在掌握基于Weka工具的数据挖掘(分类、回归、聚类、关联规则分析)应用的基础上,实现基于Weka API的数据挖掘程序设计。
二、实验内容1.下载安装JDK 7.0 64位版,Weka 3.7版,Eclipse IDE for Java Developers 4.0以上版本。
2.基于Weka API的数据分类。
3.基于Weka API的数据回归。
4.基于Weka API的数据聚类。
5.基于Weka API的关联规则分析。
1.下载并安装JDK 7.0 64位版,Weka 3.7版,Eclipse IDE for Java Developers 4.0以上版本
(1)JDK与Weka的安装方法与实验1中相同。
(2)从http://www.eclipse.org/home/index.php 下载并安装Eclipse。
(3)在Eclipse中建立一个新的Java工程,用于放置实验程序的源代码。
(4)编程请遵循Java编程规范。规范中文版参见:
http://www.hawstein.com/posts/google-java-style.html。
2.基于Weka API的数据分类
(1)读取“电费回收数据.csv”。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
(b)调用特征选择算法(Select attributes),选择关键特征。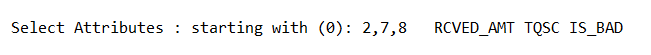
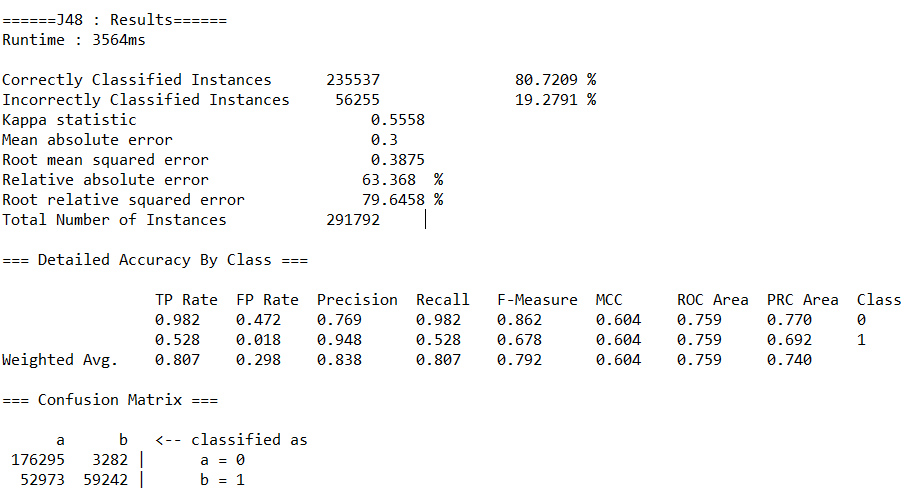
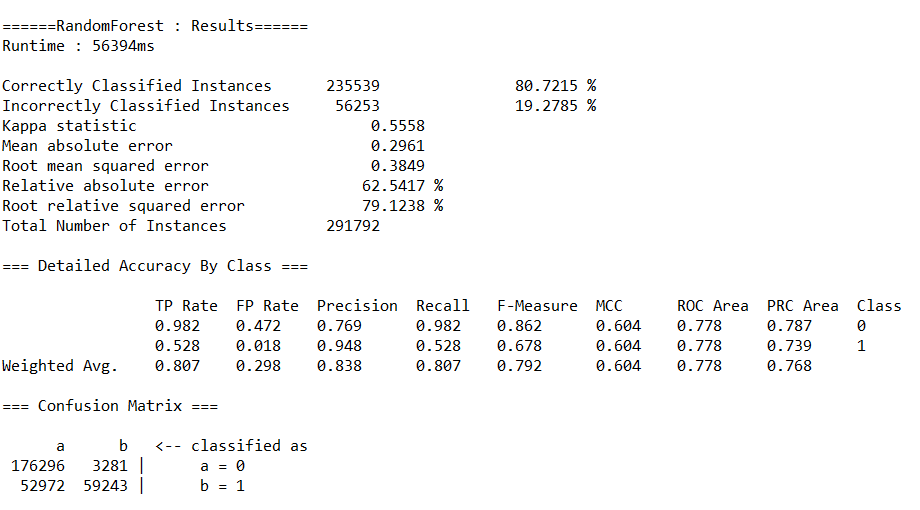
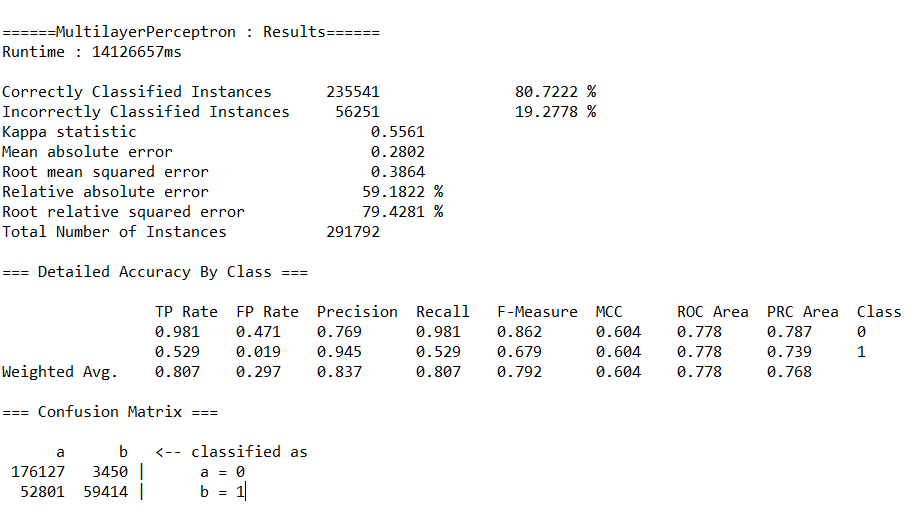
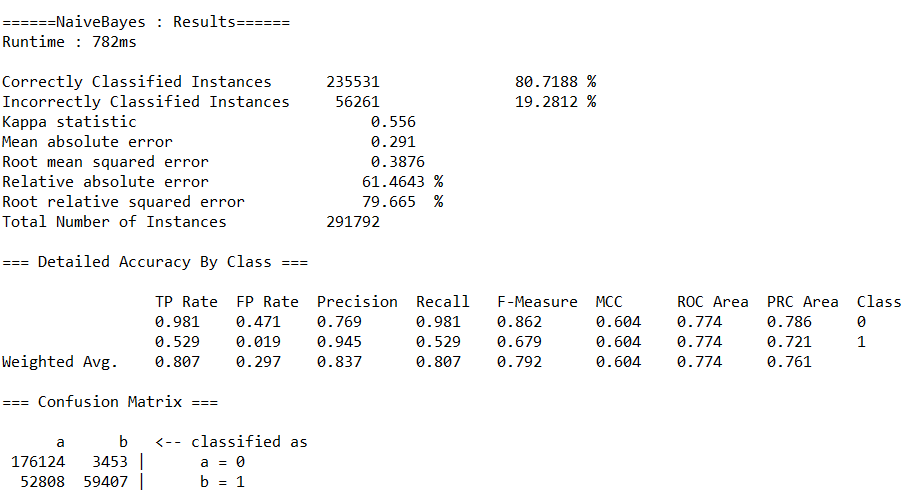
(3)分别调用决策树(J48)、随机森林(RandomForest)、神经网络(MultilayerPerceptron)、朴素贝叶斯(NaiveBayes)等算法的API,完成对预处理后数据的分类,取60%作为训练集。输出各算法的查准率(precision)、查全率(recall)、混淆矩阵与运行时间。
运行结果如下:
(a)决策树(J48)
(b)随机森林(RandomForest)
(c)神经网络(MultilayerPerceptron)
(d)朴素贝叶斯(NaiveBayes)
代码如下:
package weka;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Random;
import weka.attributeSelection.AttributeSelection;
import weka.attributeSelection.BestFirst;
import weka.attributeSelection.CfsSubsetEval;
import weka.classifiers.bayes.NaiveBayes;
import weka.classifiers.evaluation.Evaluation;
import weka.classifiers.functions.MultilayerPerceptron;
import weka.classifiers.trees.J48;
import weka.classifiers.trees.RandomForest;
import weka.core.Attribute;
import weka.core.Instances;
import weka.core.Utils;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Discretize;
import weka.filters.unsupervised.attribute.Normalize;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
/**
* 二、基于Weka API的数据分类
* @author 西瓜不甜
*
*/
public class Test_1 {
public static void main(String[] args) throws Exception {
/**
* 1.读取"电费回收数据.csv"
*/
Instances data = new Instances(new BufferedReader(new FileReader("C:\Users\西瓜不甜\Desktop\workspace\weka\电费回收数据.arff")));
/**
* 2.数据预处理
* (1)删除无用属性
*/
String[] options = new String[2];
options[0] = "-R"; // remove
options[1] = "1-2,7,10,12"; // "CONS_NO", "YMD", "RCVED_DATE", "CUISHOU_COUNT", "YM"
Remove remove = new Remove();
remove.setOptions(options);
remove.setInputFormat(data);
data = Filter.useFilter(data, remove); // apply filter
data.setClassIndex(data.numAttributes() - 1); // set class
/**
* 2.数据预处理
* (2)归一化
*/
Normalize norm = new Normalize();
norm.setInputFormat(data);
data = Filter.useFilter(data, norm);
/**
* 2.数据预处理
* (3)特征选择
*/
AttributeSelection attSelect = new AttributeSelection();
CfsSubsetEval eval = new CfsSubsetEval();
BestFirst search = new BestFirst();
attSelect.setEvaluator(eval);
attSelect.setSearch(search);
attSelect.SelectAttributes(data);
int[] indices = attSelect.selectedAttributes();
System.out.print("
Select Attributes : starting with (0): " + Utils.arrayToString(indices) + ' ');
for (int i = 0; i <indices.length; i++) {
int index = indices[i];
Attribute attribute = data.attribute(index);
System.out.print(attribute.name() + " ");
}
System.out.println();
/**
* 2.数据预处理
* (4) 离散化
*/
Discretize disc = new Discretize();
disc.setInputFormat(data);
data = Filter.useFilter(data, disc);
/**
* 2.数据预处理
* (5) 类型转换
*/
NumericToNominal nutono = new NumericToNominal();
nutono.setInputFormat(data);
data = Filter.useFilter(data, nutono);
/**
* 3.数据分类
* (0) 取60%为训练集,40%为测试集
*/
data.randomize(new Random(0));
int trainSize = (int) Math.round(data.numInstances() * 0.60);
int testSize = data.numInstances() - trainSize;
Instances train = new Instances(data, 0, trainSize);
Instances test = new Instances(data, trainSize, testSize);
long startTime, endTime;
Evaluation evaluation;
/**
* 3.数据分类
* (1)决策树(J48)
*/
startTime = System.currentTimeMillis();
J48 j48 = new J48(); // train classifier
j48.buildClassifier(train);
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(j48, test);
endTime = System.currentTimeMillis();
System.out.println(evaluation.toSummaryString("
======J48 : Results======
" + "Runtime : " + (endTime - startTime) + "ms
", false));
System.out.println(evaluation.toClassDetailsString());
System.out.println(evaluation.toMatrixString());
/**
* 3.数据分类
* (2)随机森林(RandomForest)
*/
startTime = System.currentTimeMillis();
RandomForest rf = new RandomForest(); // train classifier
rf.buildClassifier(train);
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(rf, test);
endTime = System.currentTimeMillis();
System.out.println(evaluation.toSummaryString("
======RandomForest : Results======
" + "Runtime : " + (endTime - startTime) + "ms
", false));
System.out.println(evaluation.toClassDetailsString());
System.out.println(evaluation.toMatrixString());
/**
* 3.数据分类
* (3)神经网络(MultilayerPerceptron)
* ps:运行时间约4h,谨慎运行。
*/
startTime = System.currentTimeMillis();
MultilayerPerceptron mp = new MultilayerPerceptron(); // train classifier
mp.buildClassifier(train);
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(mp, test);
endTime = System.currentTimeMillis();
System.out.println(evaluation.toSummaryString("
======MultilayerPerceptron : Results======
" + "Runtime : " + (endTime - startTime) + "ms
", false));
System.out.println(evaluation.toClassDetailsString());
System.out.println(evaluation.toMatrixString());
/**
* 3.数据分类
* (4)朴素贝叶斯(NaiveBayes)
*/
startTime = System.currentTimeMillis();
NaiveBayes nb = new NaiveBayes(); // train classifier
nb.buildClassifier(train);
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(nb, test);
endTime = System.currentTimeMillis();
System.out.println(evaluation.toSummaryString("
======NaiveBayes : Results======
" + "Runtime : " + (endTime - startTime) + "ms
", false));
System.out.println(evaluation.toClassDetailsString());
System.out.println(evaluation.toMatrixString());
}
}
3.基于Weka API的回归分析
(1)读取“配网抢修数据.csv”。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
(b)调用特征选择算法(Select attributes),选择关键特征。
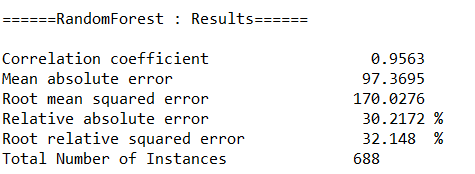
(3)分别调用随机森林(RandomForest)、神经网络(MultilayerPerceptron)、线性回归(LinearRegression)等算法的API对数据进行回归分析,取60%作为训练集。输出各算法的均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)与运行时间。
运行结果如下:
(a)随机森林(RandomForest)
(b)神经网络(MultilayerPerceptron)

(c)线性回归(LinearRegression)

代码如下:
package weka;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Random;
import weka.attributeSelection.AttributeSelection;
import weka.attributeSelection.BestFirst;
import weka.attributeSelection.CfsSubsetEval;
import weka.classifiers.evaluation.Evaluation;
import weka.classifiers.functions.LinearRegression;
import weka.classifiers.functions.MultilayerPerceptron;
import weka.classifiers.trees.RandomForest;
import weka.core.Attribute;
import weka.core.Instances;
import weka.core.Utils;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Discretize;
import weka.filters.unsupervised.attribute.Normalize;
import weka.filters.unsupervised.attribute.Remove;
/**
* 三、基于Weka API的回归分析
* @author 西瓜不甜
*
*/
public class Test_2 {
public static void main(String[] args) throws Exception {
/**
* 1.读取"配网抢修数据.csv"
*/
// load file
Instances data = new Instances(new BufferedReader(new FileReader("C:\Users\西瓜不甜\Desktop\workspace\weka\配网抢修数据.arff")));
/**
* 2.数据预处理
* (1)删除无用属性
*/
String[] options = new String[2];
options[0] = "-R"; // remove
options[1] = "1-2"; // YMD(年月日)、REGION_ID(地区编号)
Remove remove = new Remove();
remove.setOptions(options);
remove.setInputFormat(data);
data = Filter.useFilter(data, remove); // apply filter
data.setClassIndex(data.numAttributes() - 1); // set class
/**
* 2.数据预处理
* (2)归一化
*/
Normalize norm = new Normalize();
norm.setInputFormat(data);
data = Filter.useFilter(data, norm);
/**
* 2.数据预处理
* (3)特征选择
*/
AttributeSelection attSelect = new AttributeSelection();
CfsSubsetEval eval = new CfsSubsetEval();
BestFirst search = new BestFirst();
attSelect.setEvaluator(eval);
attSelect.setSearch(search);
attSelect.SelectAttributes(data);
int[] indices = attSelect.selectedAttributes();
System.out.print("
Select Attributes : starting with (0): " + Utils.arrayToString(indices) + ' ');
for (int i = 0; i <indices.length; i++) {
int index = indices[i];
Attribute attribute = data.attribute(index);
System.out.print(attribute.name() + " ");
}
System.out.println();
/**
* 2.数据预处理
* (4) 离散化
*/
Discretize disc = new Discretize();
disc.setInputFormat(data);
data = Filter.useFilter(data, disc);
/**
* 3.数据回归
* (0) 取60%为训练集,40%为测试集
*/
data.randomize(new Random(0));
int trainSize = (int) Math.round(data.numInstances() * 0.60);
int testSize = data.numInstances() - trainSize;
Instances train = new Instances(data, 0, trainSize);
Instances test = new Instances(data, trainSize, testSize);
/**
* 3.数据回归
* (1)随机森林(RandomForest)
*/
RandomForest rf = new RandomForest(); // train classifier
rf.buildClassifier(train);
Evaluation evaluation;
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(rf, test);
System.out.println(evaluation.toSummaryString("
======RandomForest : Results======
", false));
/**
* 3.数据回归
* (2)神经网络(MultilayerPerceptron)
*/
MultilayerPerceptron mp = new MultilayerPerceptron(); // train classifier
mp.buildClassifier(train);
evaluation = new Evaluation(test); // evaluate classifier and print some statistics
evaluation.evaluateModel(mp, test);
System.out.println(evaluation.toSummaryString("
======MultilayerPerceptron : Results======
", false));
/**
* 3.数据回归
* (3)线性回归(LinearRegression)
*/
LinearRegression lr = new LinearRegression(); // train classifier
lr.buildClassifier(train);
evaluation = new Evaluation(train); // evaluate classifier and print some statistics
evaluation.evaluateModel(lr, test);
System.out.println(evaluation.toSummaryString("
======LinearRegression : Results======
", false));
}
}
3.基于Weka API的回归分析
(1)读取“配网抢修数据.csv”。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
(b)调用特征选择算法(Select attributes),选择关键特征。
(3)分别调用随机森林(RandomForest)、神经网络(MultilayerPerceptron)、线性回归(LinearRegression)等算法的API对数据进行回归分析,取60%作为训练集。输出各算法的均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)与运行时间。
(a)随机森林(RandomForest)

(b)神经网络(MultilayerPerceptron)

(c)线性回归(LinearRegression)

4.基于Weka API的数据聚类
(1)读取“移动客户数据.tsv”(TAB符分隔列)。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
(b)调用特征选择算法(Select attributes),选择关键特征。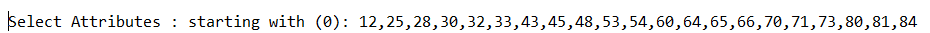
(3)分别调用K均值(SimpleKMeans)、期望值最大化(EM)、层次聚类(HierarchicalClusterer)等算法的API对数据进行聚类,输出各算法的聚类质量与运行时间。聚类质量根据以下2个指标计算:
a)Silhouette指标

b)S_Dbw指标
运行结果如下:
(a)K均值(SimpleKMeans)


(b)期望值最大化(EM)


(c)层次聚类(HierarchicalClusterer)
java.lang.OutOfMemoryError: Java heap space
代码如下:
package weka;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Random;
import weka.attributeSelection.AttributeSelection;
import weka.attributeSelection.BestFirst;
import weka.attributeSelection.CfsSubsetEval;
import weka.classifiers.evaluation.Evaluation;
import weka.classifiers.functions.LinearRegression;
import weka.classifiers.functions.MultilayerPerceptron;
import weka.classifiers.trees.RandomForest;
import weka.clusterers.ClusterEvaluation;
import weka.clusterers.EM;
import weka.clusterers.HierarchicalClusterer;
import weka.clusterers.SimpleKMeans;
import weka.core.Attribute;
import weka.core.Instances;
import weka.core.Utils;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Discretize;
import weka.filters.unsupervised.attribute.Normalize;
import weka.filters.unsupervised.attribute.Remove;
/**
* 四、 基于Weka API的数据聚类
* @author 西瓜不甜
*
*/
public class Test_3 {
public static void main(String[] args) throws Exception {
/**
* 1.读取"移动客户数据表.tsv"
*/
// load file
Instances data = new Instances(new BufferedReader(new FileReader("C:\Users\西瓜不甜\Desktop\workspace\weka\移动客户数据表.arff")));
/**
* 2.数据预处理
* (1)删除无用属性
*/
String[] options = new String[2];
options[0] = "-R"; // remove
options[1] = "1-4,72-73"; // SUM_MONTH、USER_ID、MSISDN、CUS_ID、MODEL_ID、LMODEL_ID
Remove remove = new Remove();
remove.setOptions(options);
remove.setInputFormat(data);
data = Filter.useFilter(data, remove); // apply filter
data.setClassIndex(data.numAttributes() - 1); // set class
/**
* 2.数据预处理
* (2)归一化
*/
Normalize norm = new Normalize();
norm.setInputFormat(data);
data = Filter.useFilter(data, norm);
/**
* 2.数据预处理
* (3)特征选择
*/
AttributeSelection attSelect = new AttributeSelection();
CfsSubsetEval eval = new CfsSubsetEval();
BestFirst search = new BestFirst();
attSelect.setEvaluator(eval);
attSelect.setSearch(search);
attSelect.SelectAttributes(data);
int[] indices = attSelect.selectedAttributes();
System.out.print("
Select Attributes : starting with (0): " + Utils.arrayToString(indices) + ' ');
for (int i = 0; i <indices.length; i++) {
int index = indices[i];
Attribute attribute = data.attribute(index);
System.out.print(attribute.name() + " ");
}
System.out.println();
/**
* 3.数据聚类
* (0)generate the class-less data to train the clusterer with(生成无类数据以训练聚类器)
*/
Remove filter = new Remove();
filter.setAttributeIndices("" + (data.classIndex() + 1));
filter.setInputFormat(data);
data = Filter.useFilter(data, filter);
/**
* 3.数据聚类
* (1)K均值(SimpleKMeans)
*/
long startTime, endTime;
ClusterEvaluation evaluation;
startTime = System.currentTimeMillis();
SimpleKMeans kmeans = new SimpleKMeans();
kmeans.buildClusterer(data);
evaluation = new ClusterEvaluation();
evaluation.setClusterer(kmeans);
evaluation.evaluateClusterer(data);
endTime = System.currentTimeMillis();
System.out.println(" Runtime : " + (endTime - startTime) + "ms
");
System.out.println(evaluation.clusterResultsToString());
/**
* 3.数据聚类
* (2)期望值最大化(EM)
* ps:运行时间约2h,谨慎运行。
*/
startTime = System.currentTimeMillis();
EM em = new EM();
em.buildClusterer(data);
evaluation = new ClusterEvaluation();
evaluation.setClusterer(em);
evaluation.evaluateClusterer(data);
endTime = System.currentTimeMillis();
System.out.println(" Runtime : " + (endTime - startTime) + "ms
");
System.out.println(evaluation.clusterResultsToString());
/**
* 3.数据聚类
* (3)层次聚类(HierarchicalClusterer)
* ps:设到 8g 也还是不行
*/
startTime = System.currentTimeMillis();
HierarchicalClusterer hc = new HierarchicalClusterer();
hc.buildClusterer(data);
evaluation = new ClusterEvaluation();
evaluation.setClusterer(hc);
evaluation.evaluateClusterer(data);
endTime = System.currentTimeMillis();
System.out.println(" Runtime : " + (endTime - startTime) + "ms
");
System.out.println(evaluation.clusterResultsToString());
}
}
5.基于Weka API的关联规则分析
(1)读取“配网抢修数据.csv”。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
(b)调用特征选择算法(Select attributes),选择关键特征。
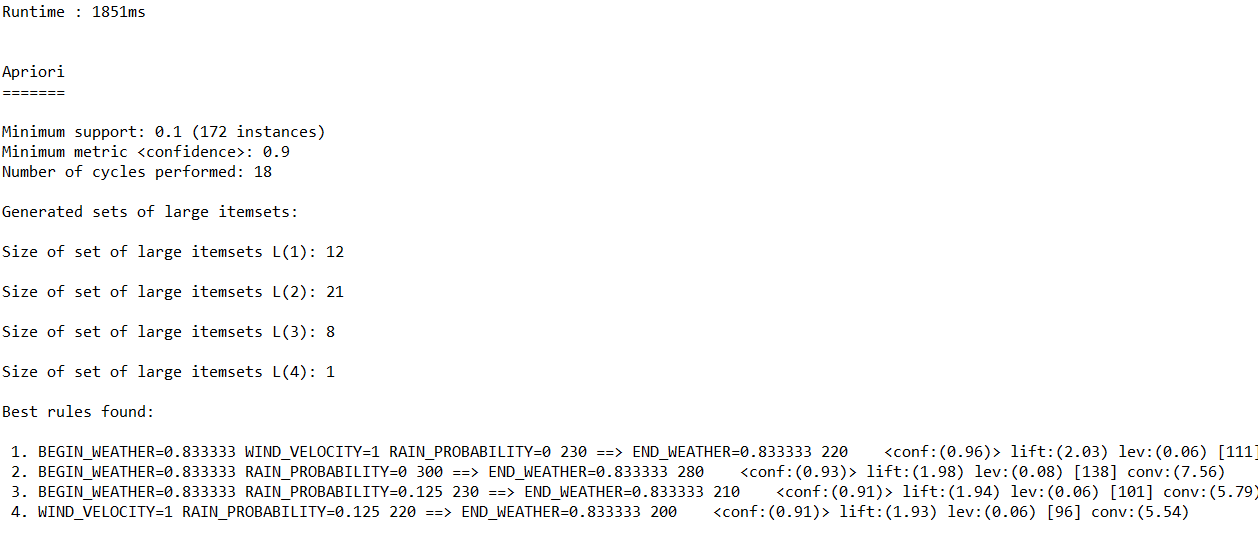
(3)调用Apriori算法对数值型字段进行关联规则分析,输出不同置信度(confidence)下算法生成的规则集。
运行结果如下:
(a)置信度:0.9
(b)置信度:0.6
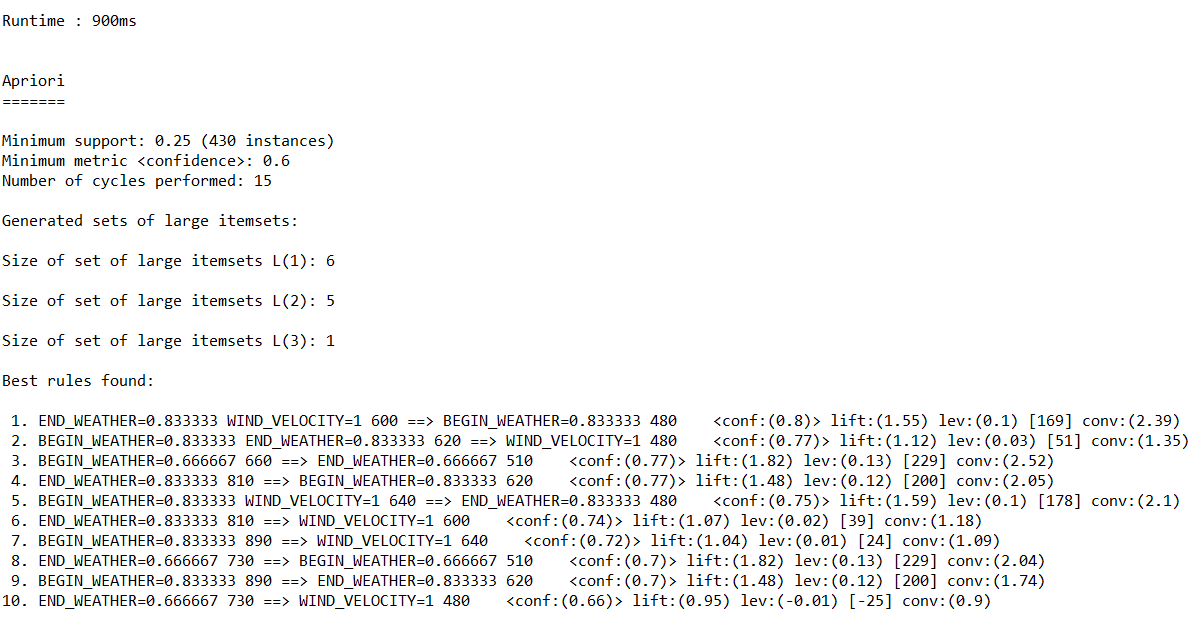
(c)置信度:0.4
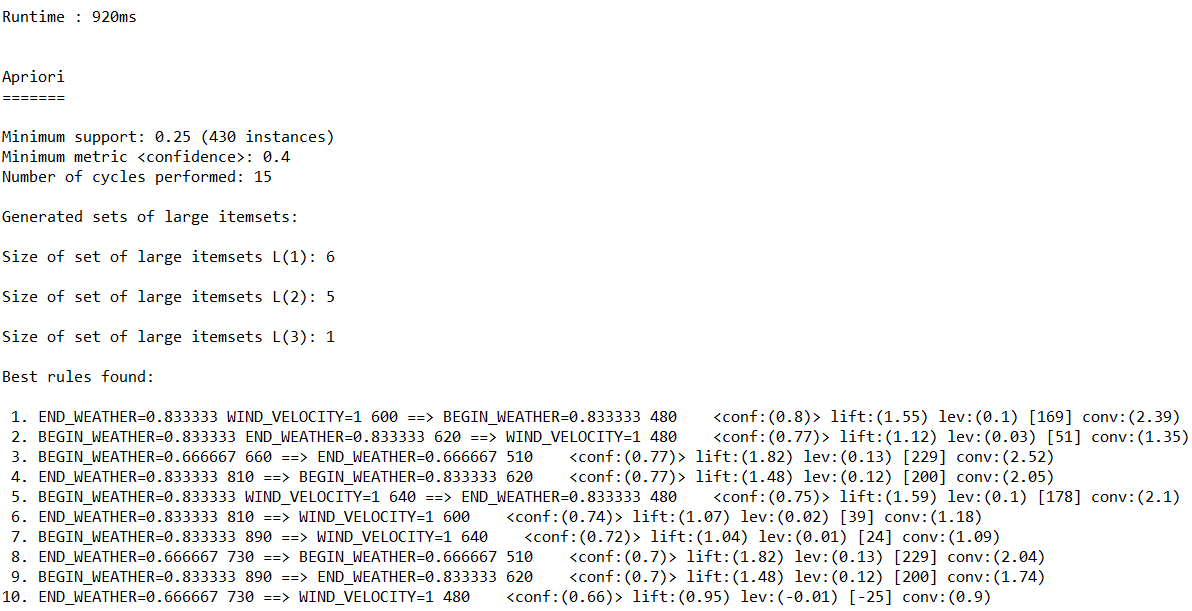
代码如下:
package weka;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Random;
import weka.associations.Apriori;
import weka.attributeSelection.AttributeSelection;
import weka.attributeSelection.BestFirst;
import weka.attributeSelection.CfsSubsetEval;
import weka.classifiers.evaluation.Evaluation;
import weka.classifiers.functions.LinearRegression;
import weka.classifiers.functions.MultilayerPerceptron;
import weka.classifiers.trees.RandomForest;
import weka.core.Attribute;
import weka.core.Instances;
import weka.core.Utils;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Discretize;
import weka.filters.unsupervised.attribute.Normalize;
