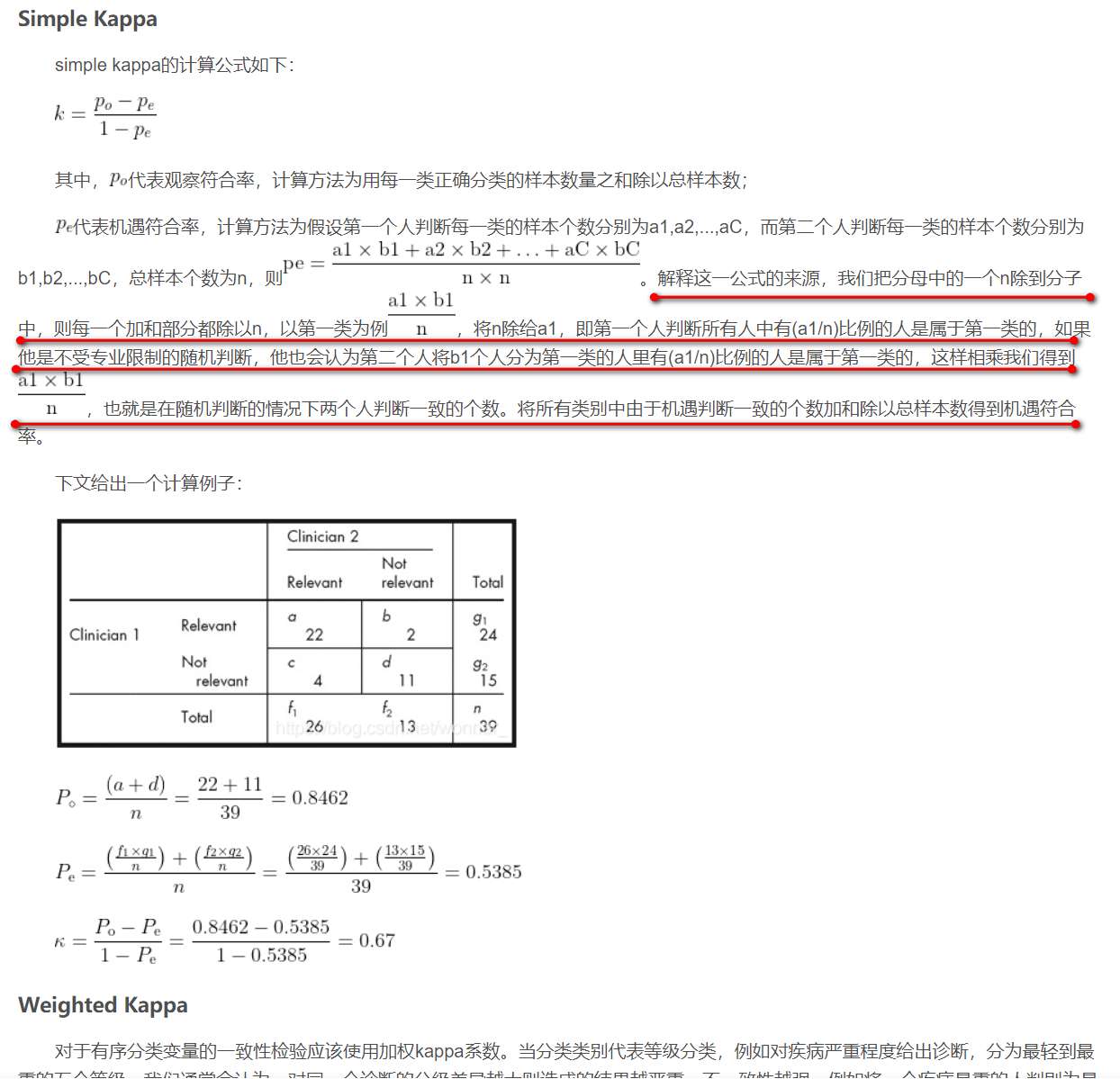
摘要:
kappa系数是用来衡量两个变量一致性的指标,如果将两个变量换为分类结果和验证样本,就可以用来评价分类精度了。计算公式如下:kappa=/其中,Po是总体精度,Pe是偶然一致性误差即使是两个完全独立的变量,一致性也不会为0,仍存在偶然现象,使两个变量存在一致的情况,所以仍要提取偶然一致性。计算过程如下图:
kappa系数是用来衡量两个变量一致性的指标,如果将两个变量换为分类结果和验证样本,就可以用来评价分类精度了。计算公式如下:
kappa=(Po-Pe)/(1-Pe)
其中,Po是总体精度,Pe是偶然一致性误差
即使是两个完全独立的变量,一致性也不会为0,仍存在偶然现象,使两个变量存在一致的情况,所以仍要提取偶然一致性。计算过程如下图: