摘要:
Studio3T是用于MongoDB数据操作的可视化工具。在Studio3T中,我们可以使用QueryBuilder的拖放来构建查询条件。关于QueryBuilder的具体用法,您可以阅读Studio3T的官方文章。
Studio 3T 是一款对 MongoDB 进行数据操作的可视化工具。
在 Studio 3T 中,我们可以借助 Query Builder 的 Drag & Drop 来构建查询条件。
具体的 Query Builder 使用方式可以阅读 Studio 3T 官方的这篇文章。
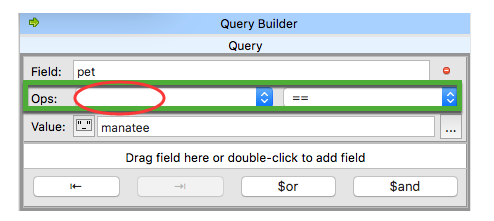
注意:在指定某个字段的值时,Ops 第一栏不要写: