摘要:
HTWCore是一个基于.NETCore的winform客户端程序,可用于处理来自各种来源的音频和视频,如会议、记录、讲座、讲座等,并使用语音识别、视频内容提取和其他技术将其整理成word文档。项目中使用了以下技术:基于.NETCore,它是一个跨平台程序,可以在Windows平台的各种版本中使用。未来它将适应Linux、Mac和其他平台。使用音频分割、音量处理、音频和视频解码、转码、音频和图像降噪、视频帧提取和其他音频和视频处理技术。语音识别期间记录的每个单词的时间代码可用于生成SRT文件和添加字幕文件。
HTWCore是一款基于.NET Core的winform客户端程序,可以用来处理各种会议,记录,讲座,讲课等等来源的音视频,运用语音识别、视频内容提取等技术整理成word文档。项目中运用了以下技术:
- 基于.NET Core,因此是一款跨平台程序,可用于windows平台各个版本,将来会适配linux、mac等平台。将程序打包成单个文件,免于安装,性能比较高。
- 使用了音频切分,音量处理,音视频解码、转码,音视频降噪,视频帧提取等音视频处理技术。
- 运用了当前领先的语音识别技术,可识别会议,记录,讲座等等场景的音频。
- 利用声纹识别技术区分录音中人物角色,整理出自然、易读的文档。
- 语音识别过程中记录每个单词的时间码,可用于生成SRT文件,添加字幕文件。
- 使用了文本分析、自然语言处理技术,处理词类型,自然的添加标点符号。
- 视频内嵌字幕提取首先将视频帧分离出包含成有效文本的图片,然后用基于SSIM(结构相似性,是一种衡量两幅图像相似度的指标)的算法比较两种图片的相似度,去掉相似度高的图片,提高性能。
- 将视频帧OCR,能处理各种自然场景的含有文本图片,可以是中文、英文、日语、韩语等,也可以是双语文本,双语提取结果分行显示。
- 对内容文字运用文本相似度算法,有效去重。
- 将处理结果导出为常用的文本处理软件word,自动换行,缩进等,文档内容易读。
HTWCore效果如下:
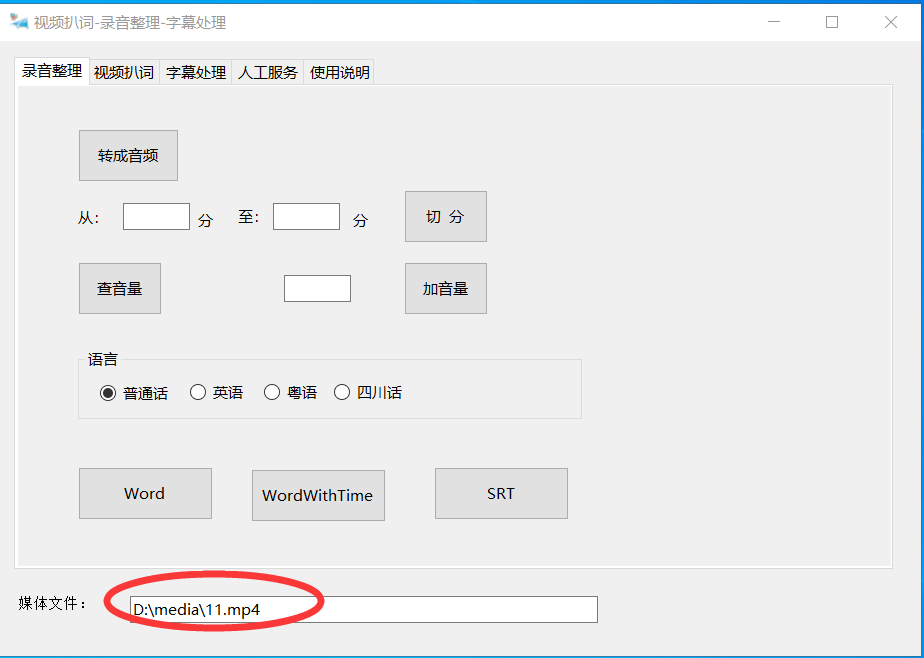
将音视频文件拖入文本框。
- 可直接识别,或者可以对音视频做处理。
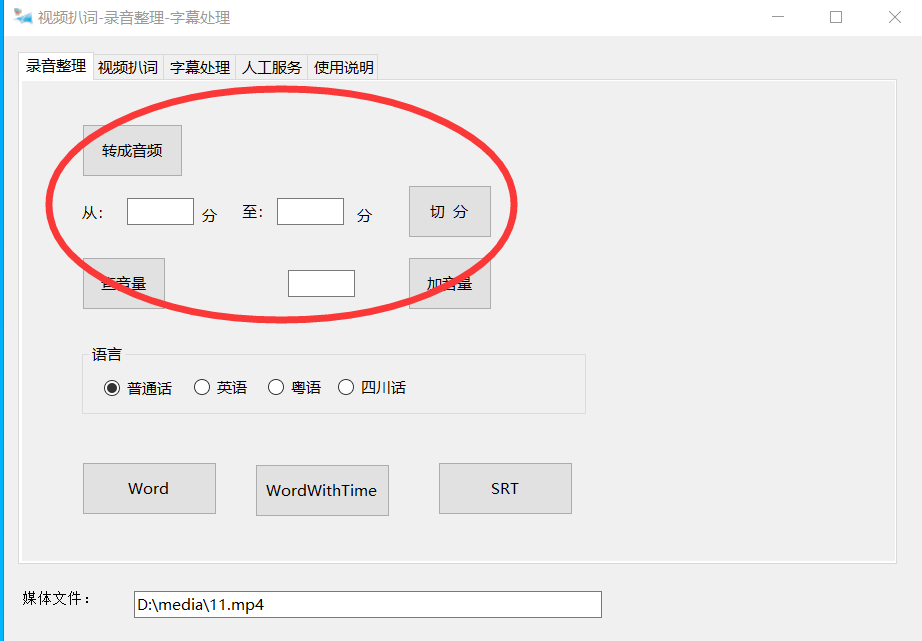
- 点击"Word"按钮,后进度提示。
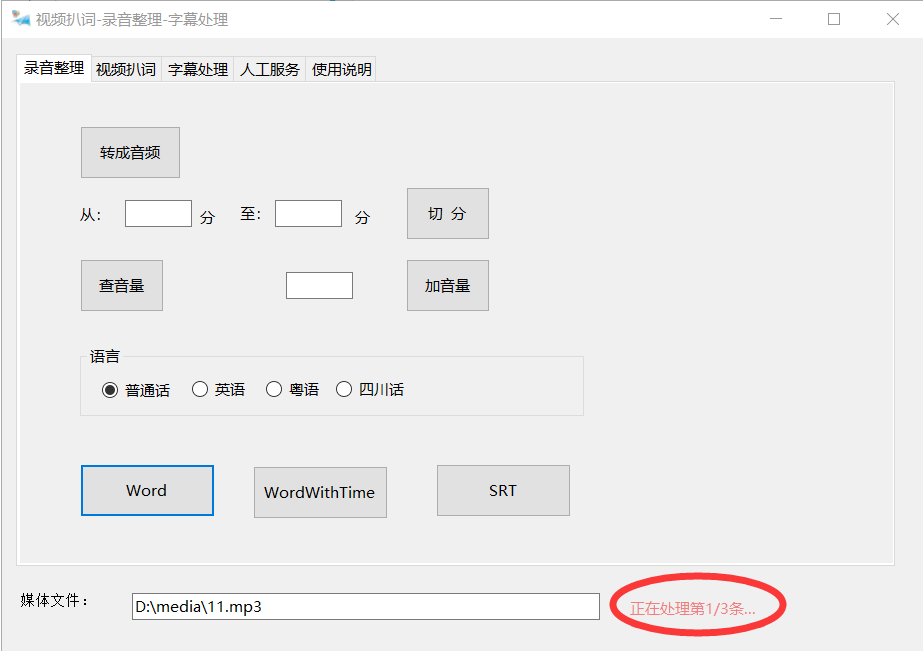
- 处理的结果生成的word文档在音视频的同目录下,1小时的音频只需要不到10分钟可出结果。

语音质量好的识别正确率在95%以上。
- 内嵌字幕,先截图框定范围。
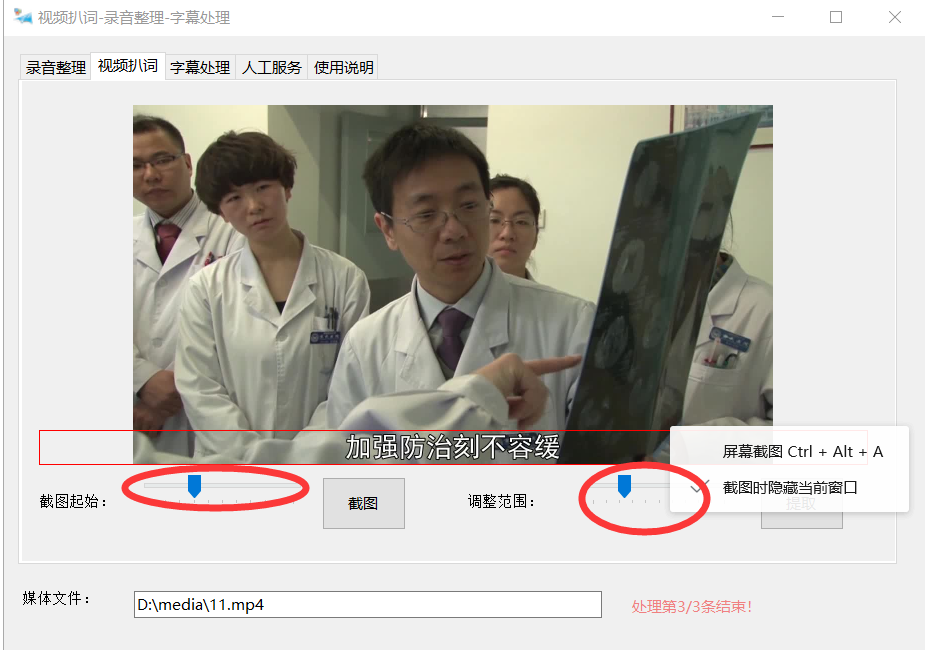
左面的椭圆调整出现文本的帧,右边的滑块调整字幕范围。
其余功能可直接使用,不一一说明了。
HTWCore下载:
链接:https://pan.baidu.com/s/1k4zjpMBbUf-Okczd6xUogQ 提取码:qs52
或者加QQ群:414750884
