导航:这里主要是列出一个prometheus一些系统的学习过程,最后按照章节顺序查看,由于写作该文档经历了不同时期,所以在文中有时出现 的云环境不统一,但是学习具体使用方法即可,在最后的篇章,有一个完整的腾讯云的实战案例。 8.kube-state-metrics 和 metrics-server 13.Grafana简单用法 参考: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config https://www.bookstack.cn/read/prometheus_practice/introduction-README.md |
由于自己写一些prometheus sql告警规则会比较耗时,所以这里从腾讯云的云原生监控和prometheus operator中扒一些过来进行记录。
(prometheus operator和云原生中的基本差不多)
这里主要从腾讯云的云原生监控来获取,因为标签以及变量问题,该sql在联邦集群环境中需要调整才能使用。
1.Kubernetes节点
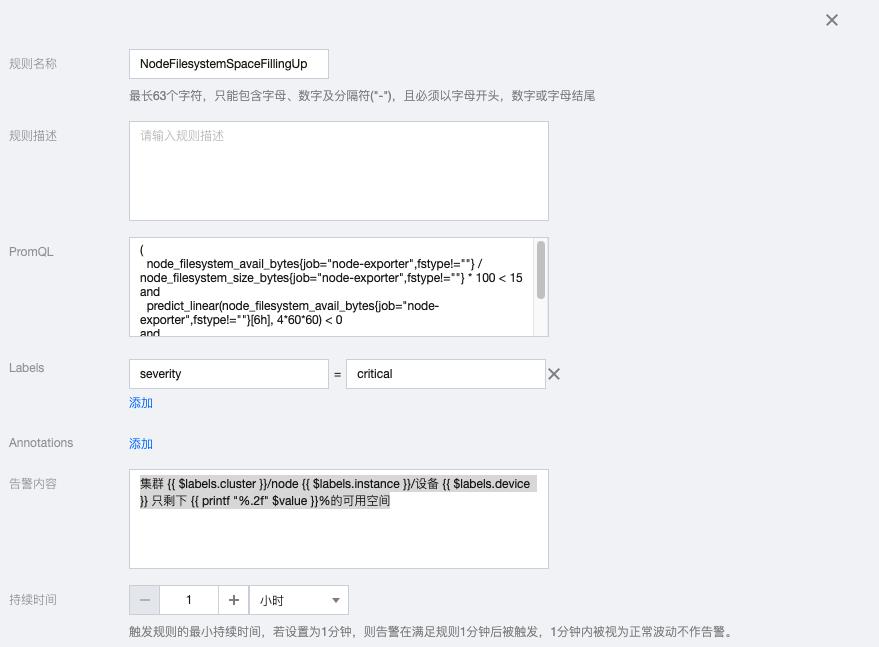
1.1 NodeFilesystemSpaceFillingUp
( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 15 and predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 )
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.instance }}/设备 {{ $labels.device }} 只剩下 {{ printf "%.2f" $value }}%的可用空间
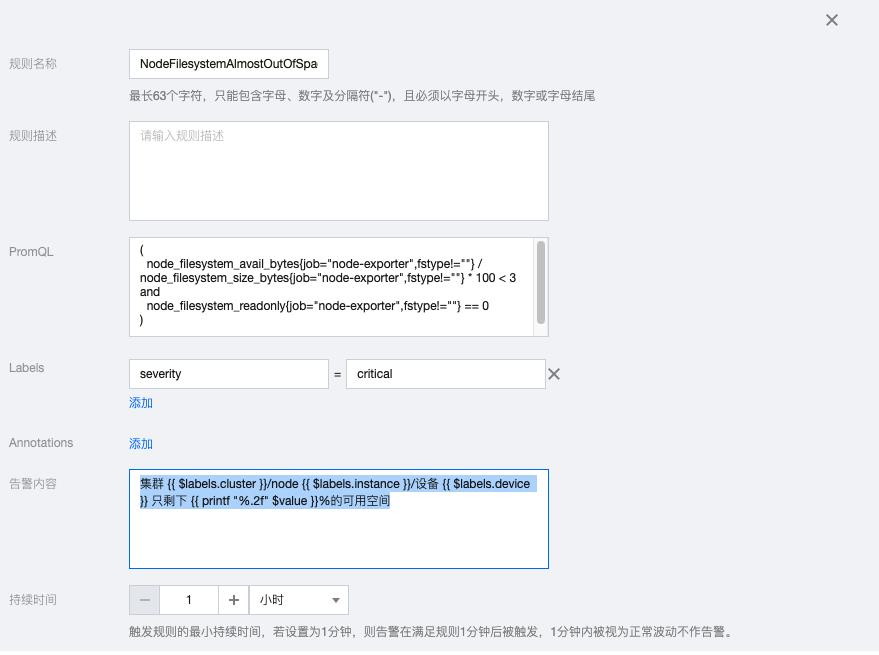
1.2 NodeFilesystemAlmostOutOfSpace
( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 3 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 )
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.instance }}/设备 {{ $labels.device }} 只剩下 {{ printf "%.2f" $value }}%的可用空间
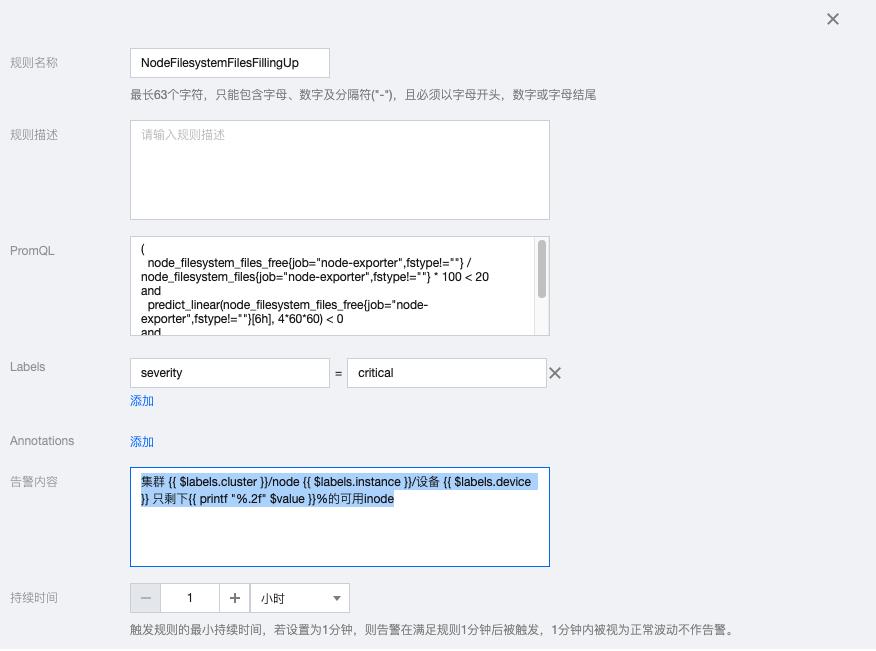
1.3 NodeFilesystemFilesFillingUp
( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 20 and predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 )
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.instance }}/设备 {{ $labels.device }} 只剩下{{ printf "%.2f" $value }}%的可用inode
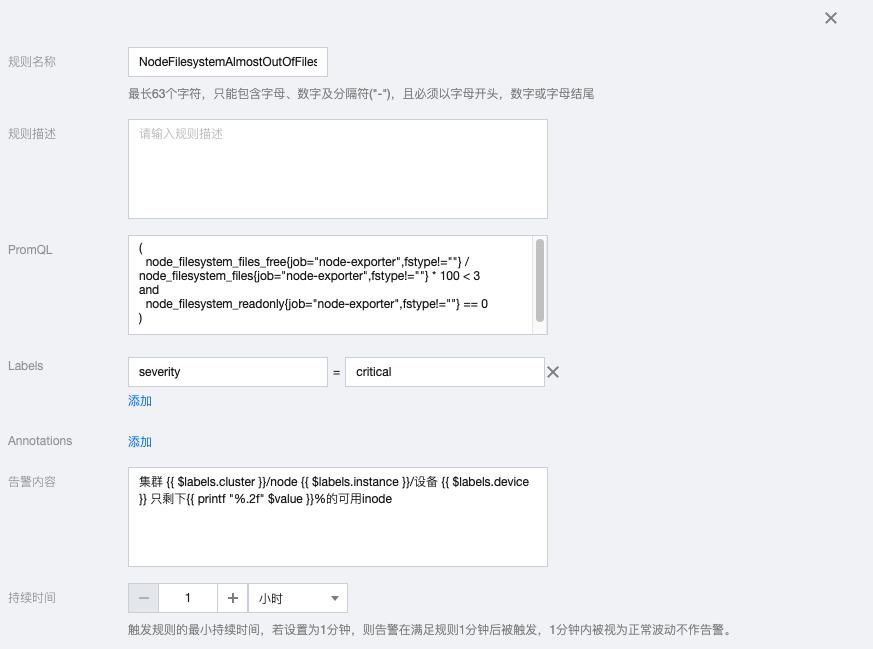
1.4 NodeFilesystemAlmostOutOfFiles
( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 3 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 )
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.instance }}/设备 {{ $labels.device }} 只剩下{{ printf "%.2f" $value }}%的可用inode
1.5 NodeNetworkReceiveErrs
rate(node_network_receive_errs_total[2m]) / rate(node_network_receive_packets_total[2m]) > 0.01
告警内容:在最近2分钟,集群 {{ $labels.cluster }}/node {{ $labels.instance }}/网卡 {{ $labels.device }} 出现{{ printf "%.0f" $value }}接收错误
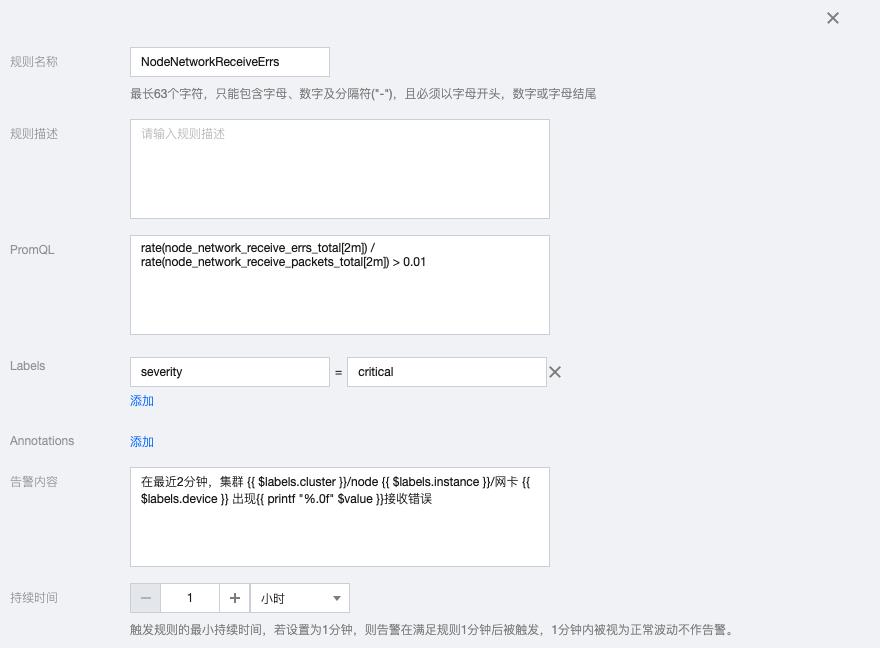
1.6 NodeNetworkTransmitErrs
rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01
告警内容:在最近2分钟,集群 {{ $labels.cluster }}/node {{ $labels.instance }}/网卡 {{ $labels.device }} 出现{{ printf "%.0f" $value }}发送错误
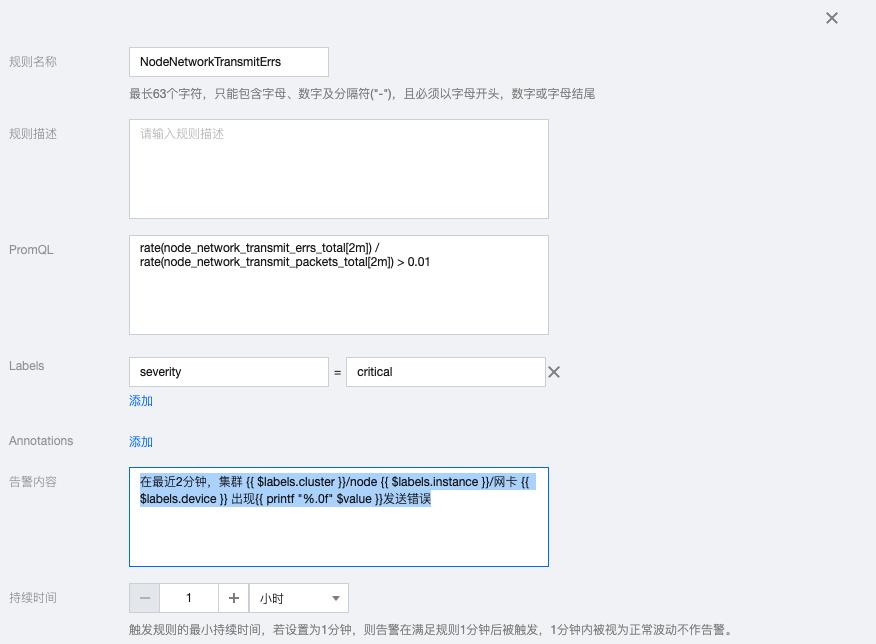
1.7 NodeHighNumberConntrackEntriesUsed
(node_nf_conntrack_entries / node_nf_conntrack_entries_limit) > 0.75
告警内容:{{ $value | humanizePercentage }} of conntrack entries are used.
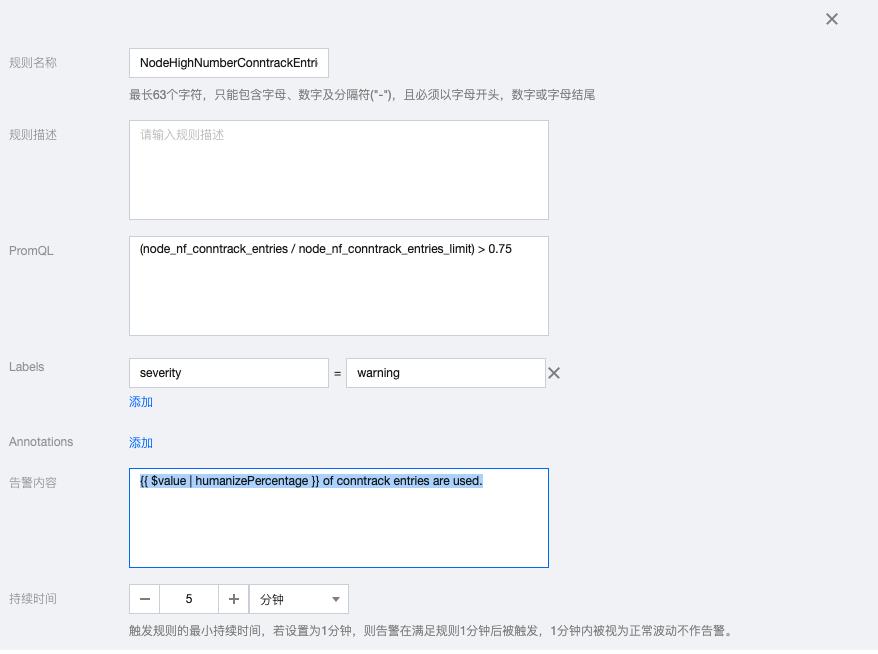
1.8 NodeClockSkewDetected
( node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0 ) or ( node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0 )
告警内容:集群 {{ $labels.cluster_id }}/node {{ $labels.instance }}的时钟漂移超过300秒, 请检查NTP是否正常配置
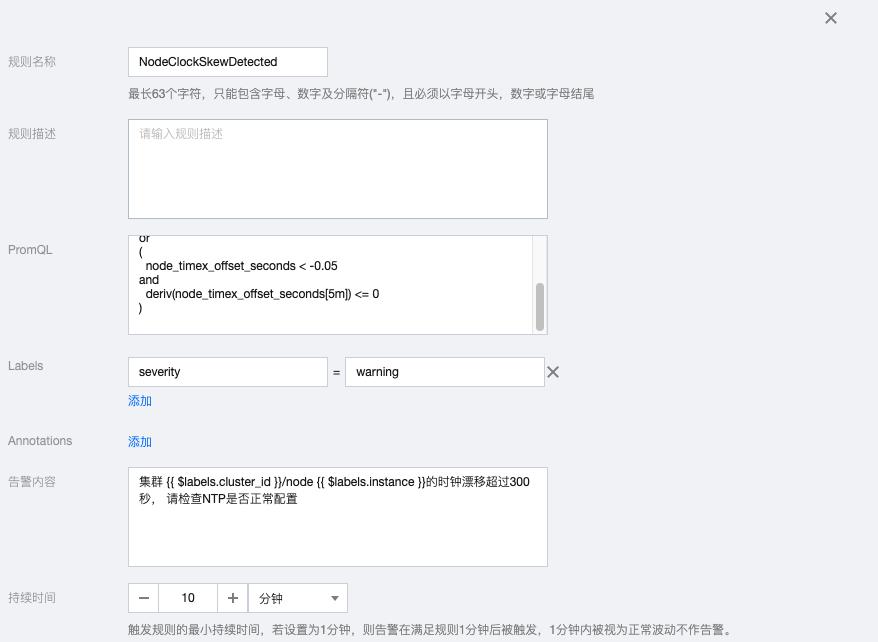
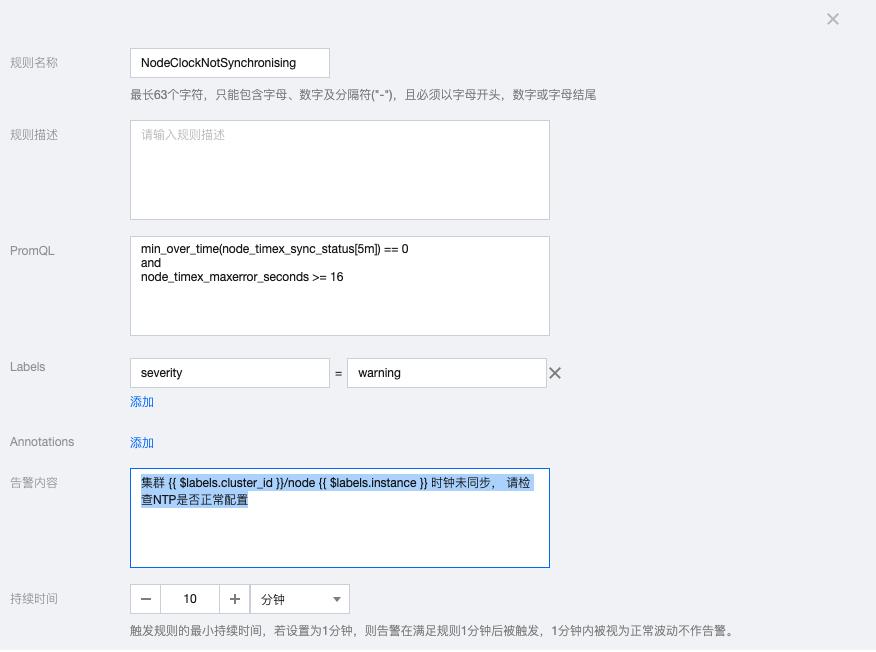
1.9 NodeClockNotSynchronising
min_over_time(node_timex_sync_status[5m]) == 0 and node_timex_maxerror_seconds >= 16
告警内容:集群 {{ $labels.cluster_id }}/node {{ $labels.instance }} 时钟未同步, 请检查NTP是否正常配置
2.kubernetes工作负载
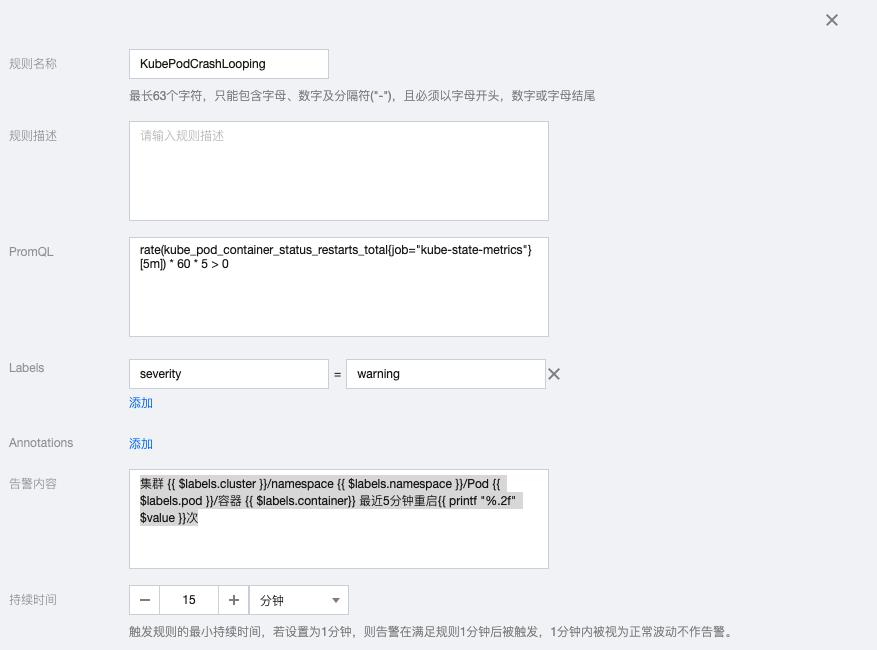
2.1 KubePodCrashLooping
rate(kube_pod_container_status_restarts_total{job="kube-state-metrics"}[5m]) * 60 * 5 > 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}/容器 {{ $labels.container}} 最近5分钟重启{{ printf "%.2f" $value }}次
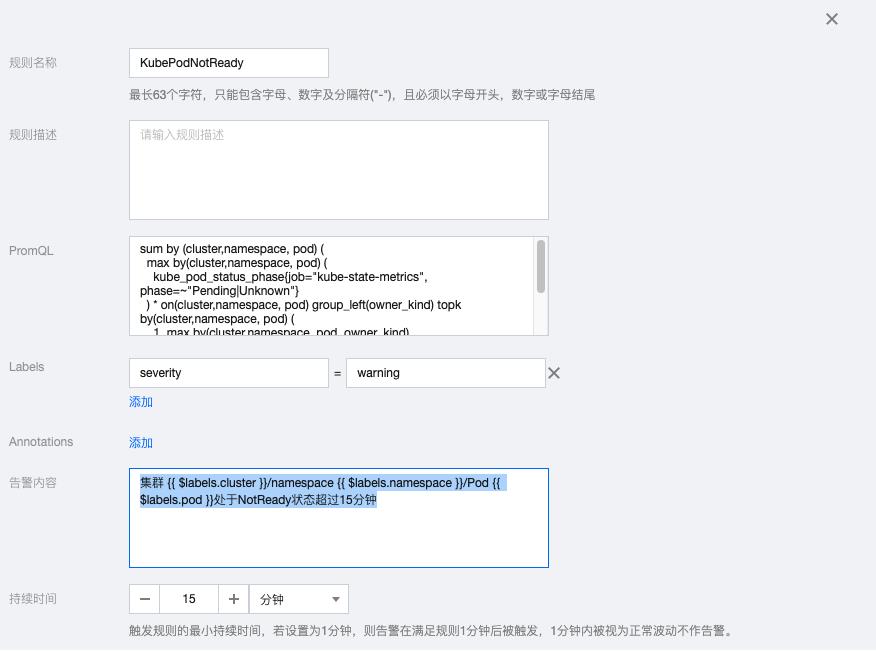
2.2 KubePodNotReady
sum by (cluster,namespace, pod) ( max by(cluster,namespace, pod) ( kube_pod_status_phase{job="kube-state-metrics", phase=~"Pending|Unknown"} ) * on(cluster,namespace, pod) group_left(owner_kind) topk by(cluster,namespace, pod) ( 1, max by(cluster,namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"}) ) ) > 0
告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}处于NotReady状态超过15分钟
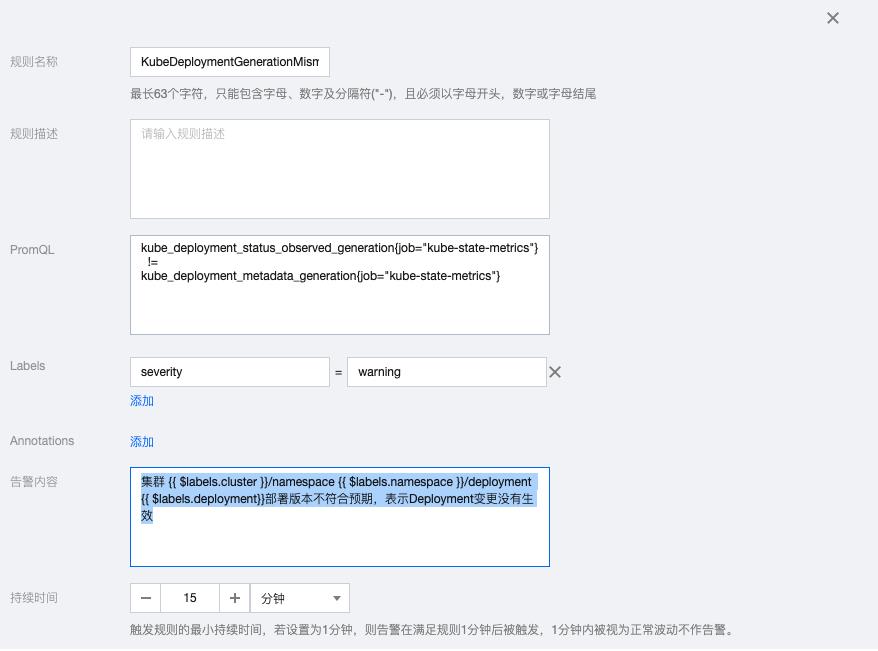
2.3 KubeDeploymentGenerationMismatch
kube_deployment_status_observed_generation{job="kube-state-metrics"}
!=
kube_deployment_metadata_generation{job="kube-state-metrics"}告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/deployment {{ $labels.deployment}}部署版本不符合预期,表示Deployment变更没有生效
2.4 KubeDeploymentReplicasMismatch
( kube_deployment_spec_replicas{job="kube-state-metrics"} != kube_deployment_status_replicas_available{job="kube-state-metrics"} ) and ( changes(kube_deployment_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 )
告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/deployment {{ $labels.deployment }} 没有达到预期副本数超过15分钟
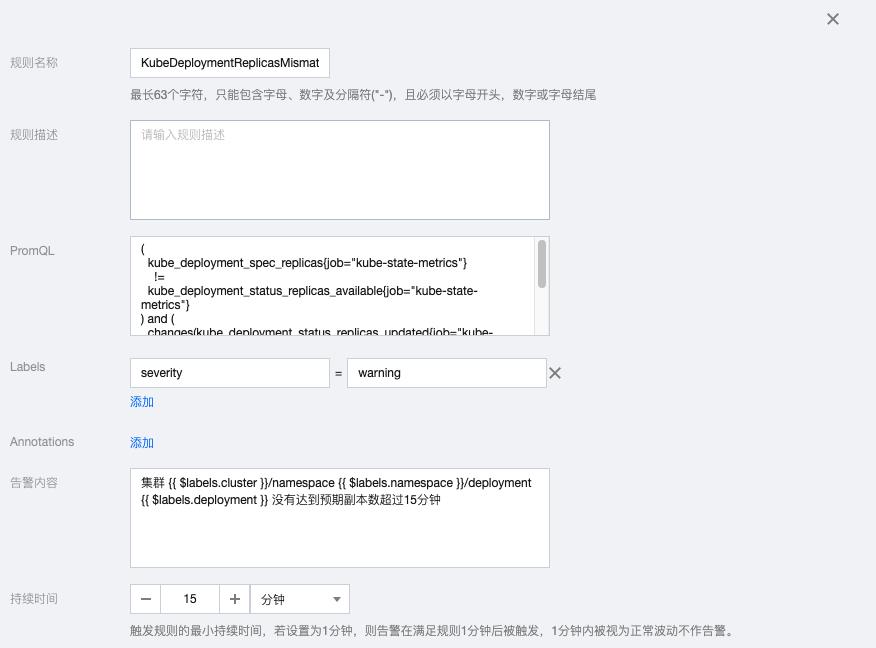
2.5 KubeStatefulSetReplicasMismatch
( kube_statefulset_status_replicas_ready{job="kube-state-metrics"} != kube_statefulset_status_replicas{job="kube-state-metrics"} ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 )
告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/statefulset {{ $labels.statefulset }} 没有达到预期副本数超过15分钟
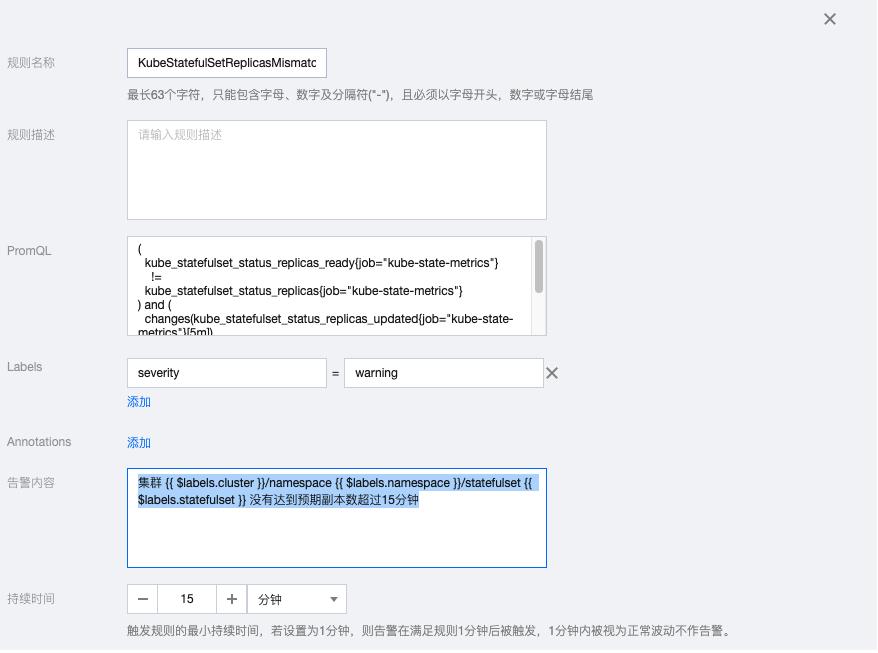
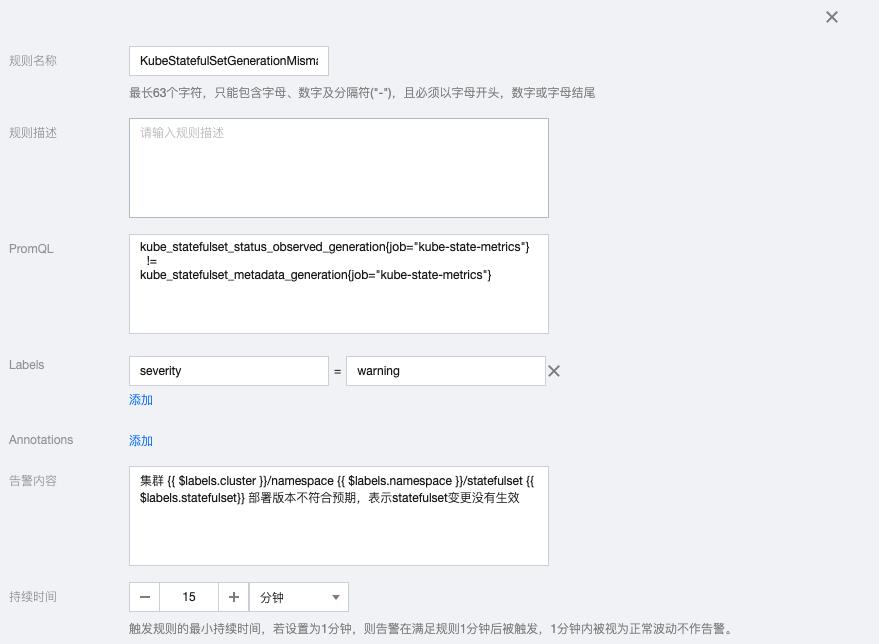
2.6 KubeStatefulSetGenerationMismatch
kube_statefulset_status_observed_generation{job="kube-state-metrics"}
!=
kube_statefulset_metadata_generation{job="kube-state-metrics"}告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/statefulset {{ $labels.statefulset}} 部署版本不符合预期,表示statefulset变更没有生效
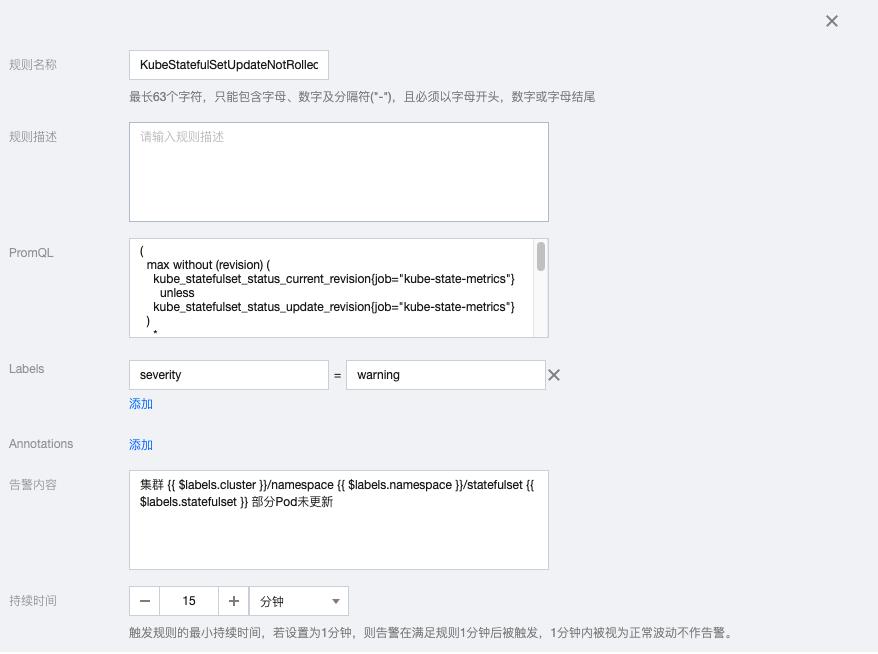
2.7 KubeStatefulSetUpdateNotRolledOut
( max without (revision) ( kube_statefulset_status_current_revision{job="kube-state-metrics"} unless kube_statefulset_status_update_revision{job="kube-state-metrics"} ) * ( kube_statefulset_replicas{job="kube-state-metrics"} != kube_statefulset_status_replicas_updated{job="kube-state-metrics"} ) ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 )
告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/statefulset {{ $labels.statefulset }} 部分Pod未更新
2.8 KubeDaemonSetRolloutStuck
( ( kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) or ( kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} != 0 ) or ( kube_daemonset_updated_number_scheduled{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) or ( kube_daemonset_status_number_available{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) ) and ( changes(kube_daemonset_updated_number_scheduled{job="kube-state-metrics"}[5m]) == 0 )
告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/daemonset {{ $labels.daemonset }} 变更卡了超过15分钟
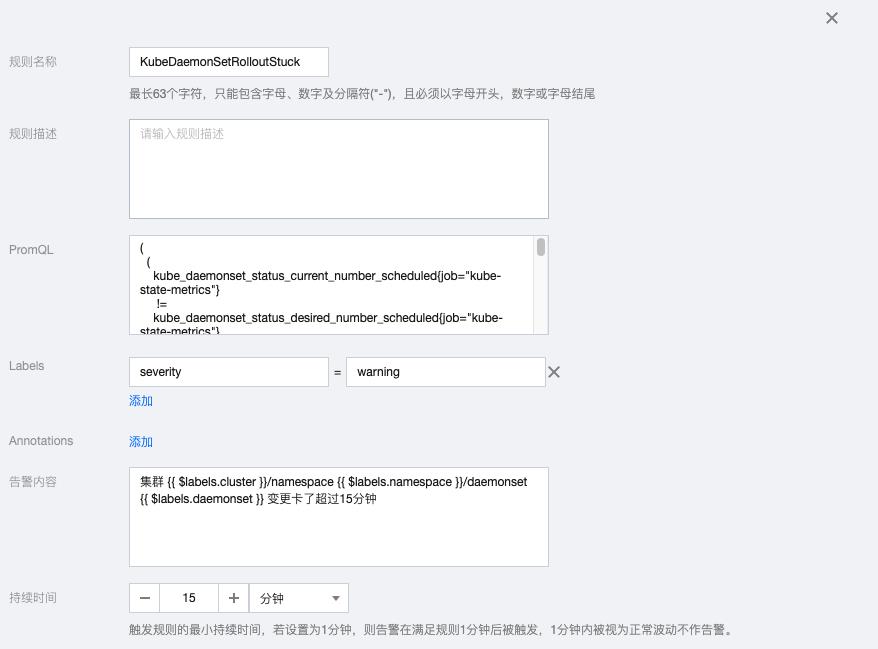
2.9 KubeContainerWaiting
sum by (namespace, pod, container,cluster) (kube_pod_container_status_waiting_reason{job="kube-state-metrics"}) > 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/pod {{ $labels.pod }}/container {{ $labels.container}} 处于Waiting状态超过1小时
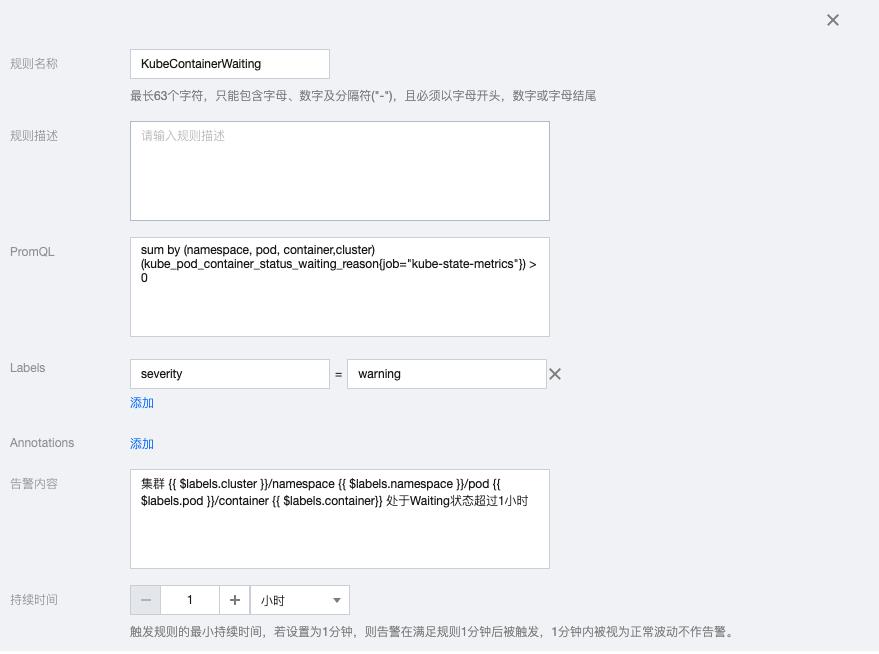
2.10 KubeDaemonSetNotScheduled
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"}
-
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} > 0告警内容:集群 {{ $labels.cluster }}/ namespace {{ $labels.namespace }}/daemonset {{ $labels.daemonset}} 中 {{ $value }} 个 pod 没有被调度
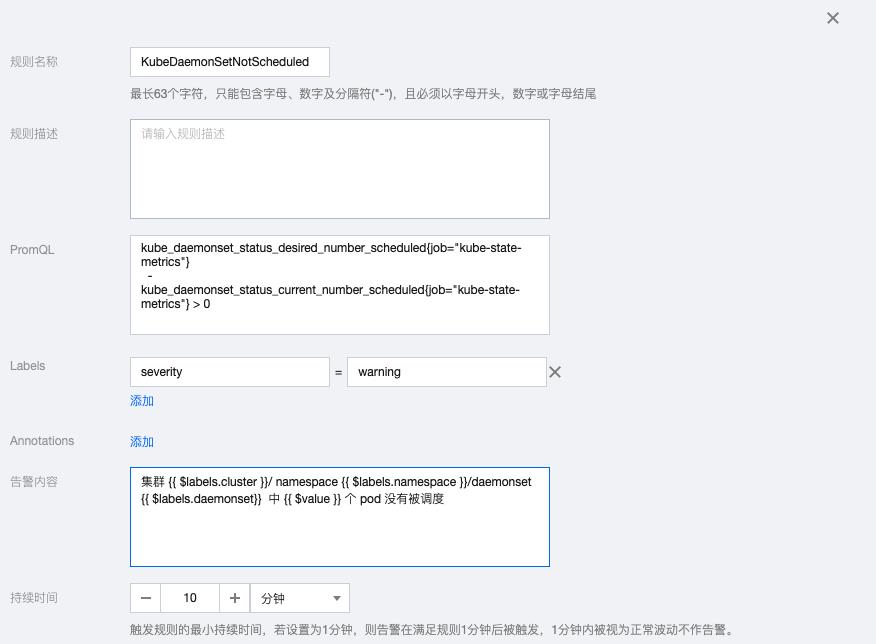
2.11 KubeDaemonSetMisScheduled
kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} > 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/daemonset {{ $labels.daemonset}} 中 {{ $value }} 个 pod 错误调度到node上
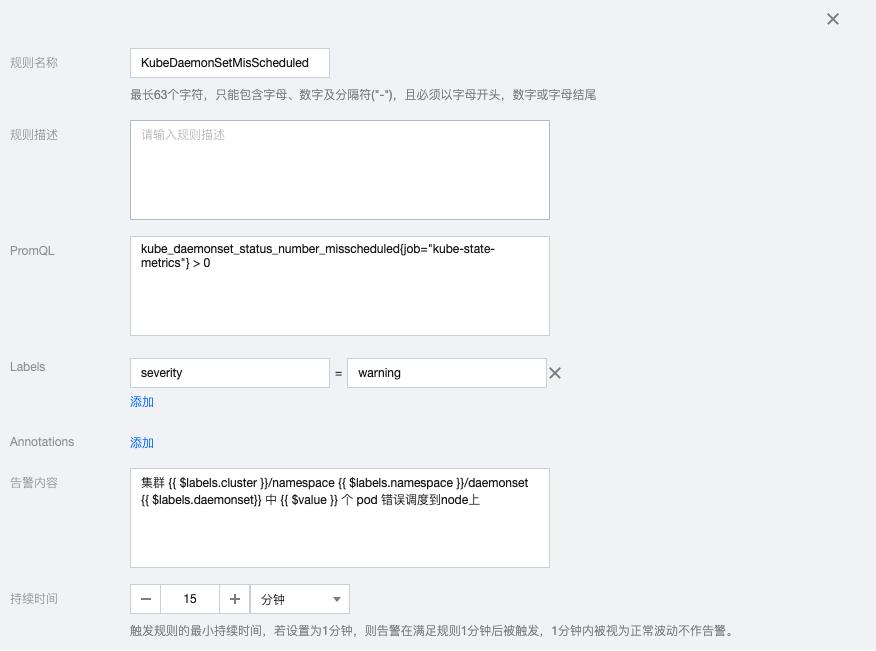
2.12 KubeJobCompletion
kube_job_spec_completions{job="kube-state-metrics"} - kube_job_status_succeeded{job="kube-state-metrics"} > 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/job {{ $labels.job_name }} 运行超过12小时
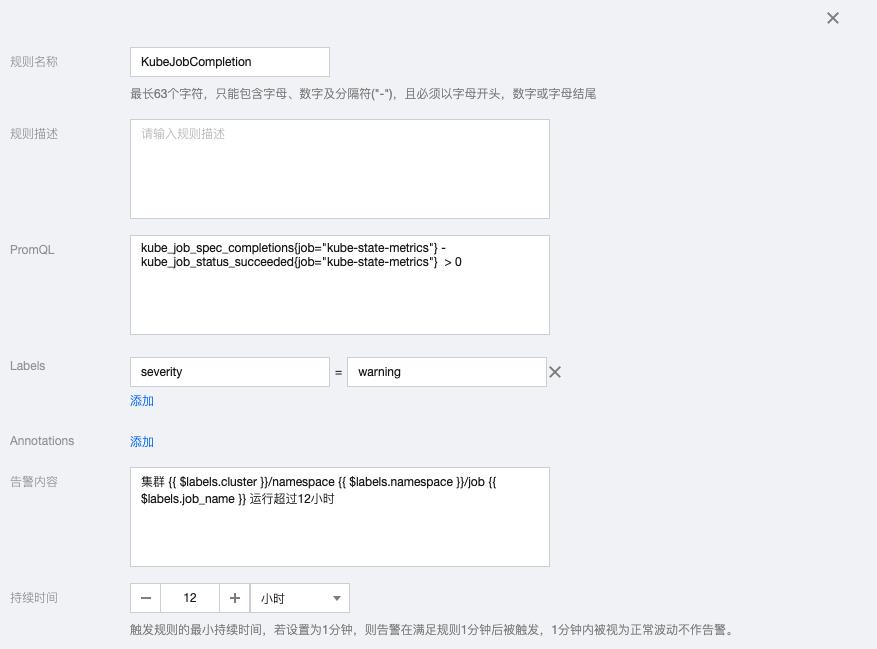
2.13 KubeJobFailed
kube_job_failed{job="kube-state-metrics"} > 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/job {{ $labels.job_name }} 执行失败
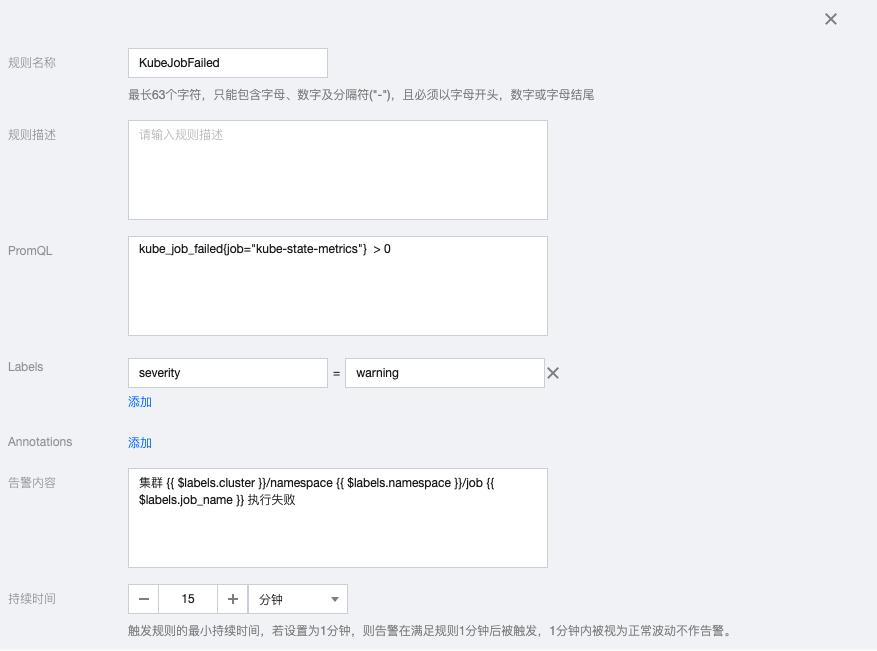
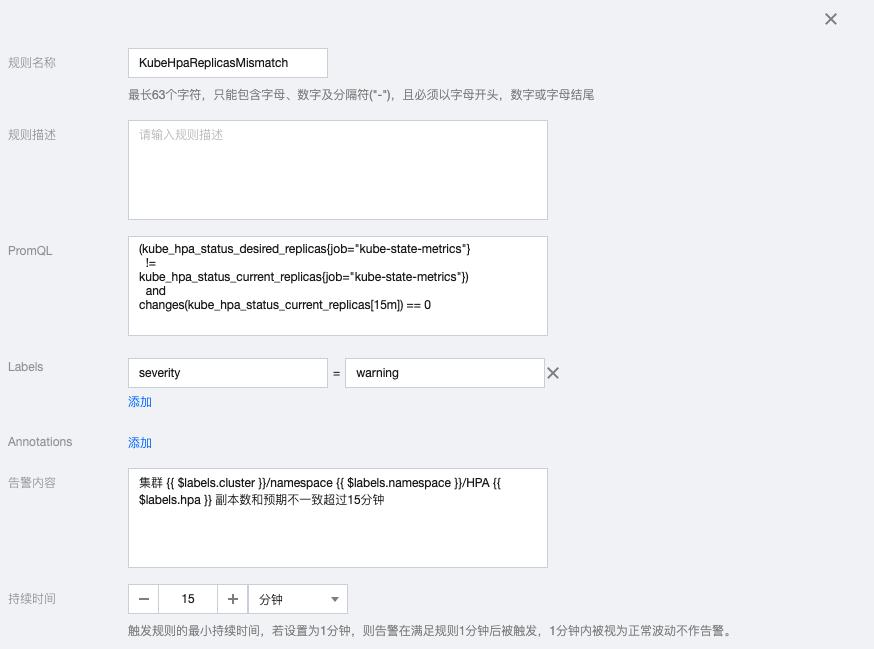
2.14 KubeHpaReplicasMismatch
(kube_hpa_status_desired_replicas{job="kube-state-metrics"}
!=
kube_hpa_status_current_replicas{job="kube-state-metrics"})
and
changes(kube_hpa_status_current_replicas[15m]) == 0告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/HPA {{ $labels.hpa }} 副本数和预期不一致超过15分钟
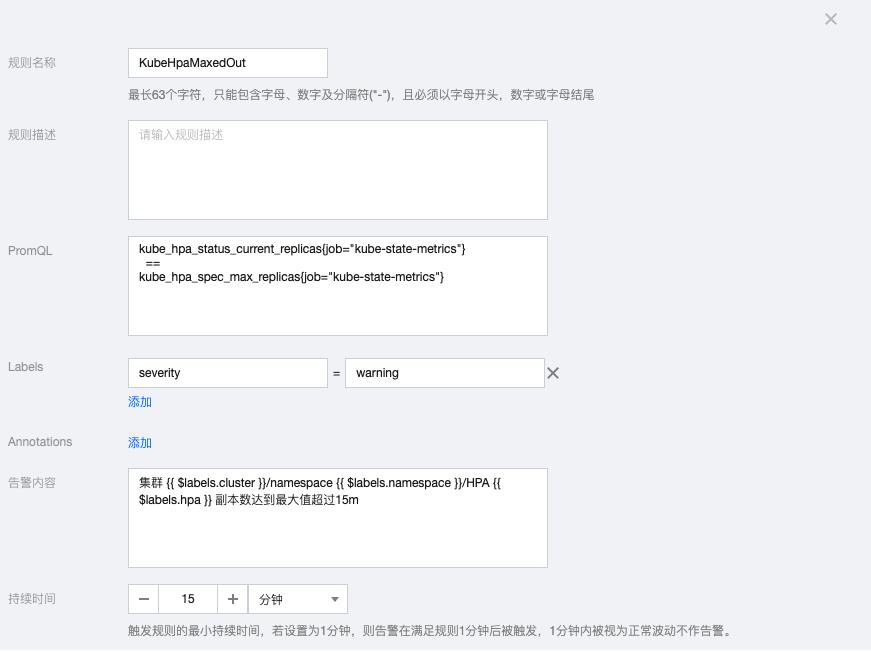
2.15 KubeHpaMaxedOut
kube_hpa_status_current_replicas{job="kube-state-metrics"}
==
kube_hpa_spec_max_replicas{job="kube-state-metrics"}告警内容:集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/HPA {{ $labels.hpa }} 副本数达到最大值超过15m
3.Kubernetes资源
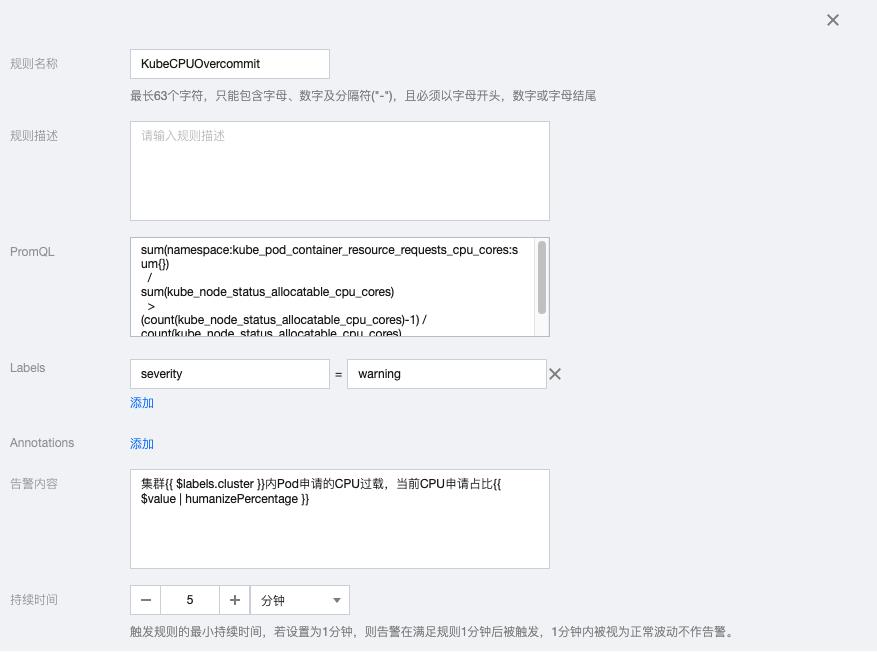
3.1 KubeCPUOvercommit
sum(namespace:kube_pod_container_resource_requests_cpu_cores:sum{}) / sum(kube_node_status_allocatable_cpu_cores) > (count(kube_node_status_allocatable_cpu_cores)-1) / count(kube_node_status_allocatable_cpu_cores)
告警内容:集群{{ $labels.cluster }}内Pod申请的CPU过载,当前CPU申请占比{{ $value | humanizePercentage }}
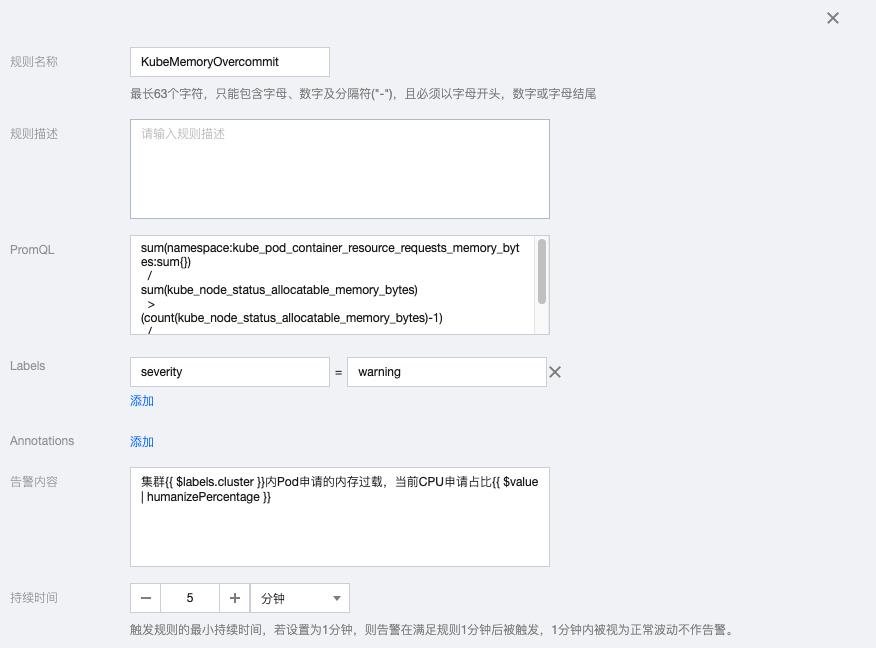
3.2 KubeMemoryOvercommit
sum(namespace:kube_pod_container_resource_requests_memory_bytes:sum{}) / sum(kube_node_status_allocatable_memory_bytes) > (count(kube_node_status_allocatable_memory_bytes)-1) / count(kube_node_status_allocatable_memory_bytes)
告警内容:集群{{ $labels.cluster }}内Pod申请的内存过载,当前CPU申请占比{{ $value | humanizePercentage }}
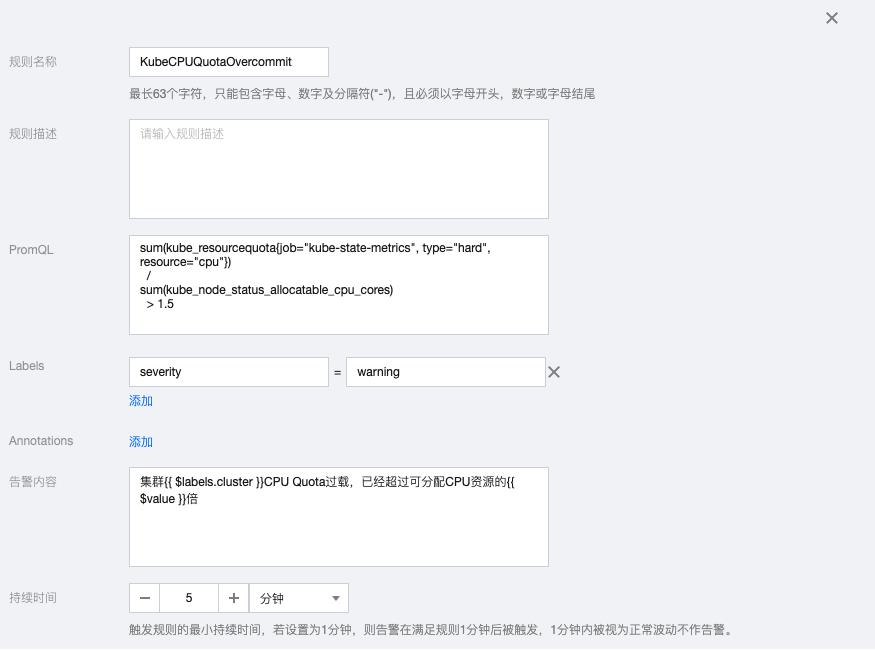
3.3 KubeCPUQuotaOvercommit
sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="cpu"})
/
sum(kube_node_status_allocatable_cpu_cores)
> 1.5告警内容:集群{{ $labels.cluster }}CPU Quota过载,已经超过可分配CPU资源的{{ $value }}倍
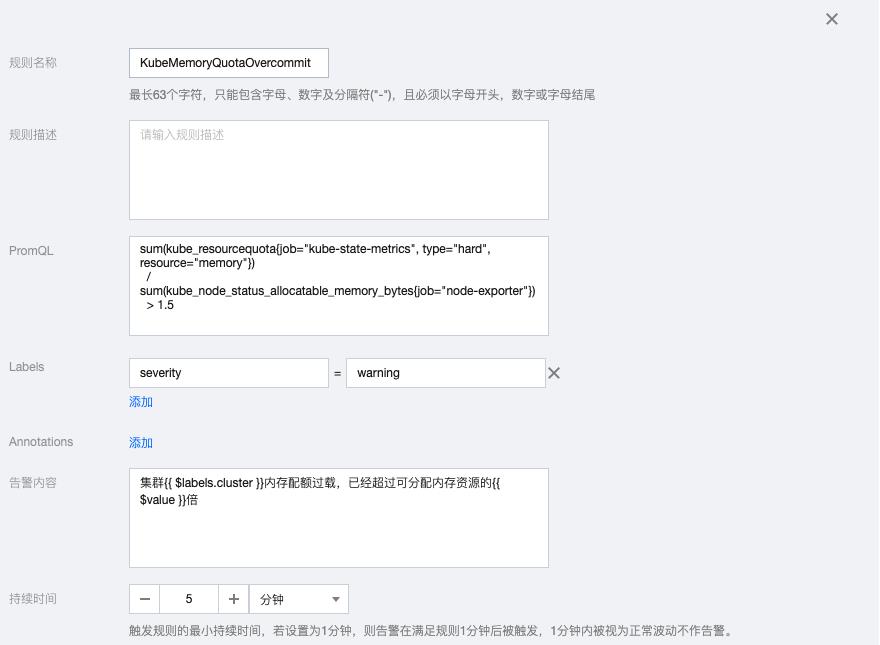
3.4 KubeMemoryQuotaOvercommit
sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="memory"})
/
sum(kube_node_status_allocatable_memory_bytes{job="node-exporter"})
> 1.5告警内容:集群{{ $labels.cluster }}内存配额过载,已经超过可分配内存资源的{{ $value }}倍
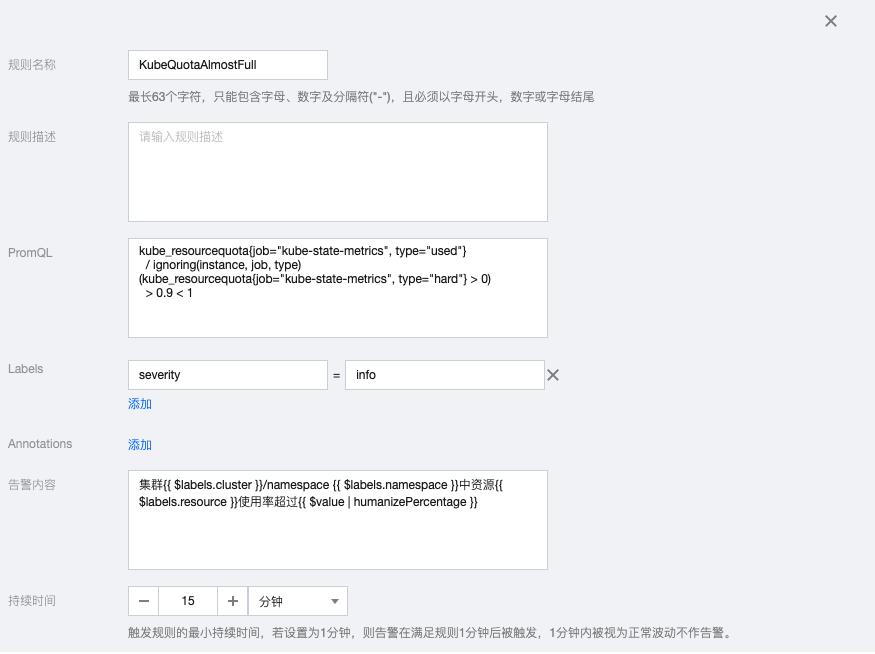
3.5 KubeQuotaAlmostFull
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 0.9 < 1告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}中资源{{ $labels.resource }}使用率超过{{ $value | humanizePercentage }}
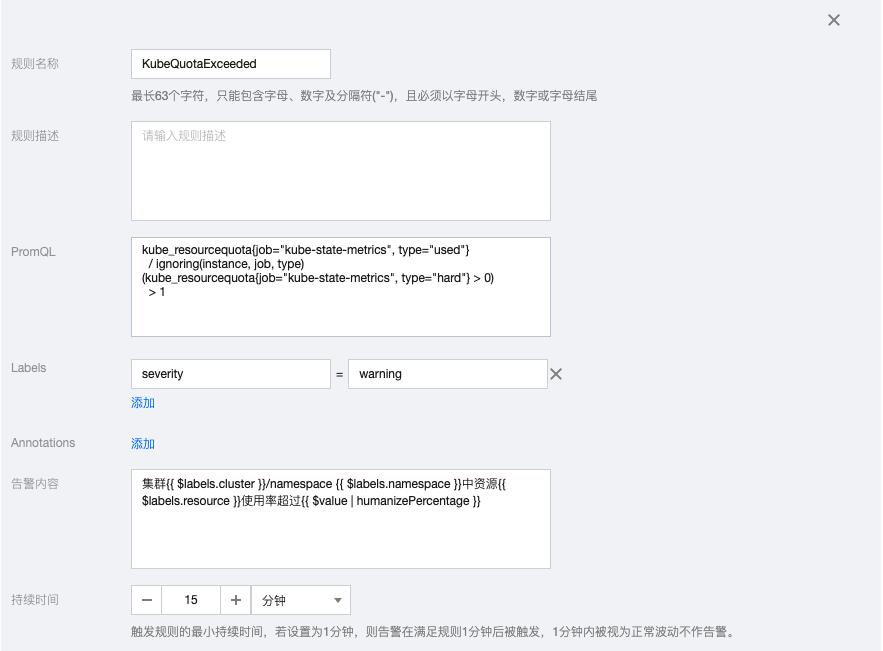
3.6 KubeQuotaExceeded
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 1告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}中资源{{ $labels.resource }}使用率超过{{ $value | humanizePercentage }}
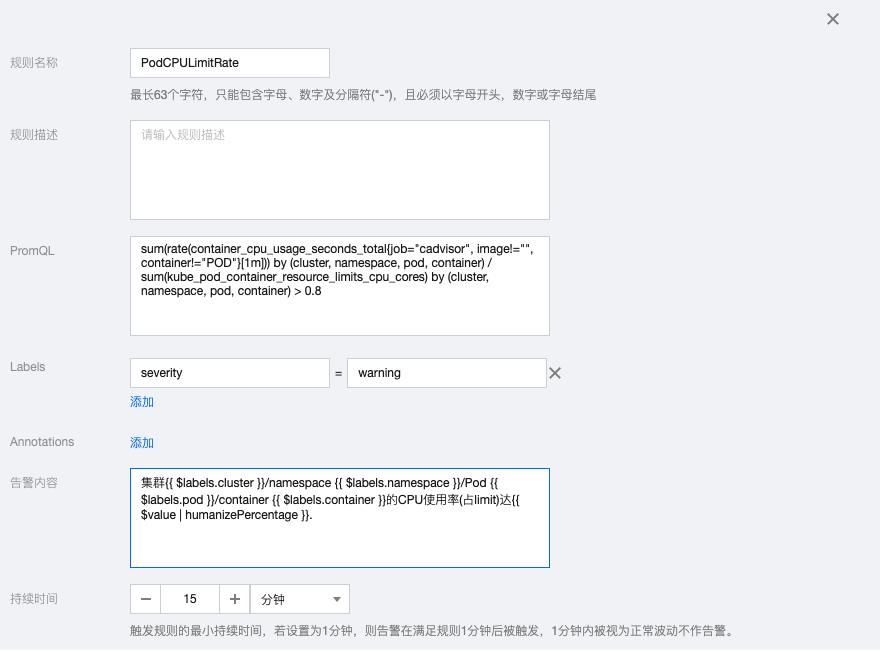
3.7 PodCPULimitRate
sum(rate(container_cpu_usage_seconds_total{job="cadvisor", image!="", container!="POD"}[1m])) by (cluster, namespace, pod, container) / sum(kube_pod_container_resource_limits_cpu_cores) by (cluster, namespace, pod, container) > 0.8告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}/container {{ $labels.container }}的CPU使用率(占limit)达{{ $value | humanizePercentage }}.
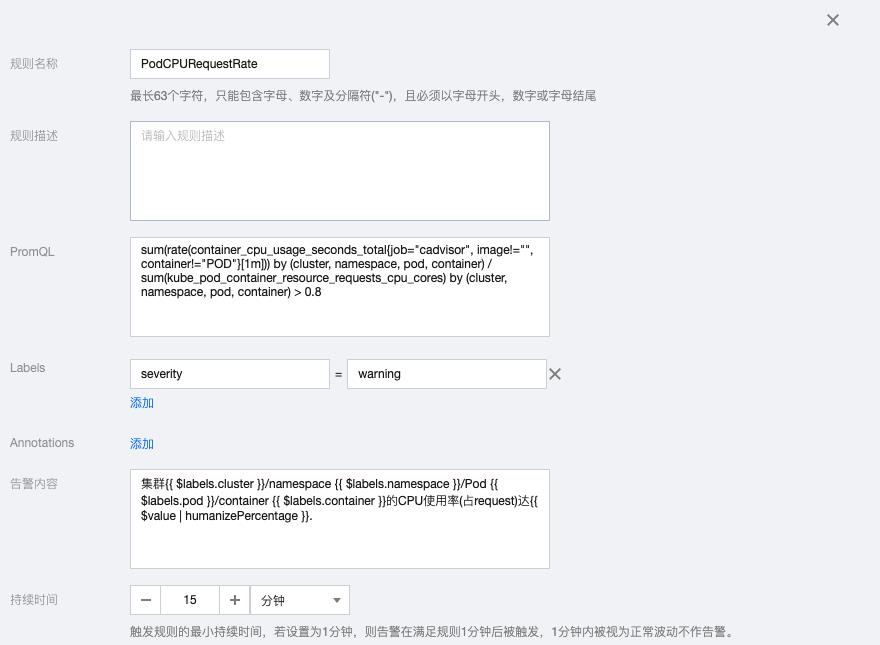
3.8 PodCPURequestRate
sum(rate(container_cpu_usage_seconds_total{job="cadvisor", image!="", container!="POD"}[1m])) by (cluster, namespace, pod, container) / sum(kube_pod_container_resource_requests_cpu_cores) by (cluster, namespace, pod, container) > 0.8告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}/container {{ $labels.container }}的CPU使用率(占request)达{{ $value | humanizePercentage }}.
