摘要:
选择sqlservernativeclient10.0作为数据源,然后选择服务器和数据库,然后单击Next。进入“选择目标”窗口,“选择Microsoft Excel作为“目标”,然后选择保存路径和保存版本,然后单击“下一步”。进入“选择源表和源视图”窗口,在要导出的表源前面进行检查。单击“运行并完成”。检查数据是否已导出到Excel。
https://blog.csdn.net/weixin_42596182/article/details/90750187
打开数据库后选择需要导出数据的数据库,比如本次为db_PMMS,右键选择“任务”–“导出数据”,点击下一步。
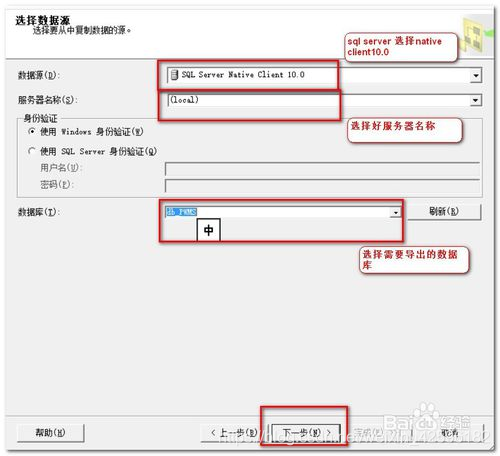
进入“选择数据源”窗口。“数据源”选择sql server native client 10.0,然后选择服务器和数据库,点击下一步。
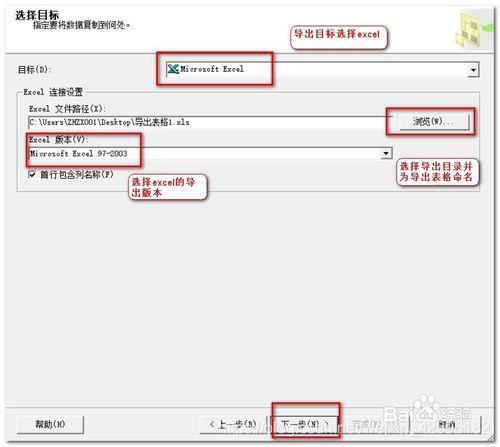
进入“选择目标”窗口,”“目标”选择 Microsoft Excel ,然后选择保存路径和保存版本,点击下一步。
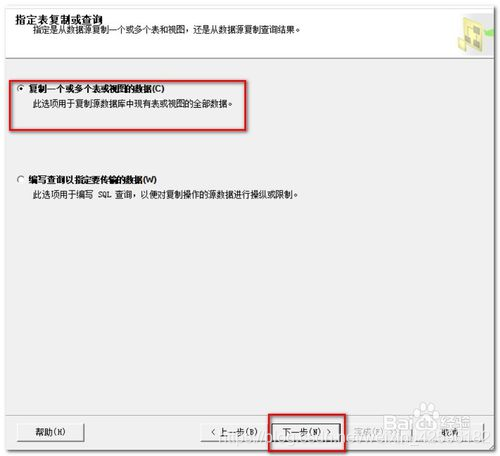
进入“指定表复制”窗口,在“复制一个或者多个表或视图的数据”前勾选,点击下一步。
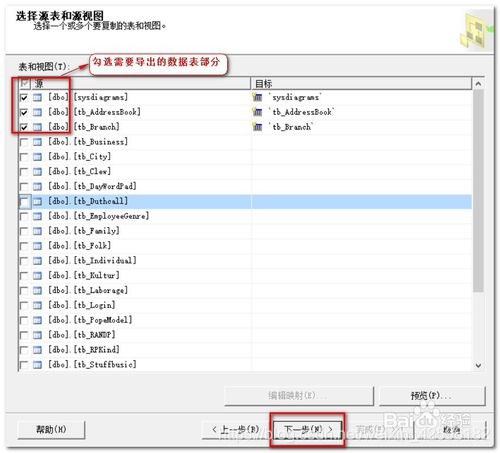
进入“选择源表和源视图”窗口,在需要导出的表源前方勾选。点击下一步。
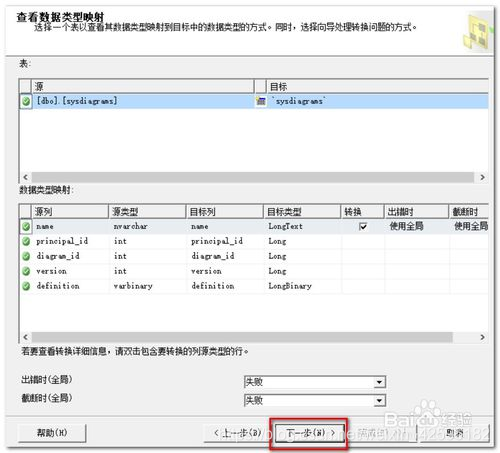
进入“查看数据类型映射”窗口,默认点击下一步。
点击运行和完成。查看数据已导出至excel表格。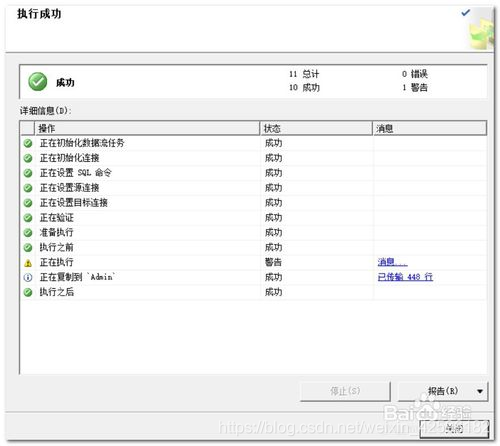
</div>