair<ForwardIt,ForwardIt> equal_range(ForwardIt first, ForwardIt last, const T& value)
{
return std::make_pair(std::lower_bound(first, last, value), std::upper_bound(first, last, value));
}
template<class ForwardIt, class T, class Compare>
std::pair<ForwardIt,ForwardIt> equal_range(ForwardIt first, ForwardIt last, const T& value, Compare comp);
{
return std::make_pair(std::lower_bound(first, last, value, comp), std::upper_bound(first, last, value, comp));
}
在多重哈希容器中,STL实现了成员函数equal_range,用于遍历容器中重复的元素,下文中有具体的案例这里不再赘述
std::merge,合并操作 对有序序列
和二分查找一样,std::merge操作的也是有序序列,因此有重载版本可以应用于升序或者降序的数列
// 操作升序数列
template<class InputIt1, class InputIt2, class OutputIt>
OutputIt merge(InputIt1 first1, InputIt1 last1, InputIt2 first2, InputIt2 last2, OutputIt d_first)
{
for (; first1 != last1; ++d_first)
{
if (first2 == last2)
return std::copy(first1, last1, d_first);
if (*first2 < *first1)
*d_first = *first2++;
else
*d_first = *first1++;
}
return std::copy(first2, last2, d_first);
}
// 根据Compare类型操作升序或者降序数列
template<class InputIt1, class InputIt2, class OutputIt, class Compare>
OutputIt merge(InputIt1 first1, InputIt1 last1, InputIt2 first2, InputIt2 last2, OutputIt d_first, Compare comp)
{
for (; first1 != last1; ++d_first)
{
if (first2 == last2)
return std::copy(first1, last1, d_first);
if (comp(*first2, *first1))
*d_first = *first2++;
else
*d_first = *first1++;
}
return std::copy(first2, last2, d_first);
}
将两个有序数组合并为一个新的数组,升序
// 两个升序数组
std::vector<int> vec1 {1, 3, 6 ,20, 40};
std::vector<int> vec2 {5, 32, 76 ,100, 144};
std::vector<int> result;
// 1 2 5 6 20 32 40 76 100 144 升序排列
std::merge(vec1.begin(), vec1.end(), vec2.begin(), vec2.end(), std::back_inserter(result), less<>{});
又或者对关联式容器进行合并
std::map<int, int> vec1{{1, 2}, {2, 3}, {4, 3}, {6, 2}};
std::map<int, int> vec2 {{5, 1}, {-3, 2}, {10, 2}};
std::map<int, int> result;
std::merge(vec1.begin(), vec1.end(), vec2.begin(), vec2.end(), std::inserter(result, result.end()));
std::merge需要提供第三方容器进行“copy”,而std::inplace_merge则原地合并,下面来看如何自己实现归并排序
std::inplace_merge归并二个相继的已排序范围[first, middle)及[middle, last)为一个已排序范围[first, last)。
// 降序归并排序
template<class Iter>
void merge_sort(Iter first, Iter last)
{
if (last - first > 1) {
Iter middle = first + (last - first) / 2;
merge_sort(first, middle);
merge_sort(middle, last);
std::inplace_merge(first, middle, last, greater<>{});
}
}
int main()
{
// 一系列随机操作
std::random_device rd;
std::mt19937 g(rd());
std::uniform_int_distribution<int> dis(0, 1000);
std::vector<int> v;
std::generate_n(std::back_inserter(v), 20, std::bind(dis, std::ref(g)));
merge_sort(v.begin(), v.end());
}
std::set_xxx,集合运算
这部分就不贴源码展示了,感兴趣的可以访问
std::set_difference,计算两个有序序列的差集
struct StudentNum
{
int number;
// 初始化用
StudentNum(int _number) : number(_number) {}
// 输出迭代器用
StudentNum(const StudentNum&) = default;
// 输出用
friend std::ostream& operator<<(std::ostream& os, const StudentNum& studentNum) { return os << studentNum.number; }
};
int main()
{
std::vector<StudentNum> oldStudent = {{10}, {20}, {30}, {40}, {50}, {60}};
std::vector<StudentNum> newStudent = {{15}, {20}, {40}, {50}, {70}};
std::vector<StudentNum> leftStudent;
std::set_difference(oldStudent.begin(), oldStudent.end(), newStudent.begin(), newStudent.end(),
std::back_inserter(leftStudent), [](auto& s1, auto& s2){ return s1.number < s2.number; });
std::cout << "离开的学生是";
// 离开的学生是10 30 60
std::copy(leftStudent.begin(), leftStudent.end(), std::ostream_iterator<StudentNum>(std::cout, " "));
}
或者利用std::set的有序性
struct StudentNum
{
int number;
// 初始化用
StudentNum(int _number) : number(_number) {}
// 输出迭代器用
StudentNum(const StudentNum&) = default;
// 集合计算用
bool operator<(const StudentNum& s) const { return number < s.number; }
// 输出用
friend std::ostream& operator<<(std::ostream& os, const StudentNum& studentNum) { return os << studentNum.number; }
};
int main()
{
// 利用set的有序性
std::set<StudentNum> oldStudent = {{40}, {20}, {50}, {10}, {30}, {60}};
std::set<StudentNum> newStudent = {{50}, {70}, {40}, {15}, {20}};
std::cout << "离开的学生是";
std::set_difference(oldStudent.begin(), oldStudent.end(), newStudent.begin(), newStudent.end(), std::ostream_iterator<StudentNum>(std::cout, " "));
}
set_intersection,计算两个有序序列的交集
std::set<std::string> myFriends{ "Mike", "Jane", "Jelly", "Zed" };
std::set<std::string> yourFriends{ "Mojo", "Tomas", "Mile", "Zed" };
std::cout << "our friend: ";
// Zed
std::set_intersection(myFriends.begin(), myFriends.end(), yourFriends.begin(), yourFriends.end(),
std::ostream_iterator<std::string>(std::cout, " "));
set_symmetric_difference,计算两个有序序列的对称差
$$
result = (A∪B)−(A∩B)
$$
std::vector<int> v1{ 1, 2, 3, 4, 5, 5, 5, 6, 7, 8 };
std::vector<int> v2{ 5, 7, 9, 10 };
// 1 2 3 4 5 5 6 8 9 10
std::set_symmetric_difference(v1.begin(), v1.end(), v2.begin(), v2.end(), std::ostream_iterator<int>(std::cout, " "));
set_union,计算两个有序序列的并集
std::vector<int> v1 = { 1, 2, 3, 4, 5, 5, 5 };
std::vector<int> v2 = { 3, 4, 5, 6, 7 };
// 1 2 3 4 5 5 5 6 7
std::set_union(v1.begin(), v1.end(), v2.begin(), v2.end(), std::ostream_iterator<int>(std::cout, " "));
sort系列
std::next_permutation
求一个递增序列的全排列
std::string name = "vim";
std::sort(name.begin(), name.end());
do
std::cout << name << std::endl;
while (std::next_permutation(name.begin(), name.end()));
// imv ivm miv mvi vim vmi
std::pre_permutation
去一个递减序列的全排列
std::string name = "vim";
std::sort(name.begin(), name.end(), greater<>{});
do
std::cout << name << std::endl;
while (std::prev_permutation(name.begin(), name.end()));
// vmi vim mvi miv ivm imv
std::nth_element
template<class RandomIt, class Compare >
void nth_element(RandomIt first, RandomIt nth, RandomIt last, Compare comp );
在first到last的序列中,使nth左半部分的值小于*nth,nth右半部分的值大于等于nth。*nth使序列中第nth-first大/小的数
std::random_device rd;
std::mt19937 g(rd());
std::uniform_int_distribution<int> dis(0, 10000);
// 数据量需要足够大
std::vector<int> v(2000);
std::generate(v.begin(), v.end(), std::bind(dis, std::ref(g)));
// "升序" 排列
std::nth_element(v.begin(), v.begin() + 1000, v.end());
for (auto i : v)
std::cout << i << std::endl;
std::partial_sort,对序列进行部分排序
std::partial_sort
// C++ 20
template<class RandomIt>
constexpr void partial_sort(RandomIt first, RandomIt middle, RandomIt last);
template<class RandomIt, class Compare>
constexpr void partial_sort(RandomIt first, RandomIt middle, RandomIt last, Compare comp);
假如我有一个10000个元素的数列,但是我只需要排列出前100位
std::random_device rd;
std::mt19937 g(rd());
std::uniform_int_distribution<int> dis(0, 10000);
std::vector<int> v(10000);
std::generate(v.begin(), v.end(), std::bind(dis, std::ref(g)));
std::partial_sort(v.begin(), v.begin() + 100, v.end());
for (int i = 0; i < 100; i++)
std::cout << v[i] << std::endl;
std::partial_sort_copy
将部分排序的结果储存到另一个容器中
std::vector<int> v0{ 4, 2, 5, 1, 3 };
std::vector<int> v1{ 10, 11, 12 };
std::vector<int> v2{ 10, 11, 12, 13, 14, 15, 16 };
// v1: 1 2 3
std::partial_sort_copy(v0.begin(), v0.end(), v1.begin(), v1.end());
// v2: 5 4 3 2 1 15 16
std::partial_sort_copy(v0.begin(), v0.end(), v2.begin(), v2.end(), std::greater<int>());
std::stable_sort
由于std::sort的底层会根据排序的数据量来选择归并排序,堆排序或快排。而堆排序或快排使不稳定的。因此某些情况下我们需要使用到稳定的std::stable_sort,它的底层实现是归并排序
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Sort_unchecked(_RanIt _First, _RanIt _Last, _Iter_diff_t<_RanIt> _Ideal, _Pr _Pred) {
// order [_First, _Last)
for (;;) {
if (_Last - _First <= _ISORT_MAX) { // small
_Insertion_sort_unchecked(_First, _Last, _Pred);
return;
}
if (_Ideal <= 0) { // heap sort if too many divisions
_Make_heap_unchecked(_First, _Last, _Pred);
_Sort_heap_unchecked(_First, _Last, _Pred);
return;
}
// divide and conquer by quicksort
auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred);
_Ideal = (_Ideal >> 1) + (_Ideal >> 2); // allow 1.5 log2(N) divisions
if (_Mid.first - _First < _Last - _Mid.second) { // loop on second half
_Sort_unchecked(_First, _Mid.first, _Ideal, _Pred);
_First = _Mid.second;
} else { // loop on first half
_Sort_unchecked(_Mid.second, _Last, _Ideal, _Pred);
_Last = _Mid.first;
}
}
}
std::sort_heap
由于堆的有序性,所以这个算法的本质是根据迭代器逐个弹出堆中元素,需要配合std::make_heap使用
order heap by repeatedly popping
pop *_First to *(_Last - 1) and reheap
从堆顶弹出元素,通过移动赋值塞到序列“末端”
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Sort_heap_unchecked(_RanIt _First, _RanIt _Last, _Pr _Pred) {
// order heap by repeatedly popping
for (; _Last - _First >= 2; --_Last) {
_Pop_heap_unchecked(_First, _Last, _Pred);
}
}
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Pop_heap_unchecked(_RanIt _First, _RanIt _Last, _Pr _Pred) {
// pop *_First to *(_Last - 1) and reheap
if (2 <= _Last - _First) {
--_Last;
_Iter_value_t<_RanIt> _Val = _STD move(*_Last);
_Pop_heap_hole_unchecked(_First, _Last, _Last, _STD move(_Val), _Pred);
}
}
测试样例
std::vector<std::string> vec{ "Mike", "Jelly", "Zed", "Jane", "Tomas", "Steve" };
std::make_heap(vec.begin(), vec.end());
// Zed Tomas Steve Jane Jelly Mike
for (auto& m : vec)
std::cout << m << " ";
std::cout << std::endl;
std::sort_heap(vec.begin(), vec.end());
// Jane Jelly Mike Steve Tomas Zed
for (auto& m : vec)
std::cout << m << " ";
initializer_list的浅拷贝
std::initializer_list的实现其实很简单
template <class _Elem>
class initializer_list {
public:
using value_type = _Elem;
using reference = const _Elem&;
using const_reference = const _Elem&;
using size_type = size_t;
using iterator = const _Elem*;
using const_iterator = const _Elem*;
constexpr initializer_list() noexcept : _First(nullptr), _Last(nullptr) {}
constexpr initializer_list(const _Elem* _First_arg, const _Elem* _Last_arg) noexcept
: _First(_First_arg), _Last(_Last_arg) {}
_NODISCARD constexpr const _Elem* begin() const noexcept {
return _First;
}
_NODISCARD constexpr const _Elem* end() const noexcept {
