JDBC相关概念
JAVA程序都是通过JDBC连接数据库的,通过SQL对数据库编程,JDBC是由SUN公司提出的一些列规范,只定义了接口规范,具体实现由各个数据库厂商去实现,它是一种典型的桥接模式。
桥接模式是一种结构型设计模式,它的主要特点是把抽象与行为实现分离开来,分别定义接口,可以保持各部分的独立性以及应对他们的功能扩展。
JDBC规范
所谓规范,就是自己定义了标准接口,如:用Connection代表和数据库的连接,用Statement执行SQL,用ResultSet表示SQL返回的结果,提供了对数据的便利。从Connection可以创建Statement,Statement执行查询得到ResultSet。
上面说的Connection、Statement、ResultSet都应该是接口,具体实现由各个数据库提供商提供。有了规范,可以通过统一的接口,访问多种类型的数据库,可随便切换数据库。
数据库驱动
接口的实现由各个厂商提供,那么实现类的类名就会不统一,去创建Connection对象时,代码就会写死某个实现类,切换数据库时,就需要修改代码,这样不太好。为了解决这个问题,抽象了Driver驱动的概念。

每个数据库都需要实现Driver接口,通过Driver可获得数据库连接Connection,通过反射机制动态创建。

同一个程序可能访问不同的数据库,通过DriverManager来管理驱动,Driver在初始化的时候,需要注册到DriverManager中。
DriverManager提供了一个getConnection方法,用于建立数据库Connection:

如果有多个数据库驱动,DriverManager如何区分呢,需要在数据库连接url中指定,比如mysql需要添加jdbc:mysql前缀:

数据源
数据源DataSource包含连接池和连接池管理2个部分,习惯上称为连接池。在系统初始化的时候,将数据库连接作为对象存储在内存中,当需要访问数据库时,从连接池中取出一个已建立的空闲连接对象。
使用数据源,获取其DataSource对象,通过该对象动态的获取数据库连接。另外,DataSource对象可以注册到名字服务(JNDI)中,可以通过名字服务获得DataSource对象,无需硬性编码驱动。
DriverManager是JDBC1提供的,DataSource是JDBC2新增的功能,提供了更好的连接数据源的方法。
JDBC程序
Public static voidmain(String[] args) { Connection connection = null; PreparedStatement preparedStatement = null; ResultSet resultSet = null; try{ //1.加载数据库驱动 Class.forName("com.mysql.jdbc.Driver"); //2.通过驱动管理类获取数据库链接 connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8", "root", "mysql"); //3.定义sql语句 ?表示占位符 String sql = "select * from user where username = ?"; //4.获取预处理statement preparedStatement =connection.prepareStatement(sql); //5.设置参数,第一个参数为sql语句中参数的序号(从1开始),第二个参数为设置的参数值 preparedStatement.setString(1, "王五"); //6.向数据库发出sql执行查询,查询出结果集 resultSet =preparedStatement.executeQuery(); //7.遍历查询结果集 while(resultSet.next()){ System.out.println(resultSet.getString("id")+" "+resultSet.getString("username")); } } catch(Exception e) { e.printStackTrace(); }finally{ //8.释放资源 if(resultSet!=null){ try{ resultSet.close(); } catch(SQLException e) { //TODO Auto-generated catch block e.printStackTrace(); } } if(preparedStatement!=null){ try{ preparedStatement.close(); } catch(SQLException e) { //TODO Auto-generated catch block e.printStackTrace(); } } if(connection!=null){ try{ connection.close(); } catch(SQLException e) { //TODO Auto-generated catch block e.printStackTrace(); } } } }
JDBC编程步骤
1、加载数据库驱动
2、创建并获取数据库链接
3、创建JDBCstatement对象
4、设置SQL语句
5、设置SQL语句中的参数(使用preparedStatement)
6、通过statement执行SQL并获取结果
7、对SQL执行结果进行解析处理
8、释放资源(resultSet、preparedstatement、connection)
JDBC存在的问题
1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
2、SQL语句在代码中硬编码,造成代码不易维护,实际应用SQL变化的可能较大,SQL变动需要改变JAVA代码。
3、使用PreparedStatement向占有位符号传参数存在硬编码,因为SQL语句的where条件不一定,可能多也可能少,修改SQL还要修改代码,系统不易维护。
4、对结果集解析存在硬编码(查询列名),SQL变化导致解析代码变化,系统不易维护,如果能将数据库记录封装成POJO对象解析比较方便。
MyBatis介绍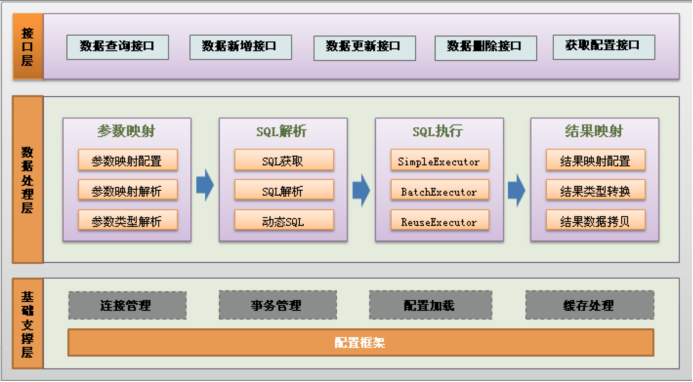
MyBatis 本是Apache的一个开源项目iBatis, 2010年这个项目由Apache Software Foundation迁移到了Google Code,并且改名为MyBatis 。2013年11月迁移到Github。
MyBatis是一个优秀的持久层框架,它对JDBC的操作数据库的过程进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建Connection、创建Statement、手动设置参数、结果集检索等JDBC繁杂的过程代码。
Mybatis通过xml或注解的方式将要执行的各种statement(statement、preparedStatemnt、CallableStatement)配置起来,并通过java对象和statement中的SQL进行映射生成最终执行的sql语句,最后由MyBatis框架执行SQL并将结果映射成java对象并返回。
对比Hibernate和MyBatis
传统的JDBC编程给我们带来了连接数据库的功能,但其工作量相对较大,首先连接,然后处理JDBC底层事务,处理数据类型,还要对可能产生的异常进行捕捉处理并正确的关闭资源。
实际工作中,很少使用JDBC进行编程,提出了ORM模型,主要解决数据库数据和POJO对象的相互映射。
Hibernate和Mybatis都是ORM模型,Hibernate提供的是一种全表映射的模型,对JDBC的封装程度比较高。但Hibernate也有不少缺点,列举如下:
- l全表映射带来的不便,比如更新时需要发送所有的字段;
- l无法根据不同的条件组装不同的SQL;
- l对多表关联和复杂SQL查询支持较差,需要自己写SQL,返回后,需要自己将数据组装为POJO;
- l不能有效支持存储过程;
- l虽然有HQL,但性能较差,大型互联网系统往往需要优化SQL,而Hibernate做不到。
大型互联网环境中,灵活、SQL优化,减少数据的传递是最基本的优化方法,Hibernate无法满足要求,而MyBatis提哦给你了灵活、方便的方式,是一个半自动映射的框架。
MyBatis需要手工匹配提供POJO、SQL和映射关系,而全表映射的Hibernate只需要提供POJO和映射关系。
MyBatis可以配置动态SQL,可以解决Hibernate的表名根据时间变化,不同的条件下列明不一样的问题。可以优化SQL,通过配置决定SQL映射规则,也能支持存储过程,对于一些复杂和需要优化性能的SQL的查询它更加方便。
核心组件
核心组件主要包括以下几个:
- lSqlSessionFactoryBuilder:会根据配置信息或代码来生成SqlSessionFactory;
- lSqlSessionFactory:依靠工厂来生成SqlSession;
- lSqlSession:是一个既可以发送SQL去执行并返回结果,也可以获取Mapper的接口;
- lSQL Mapper:是MyBatis新设计的组件,由一个Java接口和XML文件构成,需要给出对应的SQL和映射规则。它负责发送SQL去执行,并返回结果。
组件生命周期
SqlSessionFactory在MyBatis应用的整个生命周期中,每个数据库只对应一个SqlSessionFactory,可以实现一个工具类,以单例模式获取该对象。
SqlSession的生命周期在请求数据库处理事务的过程中,它是一个线程不安全的对象,在涉及多线程的时候要特别当心。它存活于一个应用的请求和操作,可以执行多条SQL,保证事务的一致性。
Mapper的作用是发送SQL,然后返回需要的结果,或者执行SQL修改数据库的数据,所以它应该在一个SqlSession事务方法之内,如同JDBC中一条SQL语句的执行,它最大的范围和SqlSession是相同的。
MyBatis配置<?xml version="1.0" encoding="UTF-8"?> <configuration> <properties/> <settings/> <typeAliases/> <typeHandles/> <objectFactory/> <plugins/> <environments> <environment> <transanctionManager/> <!-- 配置事务管理器 --> <dataSource/> <!-- 配置数据源 --> </environment> </environments> <databaseIdProvider/> <!-- 数据库厂商标识 --> <mappers/> <!-- 映射器 --> </configuration>
properties元素
将一些公用、经常变更的值单独声明,能在配置文件的上下文中使用它,MyBatis提供了3种配置方式:
- lproperty子元素
- lproperties配置文件
- l程序参数传递
property子元素
<properties>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mi-user"/>
<property name="username" value="root"/>
<property name="pwd" value="123456"/>
</properties>properties配置文件
创建一个配置文件 jdbc.properties
driver =com.mysql.jdbc.Driver url = jdbc:mysql://localhost:3306/mi-user username =root password = 123456
设置properties配置文件
<properties resource='jdbc.properties' />
程序参数传递
实际工作中,会遇到这种场景:系统由运维人员配置,生成数据库的密码对开发者是保密的,对用户名和密码进行了加密。可以通过程序参数传递的方式,先解密,再设置property。
//读入配置文件流 InputStream cfgStream = Resources.getResourceAsStream("mybatis-config.xml"); Reader cfgReader = newInputStreamReader(cfgStream); //读入属性文件流 InputStream proStream = Resources.getResourceAsStream("jdbc.properties"); Reader proReader = newInputStreamReader(proStream); Properties properties = newProperties(); properties.load(proReader); //转换为明文 properties.setProperty("username",decode(properties.getProperty("username"))); properties.setProperty("pwd",decode(properties.getProperty("pwd"))); //创建sqlSessionFactory SqlSessionFactory sqlSessionFactory=new SqlSessionFactoryBuilder().build(cfgReader,properties);
如果3种配置同时出现,优先级为第3种 > 第2种 > 第1种,推荐使用第2种,有特殊需求时使用第3种。
常用配置项
只介绍几个常用的配置项,想了解更多请查看官方文档。
- lcacheEnabled:全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存,默认为true;
- llazyLoadingEnabled:延迟加载的全局开关,当开启时,所有关联对象都会延迟加载,特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态,默认为false;
- laggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载,3.4.1版本之前默认为true,3.4.1之后默认为false;
- lautoMappingBehavior:指定MyBatis应如何自动映射列到字段或属性,NONE 表示取消自动映射,PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集,FULL 会自动映射任意复杂的结果集,默认为PARTIAL;
- lautoMappingUnknownColumnBehavior:指定发现自动映射目标未知列(或者未知属性类型)的行为,NONE: 不做任何反应,WARNING: 输出提醒日志,FAILING: 映射失败,默认为NONE;
- ldefaultStatementTimeout:设置超时时间,它决定驱动等待数据库响应的秒数;
- lmapUnderscoreToCamelCase:是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射,默认为false;
- ldefaultEnumTypeHandler:指定 Enum 使用的默认 TypeHandler,默认为org.apache.ibatis.type.EnumTypeHandler;
- lreturnInstanceForEmptyRow:当返回行的所有列都是空时,MyBatis默认返回null。 当开启这个设置时,MyBatis会返回一个空实例,默认为false;
- llocalCacheScope:MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据,默认为SESSION;
- llogImpl:指定日志的具体实现,比如SLF4J|LOG4J|COMMONS_LOGGING等;
别名
在配置映射文件中,需要指定类的全限定名,为了简化,可以声明一个简短的名称去指代它,可以在MyBatis上下文中使用。系统已经为我们定义了常用的类型,比如数值、字符串、日期、集合等。对于自定义的业务POJO,需要自定义别名。
<typeAliases>
<typeAlias alias="role" type="com.learn.chapter2.po.Role"/>
</typeAliases>也可以通过注解方式进行,首先配置一个扫描的包,然后在类定义时添加注解@Alias("role")。
<typeAliases>
<package name="com.learn.chapter2.po" />
</typeAliases>
@Alias("role")
public classRole{
}类型处理器
MyBatis在预处理语句中设置一个参数时,或者从结果集中取出一个值时,都会用注册了的typeHader进行处理。typeHander的作用就是将参数从javaType转化为jdbcType,或者从数据库取出结果时把jdbcType转化为javaType。
系统内部已经定义了常用的类型处理器,有些情况下,需要自定义。
MyBatis也提供了枚举类型的类型处理器,有2个转化枚举类型的typeHandler,EnumTypeHandler和EnumOrdinalTypeHandler,其中EnumTypeHandler是使用枚举字符串名称作为参数传递的,EnumOrdinalTypeHandler是使用整数下标作为参数传递的。
但这2个枚举类型应用不那么广泛,更多的时候,需要自定义typeHandler进行处理。
自定义类型处理器,首先要定义类型处理类,实现TypeHandler泛型接口:
public class SexEnumTypeHandler implements TypeHandler<Sex>{ @Override public void setParameter(PreparedStatement ps, inti, Sex sex, JdbcType jdbcType) throws SQLException { ps.setInt(i, sex.getId()); } @Override publicSex getResult(ResultSet rs, String name) throws SQLException { returnSex.getSex(rs.getInt(name)); } @Override public Sex getResult(ResultSet rs, intid) throws SQLException { returnSex.getSex(id); } @Override public Sex getResult(CallableStatement cs, intid) throws SQLException { returnSex.getSex(cs.getInt(id)); } }
然后注册自定义的TypeHandler
<typeHandlers> <typeHandler handler="com.qqdong.study.SexEnumTypeHandler" javaType="sex"/> </typeHandlers>
最后,在定义映射器时,指定typeHandler即可
<select id="getUser" parameterType="long" resultType="userMap"> </select> <resultMap id="userMap" type="user"> <result column="sex" property="sex" typeHandler="com.qqdong.study.SexEnumTypeHandler"> </resultMap>
ObjectFactory