import weka.filters.unsupervised.attribute.NumericToNominal;
import weka.filters.unsupervised.attribute.Remove;
/**
* 五、基于Weka API的关联规则分析
* @author 西瓜不甜
*
*/
public class Test_4 {
public static void useApriori(double confidence , Instances data) throws Exception {
long startTime, endTime;
startTime = System.currentTimeMillis();
Apriori apriori = new Apriori();
String[] options = new String[2];
options[0] = "-C";
options[1] = Double.toString(confidence);
apriori.setOptions(options);
apriori.buildAssociations(data);
endTime = System.currentTimeMillis();
System.out.println("
Runtime : " + (endTime - startTime) + "ms
");
System.out.println(apriori);
}
public static void main(String[] args) throws Exception {
/**
* 1.读取"配网抢修数据.csv"
*/
// load file
Instances data = new Instances(new BufferedReader(new FileReader("C:\Users\西瓜不甜\Desktop\workspace\weka\配网抢修数据.arff")));
/**
* 2.数据预处理
* (1)删除无用属性
*/
String[] options = new String[2];
options[0] = "-R"; // remove
options[1] = "1-2"; // YMD(年月日)、REGION_ID(地区编号)
Remove remove = new Remove();
remove.setOptions(options);
remove.setInputFormat(data);
data = Filter.useFilter(data, remove); // apply filter
data.setClassIndex(data.numAttributes() - 1); // set class
/**
* 2.数据预处理
* (2)归一化
*/
Normalize norm = new Normalize();
norm.setInputFormat(data);
data = Filter.useFilter(data, norm);
/**
* 2.数据预处理
* (3)特征选择
*/
AttributeSelection attSelect = new AttributeSelection();
CfsSubsetEval eval = new CfsSubsetEval();
BestFirst search = new BestFirst();
attSelect.setEvaluator(eval);
attSelect.setSearch(search);
attSelect.SelectAttributes(data);
int[] indices = attSelect.selectedAttributes();
System.out.print("
Select Attributes : starting with (0): " + Utils.arrayToString(indices) + ' ');
for (int i = 0; i <indices.length; i++) {
int index = indices[i];
Attribute attribute = data.attribute(index);
System.out.print(attribute.name() + " ");
}
System.out.println();
/**
* 2.数据预处理
* (4) 类型转换
*/
NumericToNominal nutono = new NumericToNominal();
nutono.setInputFormat(data);
data = Filter.useFilter(data, nutono);
/**
* 3.关联规则分析
* 置信度 0.9、0.6、0.4
*/
useApriori(0.9 , data);
useApriori(0.6 , data);
useApriori(0.4 , data);
}
}