return _Last;
}
_NODISCARD constexpr size_t size() const noexcept {
return static_cast<size_t>(_Last - _First);
}
private:
const _Elem* _First;
const _Elem* _Last;
};
可以通过源码看出,std::initializer_list并没有实现拷贝构造函数,而C++默认提供的版本是浅拷贝的,也就是说在拷贝的过程中是指针的复制,而更重要的是,与STL中的其他容器不同,std::initializer_list<T>的迭代器是const T*,并且迭代器记录的数据是储存在栈上的,因此当它作为函数值返回的时候,访问其中的元素将会出现不确定的结果
std::initializer_list中维护了一个数组指针,而其指向的数组是储存在栈上的
std::initializer_list<int> create_inlist() {
// 浅拷贝
auto initList = {1, 2, 3};
return initList;
}
int main()
{
// 出现不确定的结果
for (auto i : create_inlist())
std::cout << i << std::endl;
}
如何访问initializer_list中的元素
除了for-range-loop外,我们还可以通过begin()来获取到迭代器,然后使用访问数组指针的方式来访问std::initializer_list中的元素
auto initList = { 1, 2, 3 };
for (int i = 0; i < initList.size(); i++)
std::cout << initList.begin()[i] << std::endl;
对于std::vector而言,容器本身重载了operator[],它的迭代器(random-access-iterator)也重载了operator[],因此
std::vector<int> initList = { 1, 2, 3 };
int data1 = initList[0]; // 1
int data2 = initList.begin()[1]; // 2
为什么vector使用的是push_back而不是push_front
因为vector中的数据在内存上是连续的,vector每次扩容的时候都会以当前大小的两倍去申请,也就是说在已经分配好内存的“末尾”添加一个元素是十分方便的。如果是从头进的话,那么代表vector里头的每个元素都要往后移动一位,也就意味着要执行数组当前容量次的拷贝操作,十分耗时耗空间
执行erase()会发生什么事情
移除单个元素的情况
class TestErase
{
public:
int data;
TestErase(int _data) : data(_data) { std::cout << "构造数据为" << data << "的类" << std::endl; }
TestErase(const TestErase& _copy) : data(_copy.data) { std::cout << "拷贝数据为" << data << "的类" << std::endl; }
TestErase& operator=(const TestErase& _copy)
{
data = _copy.data;
std::cout << "赋值数据为" << data << "的类" << std::endl;
return *this;
}
~TestErase() { std::cout << "析构数据为" << data << "的类" << std::endl; }
};
int main()
{
std::vector<TestErase> vec;
vec.reserve(5);
vec.emplace_back(1);
vec.emplace_back(2);
vec.emplace_back(2);
vec.emplace_back(3);
vec.emplace_back(2);
std::cout << "开始移除" << std::endl;
for (auto it = vec.begin(); it != vec.end();)
{
if (it->data == 2)
it = vec.erase(it);
else
it++;
}
for (auto& t : vec)
std::cout << t.data << std::endl;
}
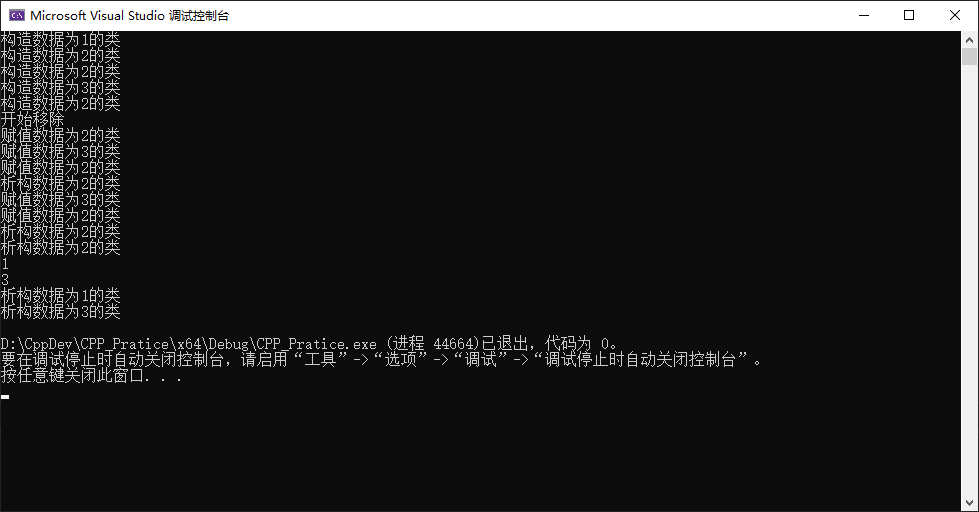
执行一次erase会发生的事情
- 获取传入的迭代器
- 将迭代器后的元素逐个往前移,调用到
operator= - 将
end指针往前移,然后释放end指针所指的内存 - 返回所清除的最后一个项的下一项(如果清除的是末尾,那么会返回
end)
移除多个元素的情况
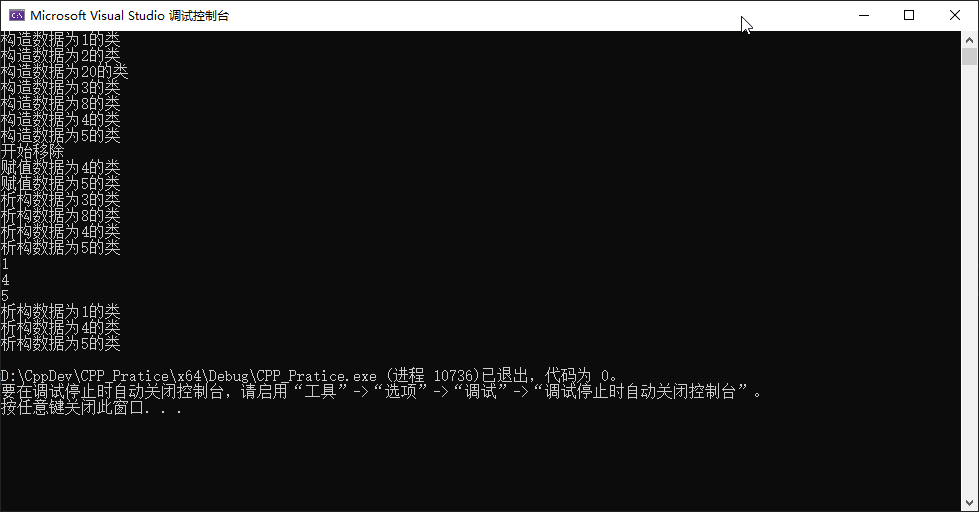
int main(){ std::vector<TestErase> vec; vec.reserve(7); vec.emplace_back(1); vec.emplace_back(2); vec.emplace_back(20); vec.emplace_back(3); vec.emplace_back(8); vec.emplace_back(4); vec.emplace_back(5); std::cout << "开始移除" << std::endl; auto first = ::find_if(vec.begin(), vec.end(), [](const auto& t) { return t.data == 2; }); auto last = ::find_if(vec.begin(), vec.end(), [](const auto& t) { return t.data == 4; }); // 前闭后开的区间 vec.erase(first, last); for (auto& t : vec) std::cout << t.data << std::endl;}
为什么std::push_back会有两个版本的重载
std::push_back中实现了const T&以及T&&两个版本的重载,而不是使用通用引用进行完美转发。
_CONSTEXPR20_CONTAINER void push_back(const _Ty& _Val) { // insert element at end, provide strong guarantee
emplace_back(_Val);
}
_CONSTEXPR20_CONTAINER void push_back(_Ty&& _Val) {
// insert by moving into element at end, provide strong guarantee
emplace_back(_STD move(_Val));
}
template <class... _Valty>
_CONSTEXPR20_CONTAINER decltype(auto) emplace_back(_Valty&&... _Val) {
// Codes...
}
知乎-c++中为什么push_back({1,2})可以,emplace_back({1,2})会报错?
随手贴两份错误实现代码,以后有机会会分析出错在哪里,能解决什么问题,不能解决什么问题
template<typename T>
inline std::enable_if_t<std::is_same_v<std::decay_t<T>, _Ty>, void> push_back(T&& _Val) {
emplace_back(std::forward<_Ty>(_Val));
}
template<typename T>
struct vec
{
template<std::convertible_to<T> U = T>
inline void push_back(T&& data) {
emplace_back(std::forward<T>(data));
}
};
什么时候需要使用std::list
- 当我们需要频繁的向头部插入或删除元素的时候
- 且我们不需要容器支持随机访问
list的结构是怎么样的
list是一个双向循环链表

为什么list要使用循环链表
对于常规的数据结构来说,循环链表的优点是:不论从哪个节点切入,都能成功遍历整个链表,而对于STL,个人见解:为了节省空间。
以下是我在IDE中按F12扒来的源码,VS2019
// list standard header
_NODISCARD iterator begin() noexcept {
return iterator(_Mypair._Myval2._Myhead->_Next, _STD addressof(_Mypair._Myval2));
}
_NODISCARD iterator end() noexcept {
return iterator(_Mypair._Myval2._Myhead, _STD addressof(_Mypair._Myval2));
}
使用循环链表,不需要在类中存储额外的指针指向头和尾。STL将_Myhead指向“虚无”的尾节点,而获取头节点的操作则直接对Head取next即可
list的初始头节点指向哪里,和end指向同一块空间吗
因为begin和end操作都会构造一个iterator(其实这里的iterator套了using之后的一种类型,暂且不深究)出来,从测试结果来看两者确实是相等的。
但是对于刚初始化时的_Myhead来说,它的next指向的是哪里呢?应该不是一个空类型,如果是的话,因为end的结果和begin相等,也就是说_Myhead也是个空类型,那么这个空类型是怎么获取到next的呢?本人暂时没有更深究list的源码,对这个问题并不清楚。
GCC2.9和GCC4.9中list的大小有什么区别,当前呢
从上面贴的list结构图里可以看出,GCC2.9中存的是一个指针,而指针指向的对象里头存放的是两个void类型的指针,一个是next一个是pre。不论是什么类型指针的大小都是4个字节。所以GCC2.9中list的大小是4
而GCC4.9中,通过一层一层的关系,放的其实是两个指针,所以GCC4.9中list的大小是8
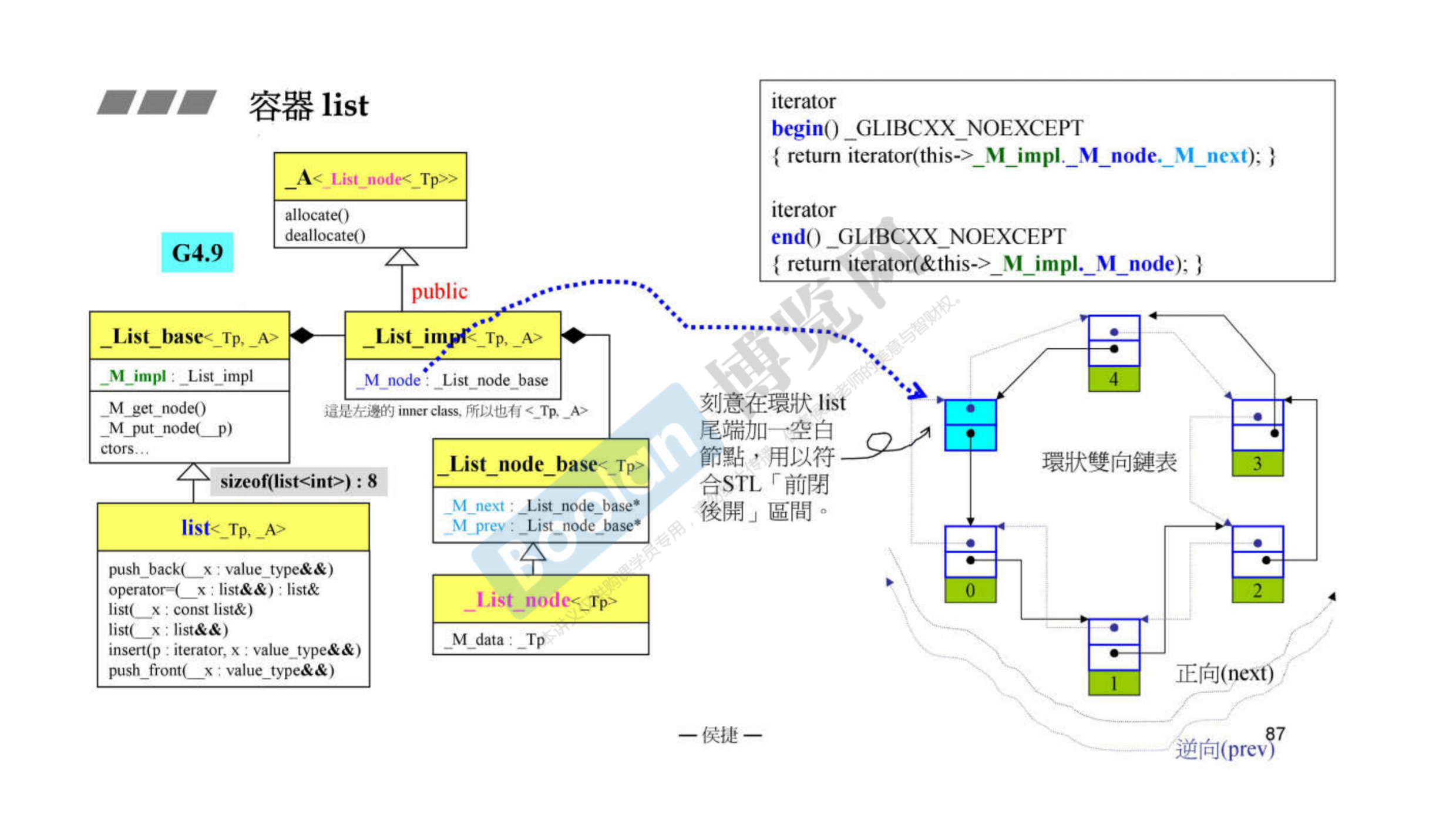
而我在当前的编辑器中对list进行sizeof操作,得到的结果是12
寄!
list和forward_list的end有什么区别
list的end指向的一个“虚无的”节点,也是整个循环链表的“头”,而forward_list指向的end可以看作是一个指向新建的空节点的iterator,与链表本身并无关系。forward_list是一个线形单向链表
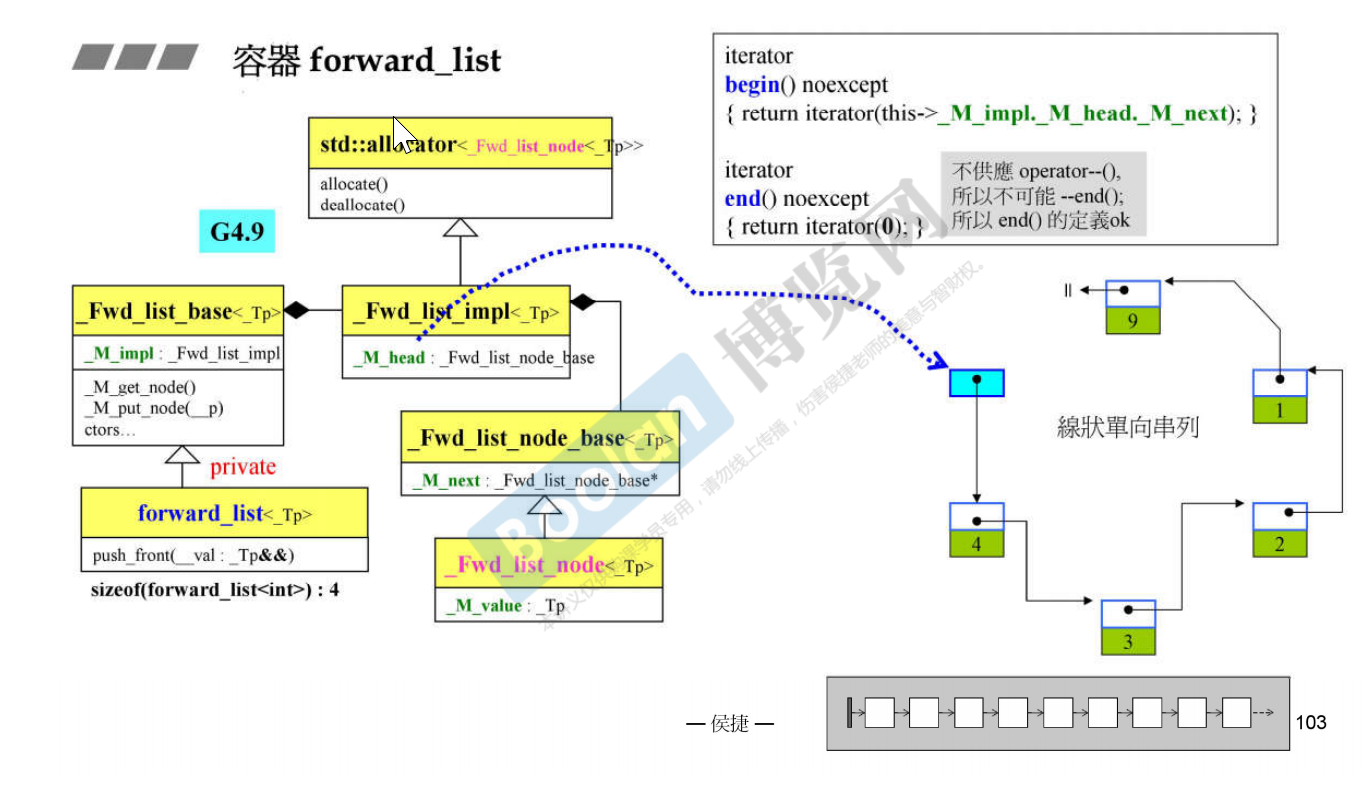
与list类似,forward_list的“头”仍然指向一个“虚无的”节点,对begin的获取则只需要取一位next即可。
GCC4.9版本中对forward_list的end指针的构造是直接传递0,而现VS2019使用MSVC版本则是传递一个nullptr,本质上是一样的
如何快速获取list的尾元素
应该不会有人直接暴力遍历一遍吧?
// 假设l为一个int的链表
cout << *(--l.end()) << endl;
既然list是循环链表,那么能通过尾巴的++操作访问到头部吗
据我目前所知,不能
list的迭代器支持++操作是否代表它是random-access-iterator
其实不是的,正如上文中说过的,random-access-iterator要求能对任意元素的访问达到O(1)的时间复杂度,std::list只是实现了对++,--运算符的重载
int main()
{
std::list<int> l{ 1, 2, 3, 4, 5, 6 };
for (auto it = l.cbegin(); it != l.cend(); ++it)
std::cout << *it << std::endl;
}
// 使用了无意义的int标识参数 所以重载的是后置 it++ 操作
_List_const_iterator operator++(int) noexcept {
_List_const_iterator _Tmp = *this;
++*this;
return _Tmp;
}
deque的优点是什么
deque结合了std::vector和std::list的优点
- 他能高效的从头部删除和插入元素,时间复杂度为O(1)
- 是随机访问迭代器
同时它作为其他adaptor类型的默认容器,如std::stack,std::queue。换句话说std::stack和std::queue的底层容器都是std::deque,它们只是在底层之上做了方法的封装
adaptor:适配器,比如lighting转type-c接口的adaptor就是负责转化功能
deque的结构是什么样的(待完成)
map,set等关联式容器相关问题std::set和std::map容器的key有什么要求
不管是单一的还是可重复的std::set/std::map,它们的底层实现都是红黑树,所以它们都是有序的。所以该容器要求其key类型实现operator<
std::set和std::map两者的迭代器有什么区别
共同点是它们都不是随机访问迭代器
std::set,std::multiset的对迭代器进行解引用,得到的是元素的引用
std::map, std::multimap对迭代器进行解引用,得到的是std::pair<key_type, value_type>的引用。std::pair比较时是字典序的
using Date = std::pair<int, std::pair<int, int>>;
// 可以实现一个有序的时期集合 升序
std::set<Date> dates;
dates.emplace(std::make_pair(1998, std::make_pair(12, 2)));
关联式容器的迭代器类型是什么
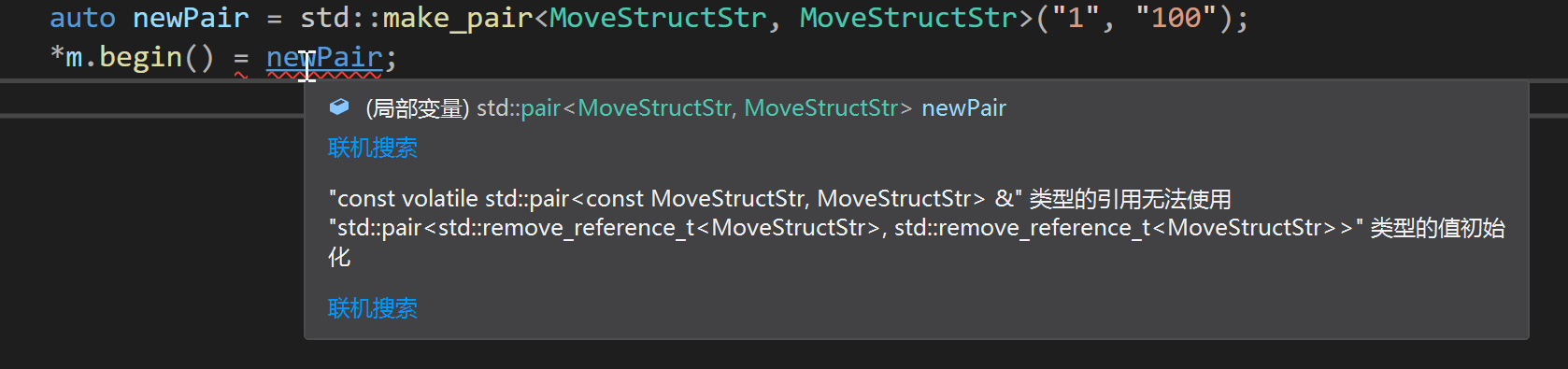
以std::map为例,它的迭代器解引用后的类型为
std::map<std::string, int> m;
// const volatile std::pair<const std::string, int>
*m.begin();
因此修改关联式容器中的键值对或key都是非法行为

API时间复杂度
insert/erase/count/find/lower_bound/upper_bound操作的时间复杂度都是O(log n)
insert操作返回的是什么
对于唯一元素容器来说(非multi,例如std::map,std::unordered_set),insert操作会返回std::pair<iterator, bool>
std::map<int, std::string> myMap;
std::map<int, std::string>::iterator iterator;
bool myBool;
auto returnPair = myMap.insert({ 1, "10" });
std::cout << std::boolalpha << returnPair.second << std::ends;
std::tie(iterator, myBool) = myMap.insert(std::make_pair(1, "100")); // 使用tie解包pair
std::cout << std::boolalpha << myBool << std::ends;
std::tie(std::ignore, myBool) = myMap.insert(std::make_pair(2, "100")); // 使用占位符
std::cout << std::boolalpha << myBool << std::ends;
// C++ 17
auto [newIterator, newBool] = myMap.insert(std::make_pair(3, "300"));
std::cout << std::boolalpha << newBool << std::endl;
输出结果为true false true true
注意,对于唯一容器而言,插入失败并不会返回{end(), false},而是会返回{oldIt, false},oldIt是操作的key的迭代器
std::map<int, int> m;
auto it1 = m.insert({1, 1});
auto it2 = m.insert({1, 2});
// 成立
if (it1.first == it2.first)
std::cout << "equal" << std::endl;
