摘要:
df表示。set_索引。xs#xs方法适用于多索引DataFrame#的数据过滤。index=df['A']#将列A用作DataFrame df的行索引。loc['fo',:]#使用布尔df。loc[df['A']=='o']使用APIpd。数据帧。查询方法。当数据量较大时,效率比传统方法更有效。数据。query#多条件df查询数据提取不仅仅是上面提到的情况,第一个答案给出了以下常见情况:1.筛选出列值等于标量的行,并使用==df。loc[df['column_name']==some_Value]2.筛选出列值属于某个范围的行,然后使用isindf。loc[df['column_name']isin]#some_值是可迭代的对象。3.对多个条件使用&时,&的优先级高于˃=或˂=,因此请注意使用括号。df表示。loc[&]4.筛选出列值不等于某些值的行。df['列名称']!
在pandas中怎么样实现类似mysql查找语句的功能:
select * from table where column_name = some_value;
pandas中获取数据的有以下几种方法:
- 布尔索引
- 位置索引
- 标签索引
- 使用API
假设数据如下:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})

布尔索引
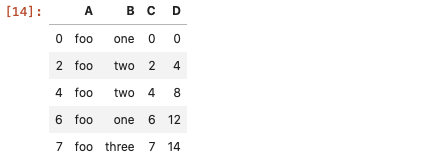
该方法其实就是找出每一行中符合条件的真值(true value),如找出列A中所有值等于foo
df[df['A'] == 'foo'] # 判断等式是否成立
位置索引
使用iloc方法,根据索引的位置来查找数据的。这个例子需要先找出符合条件的行所在位置
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask) # 返回的是array([0, 2, 4, 6, 7])
df.iloc[pos]
#常见的iloc用法
df.iloc[:3,1:3]

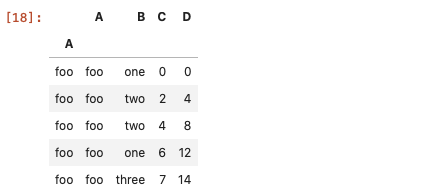
标签索引
如何DataFrame的行列都是有标签的,那么使用loc方法就非常合适了。
df.set_index('A', append=True, drop=False).xs('foo', level=1) # xs方法适用于多重索引DataFrame的数据筛选
# 更直观点的做法
df.index=df['A'] # 将A列作为DataFrame的行索引
df.loc['foo', :]
# 使用布尔
df.loc[df['A']=='foo']
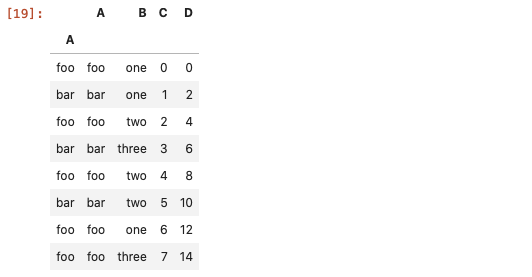
使用API
pd.DataFrame.query方法在数据量大的时候,效率比常规的方法更高效。
df.query('A=="foo"')
# 多条件
df.query('A=="foo" | A=="bar"')
数据提取不止前面提到的情况,第一个答案就给出了以下几种常见情况:
1、筛选出列值等于标量的行,用==
df.loc[df['column_name'] == some_value]
2、筛选出列值属于某个范围内的行,用isin
df.loc[df['column_name'].isin(some_values)] # some_values是可迭代对象
3、多种条件限制时使用&,&的优先级高于>=或<=,所以要注意括号的使用
df.loc[(df['column_name'] >= A) & (df['column_name'] <= B)]
4、筛选出列值不等于某个/些值的行
df.loc[df['column_name'] != 'some_value']
df.loc[~df['column_name'].isin('some_values')] #~取反
如果你觉得我的文章还可以,可以关注我的微信公众号,查看更多实战文章:Python爬虫实战之路
也可以扫描下面二维码,添加我的微信公众号