当MyBatis在构建一个结果返回的时候,都会使用ObjectFactory去构建POJO,在MyBatis中可以定制自己的对象工厂。一般不用配置,使用默认的DefaultObjectFactory即可。
environments配置环境
配置环境可以注册多个数据源,每个数据源包括基本配置和数据库事务配置。
<environments default="development"> <environment id="development"> <!-- 采用jdbc事务管理 --> <transactionManager type="JDBC"> <property name="autoCommit" value="false"> </transactionManager> <dataSource type="POOLED"> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments>
其中,transactionManager指定数据库事务,有3种配置方法:
- lJDBC,采用JDBC方式管理事务,在独立编码中常常使用;
- lMANAGED,采用容器方式管理事务,在JNDI数据源中常用;
- l自定义,由使用者自定义数据库事务管理方法;
- DataSource标签,配置数据源连接信息,type配置对数据库连接方式,有以下几种:
- lUNPOOLED:非连接池数据库;
- lPOOLED:连接池数据库;
- lJNDI:JNDI数据源;
- l自定义数据源;
映射器是由Java接口和XML文件(或注解)共同组成的,作用如下:
- l定义参数类型
- l描述缓存
- l描述SQL语句
- l定义查询结果和POJO的映射关系
首先,定义Java接口:
public interfaceRoleMapper{ publicRole getRole(Long id); }
然后,定义映射XML文件,RoleMapper.xml
<? xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <mapper namespace ="com.learn.chapter2.mapper.RoleMapper"> <select id="getRole" paramterType="long" resultType="role" > select id,role_name as roleName , note from t_role where id=#{id} </select> </mapper>
POJO对象Role的定义比较简单,就不列出了。#{id}为这条SQL的参数,SQL列的别名和POJO的属性名称保持一致,会把这条语句的查询结果自动映射到Role属性上,这就是自动映射。执行查询:
RoleMapper roleMapper=sqlSession.getMapper(RoleMapper.class); Role role=roleMapper.getRole(1L); String roleName=role.getRoleName();
通过映射器,可以很容易的进行数据的增删改查操作,我们抽象下进行这些操作的关键点:传递查询参数、组装各种场景下的查询条件、关联查询、将查询结果映射为Java Bean对象或集合等。另外,可以通过延迟加载、缓存提高数据查询的性能。
映射器的主要元素
映射器是由Java接口和XML文件(或注解)共同组成的,Java接口主要定义调用者接口,XML文件是配置映射器的核心文件,包括以下元素:
- lselect 查询语句,可以自定义参数,返回结果集;
- linsert 插入语句,返回一个整数,表示插入的条数;
- lupdate 更新语句,返回一个整数,表示更新的条数;
- ldelete 删除语句,返回一个整数,表示删除的条数;
- lsql 允许定义一部分SQL,然后再各个地方引用;
- lresultMap 用来描述从数据库结果集中来加载对象,还可以配置关联关系;
- lcache 给定命名空间的缓存配置;
增、删、改、查操作
查找
执行select语句前,需要定义参数,执行后,也提供了强大的映射规则或自动映射,将返回的结果集绑定到java bean中。
select元素有很多配置项,下面简单说明下:
- lparamterType:传入的参数类型,可以是基本类型、map、自定义的java bean;
- lresultType:返回的结果类型,可以是基本类型、自定义的java bean;
- lresultMap:它是最复杂的元素,可以配置映射规则、级联、typeHandler等,与ResultType不能同时存在;
- lflushCache:在调用SQL后,是否要求清空之前查询的本地缓存和二级缓存,主要用于更新缓存,默认为false;
- luseCache:启动二级缓存的开关,默认只会启动一级缓存;
- ltimeout:设置超时参数,等超时的时候将抛出异常,单位为秒;
- lfetchSize:获取记录的总条数设定;
比如根据米聊号获取用户信息:
<select id="findByMiliao" parameterType="string" resultType="User"> select u.* frommxt_user u where u.miliao=#{miliao} </select>
设置项autoMappingBehavior,默认为自动映射没有定义嵌套结果集映射的结果集;还有设置项mapUnderscoreToCamelCase,设置为true时,会自动将以「下划线」命名的数据库字段名,自动映射为以「驼峰式」命名的POJO。
传递多个参数时,有3种方式:
- l使用Map参数;
- l使用注解方式传递;
- l使用java bean;
使用注解方式如下:
public List<Role> findRoleByNameAndNote(@Param("roleName") String rolename, @Param("note") String note);
使用Map传递参数,会导致业务可读性丧失,导致以后扩展和维护不方便,不建议;如果参数个数<=5,建议使用注解的方式,因为过多参数将给调用者带来困难;如果参数个数>5,建议使用JavaBean方式;
insert
属性和select大部分都相同, 说下3个不同的属性:
- lkeyProperty:指定哪个列是主键,如果是联合主键可以用逗号隔开;
- lkeyColumn:指定第几列是主键,不能和keyProperty共用;
- luseGeneratedKeys:是否使用自动增长,默认为false;
- l当useGeneratedKeys设为true时,在插入的时候,会回填Java Bean的id值,通过返回的对象可获取主键值。
如果想根据一些特殊关系设置主键的值,可以在insert标签内使用selectKey标签,比如:如果t_role没有记录,则需要设置为1,否则取最大id加2:
<insert id="insertRole" useGeneratedKeys="true" keyProperty="id" > <selectKey keyProperty="id" resultType="int" order="before"> select if(max(id) is null,1,max(id)+2) as newId fromt_role </selectKey> </insert>
参数
上面已经介绍了参数传递,另外可以指定参数的类型去让对应的typeHandler处理它们。
#{age , javaType=int , jdbcType=NUMERIC }还可以对一些数值型的参数设置其保存的精度
#{price, javaType=double , jdbcType=NUMERIC , numericScale=2 }一般都是传递字符串,设置的参数#{name}大部分情况下,会创建预编译语句,但有时候传递的是SQL语句本身,不是需要的参数,可以通过$符号表示,比如传递参数columns为"col1,col2,col3",可以写成下面语句:
select ${columns} from t_tablename
但要注意sql的安全性,防止sql注入。
sql元素
定义:
<sql id="role_columns"> id,role_name,note </sql>
使用:
<include refid="role_columns"> <property name="prefix" value="r" /> </include>
结果映射
元素介绍
resultMap是MyBatis里面最复杂的元素,它的作用是定义映射规则、级联的更新、定制类型转换器等。
由以下元素构成:
<resultMap>
<constructor> <!-- 配置构造方法 -->
<idArg/>
<arg/>
</constructor>
<id/> <!--指明哪一列是主键-->
<result/> <!--配置映射规则-->
<association/> <!--一对一-->
<collection/> <!--一对多-->
<discriminator> <!--鉴别器级联-->
<case/>
</discriminator>
</resultMap>有的实体不存在没有参数的构造方法,需要使用constructor配置有参数的构造方法:
<resultMap id="role" type="com.xiaomi.kfs.mcc.core.domain.Role"> <constructor> <idArg column="id" javaType="int"/> <arg column="role_name" javaType="string"/> </constructor> </resultMap>
id指明主键列,result配置数据库字段和POJO属性的映射规则:
<resultMap id="role" type="com.xiaomi.kfs.mcc.core.domain.Role"> <id property="id" column="id" /> <result property="roleName" column="role_name" /> <result property="note" column="note" /> </resultMap>
association、collection用于配置级联关系的,分别为一对一和一对多,实际中,多对多关系的应用不多,因为比较复杂,会用一对多的关系把它分解为双向关系。
discriminator用于这样一种场景:比如我们去体检,男和女的体检项目不同,如果让男生去检查妇科项目,是不合理的, 通过discriminator可以根据性别,返回不同的对象。
延迟加载
级联的优势是能够方便地获取数据,但有时不需要获取所有数据,这样会多执行几条SQL,性能下降,为了解决这个问题,需要使用延迟加载,只要使用相关级联数据时,才会发送SQL去取回数据。
在MyBatis的配置中有2个全局的参数 lazyLoadingEnabled 和 aggressiveLazyLoading,第一个的含义是是否开启延迟加载功能,第二个的含义是对任意延迟加载属性的调用,会使延迟加载的对象完整加载,否则只会按需加载。
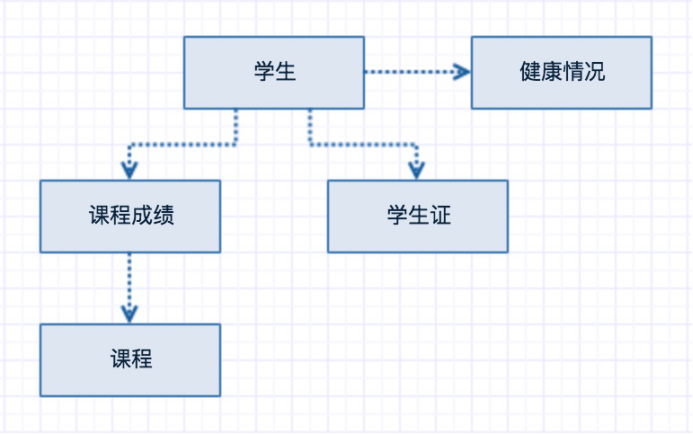
再
理解下aggressiveLazyLoading属性,比如学生对象的关联对象如下:
当访问学生信息的时候,会根据鉴别器把健康的情况也会查找出来;当访问课程成绩的时候,同时也会把学生证信息查找出来,因为在默认情况下,MyBatis是按层级延迟加载的。 但这不是我们需要的,并不希望在访问成绩的时候,去加载学生证的信息,可以设置aggressiveLazyLoading为false,按需进行延迟加载数据。
上面的2个属性都是全局设置,也可以在association和collection元素上加上属性值fetchType,它有两个取值eager和lazy。
缓存
在没有显示配置缓存时,只开启一级缓存,一级缓存是相对于同一个SqlSession而言的,在参数和SQL完全一样的情况下,使用同一个SqlSession对象调用同一个Mapper的方法,只会执行一次SQL。
如果是不同的SqlSession对象,因为不同SqlSession是相互隔离的,即使用相同的Mapper、参数和方法,还是会再次发送SQL到数据库去执行。
二级缓存是SqlSessionFactory层面上的,需要进行显示配置,实现二级缓存的时候,要求POJO必须是可序列化的,只需要简单配置即可:
<cache />
这样很多设置是默认的,有如下属性可以配置:
leviction:代表缓存回收策略,可选值有LRU最少使用、FIFO先进先出、SOFT软引用,WEAK弱引用;
lflushInterval:刷新间隔时间,单位为毫秒,如果不配置,当SQL被执行时才会刷新缓存;
lsize:引用数目,代表缓存最多可以存储多少对象,不宜设置过大,设置过大会导致内存溢出;
lreadOnly:只读,意味着缓存数据只能读取不能修改;
在大型服务器上,可能会使用专用的缓存服务器,比如Redis缓存,可以通过实现org.apache.ibatis.cache.Cache接口很方便的实现:
public interfaceCache { String getId(); //缓存编号 void putObject(Object var1, Object var2); //保存对象 Object getObject(Object var1); //获取对象 Object removeObject(Object var1); //移除对象 void clear(); //清空缓存 int getSize(); //获取缓存对象大小 ReadWriteLock getReadWriteLock(); //获取缓存的读写锁 }
动态SQL
很多时候,需要根据不同的场景组装查询条件,MyBatis提供对SQL语句动态的组装能力。
主要提供以下几种元素:
- lif:判断语句,但条件分支判断;
- lchoose (when、otherwise):多条件分支判断;
- ltrim (where、set):处理一些SQL拼装问题;
- lforeach:循环语句,在in语句等列举条件常用;
- lbind:通过OGNL表达式去自定义一个上下文变量,可以方便使用;
trim可以处理 and 和 逗号 拼接的问题,举例如下:
<select id="findRoles" parameterType="string" > select id,role_name,note fromt_role <trim prefix="where" prefixOverrides="and"> <if test="roleName!=null and roleName!=''"> and role_name like concat('%',#{roleName},'%') </if> </trim> </select>
另外,可以使用set元素设置更新的字段列表:
<update id="updateRole" parameterType="role"> update t_role <set> <if test="roleName!=null and roleName!=''"> role_name=#{roleName}, </if> <if test="note!=null and note!=''"> note=#{note} </if> </set> where id=#{id} </update>
反射
官网对反射的定义:
可以通过java代码,获取当前加载类的字段、方法、构造函数等信息,并在安全限制内,使用反射字段、方法、构造函数进行操作。
简单来说,可以在运行时获得程序中每一个类型的成员信息。程序中定义的对象,其类型都是在编译期确定的,而反射可以动态地创建对象,并访问或调用其成员。
动态代理
所谓代理,是一个人或组织代替另一个人或组织做事,主要有3个角色:访问者、代理人、被代理人,访问者经由代理人,与被代理人交互,中间会加入一些自己的处理。

所谓的动态代理,是说在编译时不需要定义代理类,而是在运行时创建,这个是关键:在运行时创建代理类。
Class对象
Class类是一个实实在在的类,存在于java.lang包中,用来表示运行时类型信息。Class对象表示自定义类的类型信息,比如创建一个User类,JVM就会创建一个User对应的Class对象,保存User类相关的类型信息,该对象保存在jvm堆中,作为访问方法区中User类型信息的接口。
在使用自定义类时,会首先检查这个类的Class对象是否已经加载,如果没有加载,默认的类加载器就会先根据类名查找.class文件,Class对象就会被加载到内存。
可以通过下面3种方法获取Class对象:
- l使用Class类的forName静态方法;
- l直接获取某一个对象的class;
- l调用某个对象的getClass()方法;
Class对象是反射的基础,提供了获取类信息的方法,后面会介绍。
反射提供的功能
java反射框架主要提供以下内容:
- l在运行时判断对象所属的类;
- l在运行时创建对象;
- l在运行时获取类包含的成员变量、方法、父类、接口等信息;
- l在运行时调用一个对象的方法;
下面举例说明相关功能
创建实例:
//获取String所对应的Class对象 Class<?> c = User.class; //获取String类带一个String参数的构造器 Constructor constructor = c.getConstructor(String.class); //根据构造器创建实例 User user = (User)constructor.newInstance("calm");
获取方法:
//返回类或接口声明的所有方法,包括私有的,但不包括继承的方法 publicMethod[] getDeclaredMethods() throws SecurityException //所有public方法,包括继承的方法 publicMethod[] getMethods() throws SecurityException //返回一个特定的方法,第一个参数为方法名称,后面的参数为方法参数对应Class的对象 public Method getMethod(String name, Class<?>... parameterTypes)
调用方法:
Class<?> userClass=User.class; Object obj =userClass.newInstance(); Method method =klass.getMethod("addRole",String.class); method.invoke(obj,"超级管理员");
JDK动态代理
JDK本身提供了动态代理的实现,要求被代理者必须实现接口。
public staticObject newProxyInstance(ClassLoader loader, Class<?>[] interfaces,InvocationHandler h)
第一个参数为类加载器,第二个参数是被代理者实现的接口列表,第三个参数是实现了InvocationHandler接口的对象。
InvocationHandler是一个接口,用于规范执行被代理者的方法,可在执行方法前后,添加公共的处理代码。生成的动态代理类包含一个InvocationHandler属性,调用对应方法时,会触发invoke方法的调用。
public classJDKProxy implements InvocationHandler { private Object targetObject;//被代理对象 publicObject newProxy(Object targetObject) { this.targetObject =targetObject; returnProxy.newProxyInstance(targetObject.getClass().getClassLoader(), targetObject.getClass().getInterfaces(), this); } public Object invoke(Object proxy, Method method, Object[] args)//invoke方法 throws Throwable { Object ret = null; ret =method.invoke(targetObject, args); returnret; } }
测试代码:
JDKProxy jdkProxy=newJDKProxy(); UserService userService =(UserService) jdkProxy.newProxy(newUserServiceImp()); userService.addRole("超级管理员");
JDK动态代理的基本原理是根据定义好的规则,用传入的接口创建一个新类。
CGLIB动态代理
JDK动态代理要求必须有接口,CGLIB(Code Generate Library)动态代理没有这个要求,它是通过创建一个被代理类的子类,然后使用ASM字节码库修改代码来实现的。
public classCGLibProxy implements MethodInterceptor { private Object targetObject; //被代理对象 publicObject createProxyObject(Object obj) { this.targetObject =obj; Enhancer enhancer = newEnhancer(); enhancer.setSuperclass(obj.getClass()); enhancer.setCallback(this); Object proxyObj =enhancer.create(); returnproxyObj; } publicObject intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable { Object obj = null; obj =method.invoke(targetObject, args); returnobj; } }
测试代码:
CGLibProxy cgLibProxy=newCGLibProxy(); UserService userService =(UserService) cgLibProxy.newProxy(newUserServiceImp()); userService.addRole("超级管理员");
构建SqlSessionFactory过程
构建主要分为2步:
l通过XMLConfigBuilder解析配置的XML文件,读出配置参数,包括基础配置XML文件和映射器XML文件;
l使用Configuration对象创建SqlSessionFactory,SqlSessionFactory是一个接口,提供了一个默认的实现类DefaultSqlSessionFactory。
说白了,就是将我们的所有配置解析为Configuration对象,在整个生命周期内,可以通过该对象获取需要的配置。
由于插件需要频繁访问映射器的内部组成,会重点这部分,了解这块配置抽象出来的对象:
MappedStatement
它保存映射器的一个节点(select|insert|delete|update),包括配置的SQL,SQL的id、缓存信息、resultMap、parameterType、resultType等重要配置内容。
它涉及的对象比较多,一般不去修改它。
SqlSource
它是MappedStatement的一个属性,主要作用是根据参数和其他规则组装SQL,也是很复杂的,一般也不用修改它。
BoundSql
对于参数和SQL,主要反映在BoundSql类对象上,在插件中,通过它获取到当前运行的SQL和参数以及参数规则,作出适当的修改,满足特殊的要求。
BoundSql提供3个主要的属性:parameterObject、parameterMappings和sql,下面分别来介绍。
parameterObject为参数本身,可以传递简单对象、POJO、Map或@Param注解的参数:
- l传递简单对象(int、float、String等),会把参数转换为对应的类,比如int会转换为Integer;
- l如果传递的是POJO或Map,paramterObject就是传入的POJO或Map不变;
- l如果传递多个参数,没有@Param注解,parameterObject就是一个Map<String,Object>对象,类似这样的形式{"1":p1 , "2":p2 , "3":p3 ... "param1":p1 , "param2":p2 , "param3",p3 ...},所以在编写的时候可以使用#{param1}或#{1}去引用第一个参数;
- l如果传递多个参数,有@Param注解,与没有注解的类似,只是将序号的key替换为@Param指定的name;
parameterMappings,它是一个List,元素是ParameterMapping对象,这个对象会描绘sql中的参数引用,包括名称、表达式、javaType、jdbcType、typeHandler等信息。
sql,是写在映射器里面的一条sql。
有了Configuration对象,构建SqlSessionFactory就简单了:
sqlSessionFactory = new SqlSessionFactoryBuilder().bulid(inputStream);SqlSession运行过程
映射器的动态代理
Mapper映射是通过动态代理来实现的,使用JDK动态代理返回一个代理对象,供调用者访问。
首先看看实现InvocationHandler接口的类,它是执行本代理方法的关键,可以看到,Mapper是一个接口,会生成MapperMethod对象,调用execute方法。
public class MapperProxy<T>implements InvocationHandler, Serializable { ..... @Override publicObject invoke(Object proxy, Method method, Object[] args) throws Throwable { try{ if (Object.class.equals(method.getDeclaringClass())) { return method.invoke(this, args); } else if(isDefaultMethod(method)) { returninvokeDefaultMethod(proxy, method, args); } } catch(Throwable t) { throwExceptionUtil.unwrapThrowable(t); } final MapperMethod mapperMethod =cachedMapperMethod(method); returnmapperMethod.execute(sqlSession, args); } }
看下面的代码,MapperMethod采用命令模式,根据不同的sql操作,做不同的处理。
public classMapperMethod { publicObject execute(SqlSession sqlSession, Object[] args) { Object result; switch(command.getType()) { caseINSERT: { Object param =method.convertArgsToSqlCommandParam(args); result =rowCountResult(sqlSession.insert(command.getName(), param)); break; } caseUPDATE: { Object param =method.convertArgsToSqlCommandParam(args); result =rowCountResult(sqlSession.update(command.getName(), param)); break; ...... } } }
最后看下,生成代理类的方法,就是使用JDK动态代理Proxy来创建的。
public class MapperProxyFactory<T>{ publicT newInstance(SqlSession sqlSession) { final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache); returnnewInstance(mapperProxy); } @SuppressWarnings("unchecked") protected T newInstance(MapperProxy<T>mapperProxy) { return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), newClass[] { mapperInterface }, mapperProxy); } }
总结下映射器的调用过程,返回的Mapper对象是代理对象,当调用它的某个方法时,其实是调用MapperProxy#invoke方法,而映射器的XML文件的命名空间对应的就是这个接口的全路径,会根据全路径和方法名,便能够绑定起来,定位到sql,最后会使用SqlSession接口的方法使它能够执行查询。
SqlSession下的四大对象
通过上面的分析,映射器就是一个动态代理对象,进入到了MapperMethod的execute方法,它经过简单的判断就进入了SqlSession的删除、更新、插入、选择等方法,这些方法如何执行是下面要介绍的内容。
Mapper执行的过程是通过Executor、StatementHandler、ParameterHandler和ResultHandler来完成数据库操作和结果返回的,理解他们是编写插件的关键:
- lExecutor:执行器,由它统一调度其他三个对象来执行对应的SQL;
- lStatementHandler:使用数据库的Statement执行操作;
- lParameterHandler:用于SQL对参数的处理;
- lResultHandler:进行最后数据集的封装返回处理;
在MyBatis中存在三种执行器:
- lSIMPLE:简易执行器,默认的执行器;
- lREUSE:执行重用预处理语句;
- lBATCH:执行重用语句和批量更新,针对批量专用的执行器;
以SimpleExecutor为例,说明执行过程
public classSimpleExecutor extends BaseExecutor { /** * 执行查询操作 */ public <E> List<E>doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try{ Configuration configuration =ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, rowBounds, resultHandler, boundSql); stmt =prepareStatement(handler, ms.getStatementLog()); return handler.<E>query(stmt, resultHandler); } finally{ closeStatement(stmt); } } /** * 初始化StatementHandler */ privateStatement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection =getConnection(statementLog); stmt =handler.prepare(connection); handler.parameterize(stmt); returnstmt; } /** * 执行查询 */ @Override public <E> List<E>query(Statement statement, ResultHandler resultHandler) throws SQLException { String sql =boundSql.getSql(); statement.execute(sql); return resultSetHandler.<E>handleResultSets(statement); } }
可以看到最后会委托给StatementHandler会话器进行处理,它是一个接口,实际创建的是RoutingStatementHandler对象,但它不是真实的服务对象,它是通过适配器模式找到对应的StatementHandler执行的。在MyBatis中,StatementHandler和Executor一样分为三种:SimpleStatementHandler、PreparedStatementHandler、CallableStatementHandler。
Executor会先调用StatementHandler的prepare方法预编译SQL语句,同时设置一些基本运行的参数。然后调用parameterize()方法启用ParameterHandler设置参数,完成预编译,跟着执行查询,用ResultHandler封装结果返回给调用者。