对于multi容器而言,insert操作会返回插入的新元素的迭代器
题外话
std::tie一般是和std::tuple搭配使用的,但是它也兼容std::pair。std::pair具有first和second能用于访问第一和第二元素,而std::tuple没有。
int myInt;
std::string myStr;
bool myBool;
// 通过上面三个变量访问tuple的数据 较为麻烦
std::tie(myInt, myStr, myBool) = std::make_tuple(1, "123", true);
// C++17
auto [newInt, newStr, newBool] = std::make_tuple(2, "456", false);
unorded_multimap和multimap怎么遍历他们中重复的元素
unorded_multimap
std::unordered_multimap<std::string, int> peopleMap = {{"Mike", 10}, {"Mike", 20}, {"Jelly", 18}, {"Mike", 15}, {"Zed", 23}};
using umpIterator = std::unordered_multimap<std::string, int>::iterator;
std::pair<umpIterator , umpIterator> range = peopleMap.equal_range("Mike");
for (auto it = range.first; it != range.second; ++it)
std::cout << it->first << std::ends << it->second << std::endl;
multimap
std::multimap<std::string, int> peopleMap = {{"Mike", 10}, {"Mike", 20}, {"Jelly", 18}, {"Mike", 15}, {"Zed", 23}};
std::iterator_traits<decltype(peopleMap.begin())>::value_type::first_type name = "Mike";
for (auto it = peopleMap.lower_bound(name); it != peopleMap.upper_bound(name); ++it)
std::cout << it->first << std::ends << it->second << std::endl;
一句话系列关联容器都含有成员函数
lower_bound和upper_bound
std::vector使用建议
- 当容器的size不大时,经过测试,即使有大量的插入操作,仍然建议使用std::vector,因为相比std::list而言它不需要内存的分配
- 如果想使用固定大小的数组,可以使用
std::array std::vector<bool>的实现是经过特化的,所以它的性能非常的好,可以当作bitmap来使用- STL中的容易已经实现了很好的移动构造以及移动赋值,所以可以放心的以值返回,不必担心有多余的拷贝操作