3.9 PodMemoryLimitRate
sum(rate(container_memory_working_set_bytes{job="cadvisor", image!="", container!="POD"}[1m])) by (cluster, namespace, pod, container) / sum(kube_pod_container_resource_limits_memory_bytes) by (cluster, namespace, pod, container) > 0.8告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}/container {{ $labels.container }}的内存使用率(占limit)达{{ $value | humanizePercentage }}.
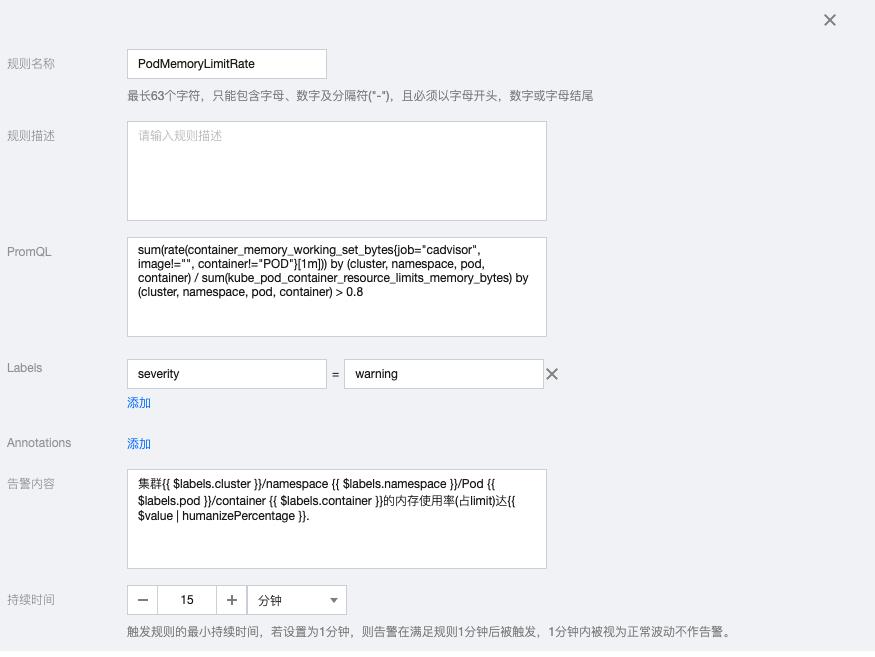
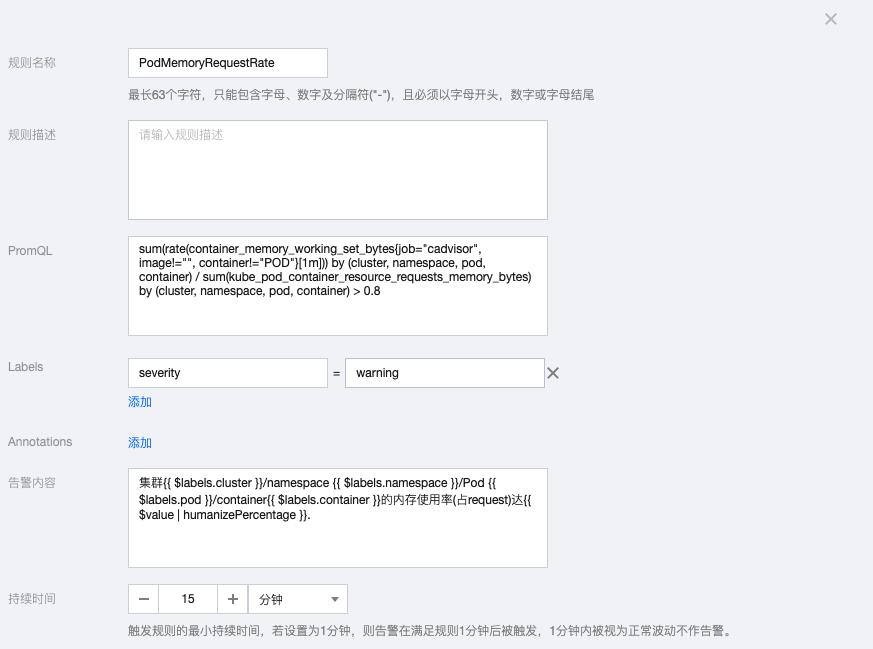
3.10 PodMemoryRequestRate
sum(rate(container_memory_working_set_bytes{job="cadvisor", image!="", container!="POD"}[1m])) by (cluster, namespace, pod, container) / sum(kube_pod_container_resource_requests_memory_bytes) by (cluster, namespace, pod, container) > 0.8告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/Pod {{ $labels.pod }}/container{{ $labels.container }}的内存使用率(占request)达{{ $value | humanizePercentage }}.
4.Kubernetes存储
4.1 KubePersistentVolumeFillingUp
kubelet_volume_stats_available_bytes{job="kubelet"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet"}
< 0.03告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/pvc {{ $labels.persistentvolumeclaim }}的存储空间只剩{{ $value | humanizePercentage }}可用
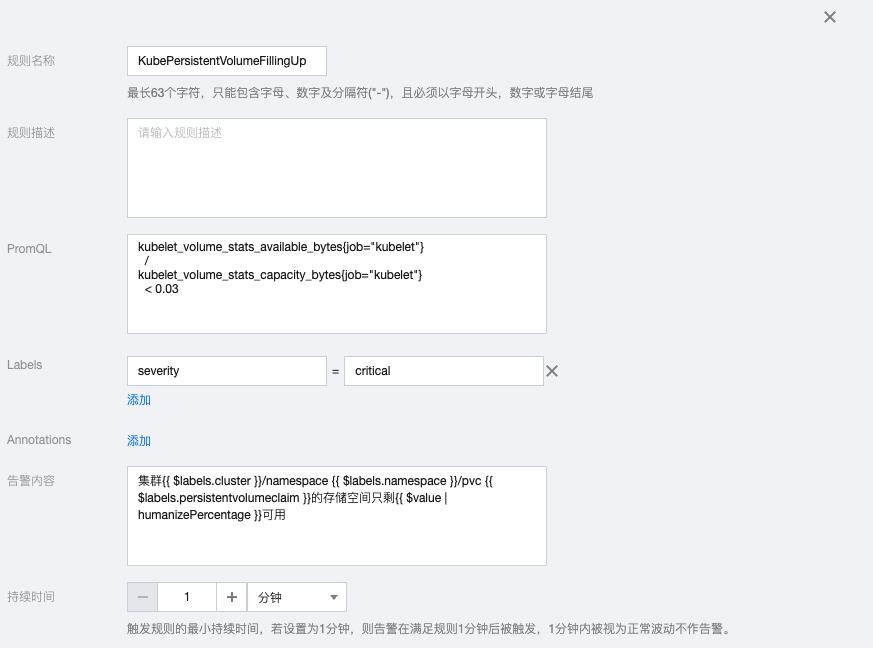
4.2 KubePersistentVolumeFillingUp
( kubelet_volume_stats_available_bytes{job="kubelet"} / kubelet_volume_stats_capacity_bytes{job="kubelet"} ) < 0.15 and predict_linear(kubelet_volume_stats_available_bytes{job="kubelet"}[6h], 4 * 24 * 3600) < 0
告警内容:集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/pvc {{ $labels.persistentvolumeclaim }}的存储空间预计4后用尽,现在还有{{ $value | humanizePercentage }}可用
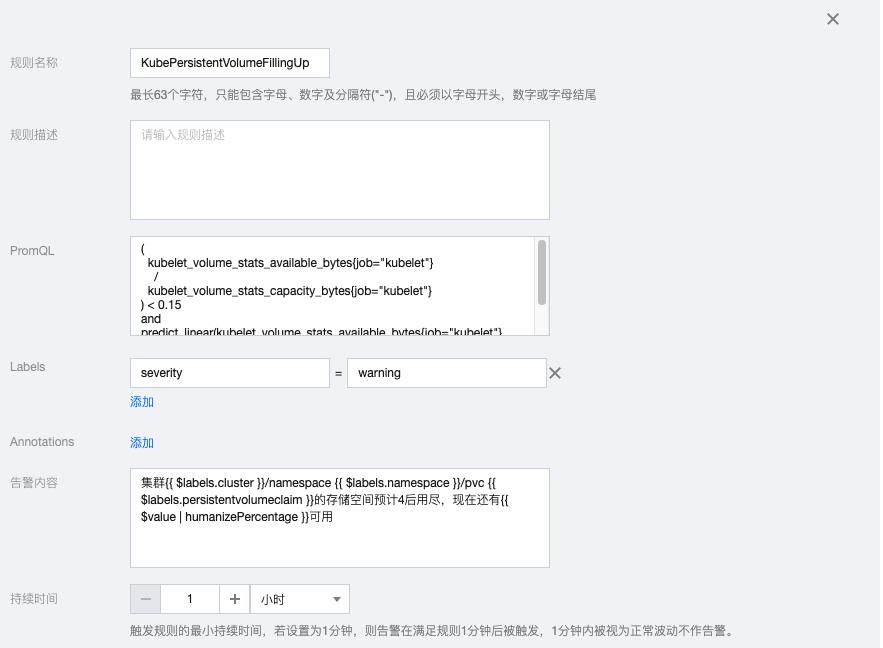
4.3 KubePersistentVolumeErrors
kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"} > 0告警内容:集群{{ $labels.cluster }}/pv {{ $labels.persistentvolume }}状态{{ $labels.phase }}
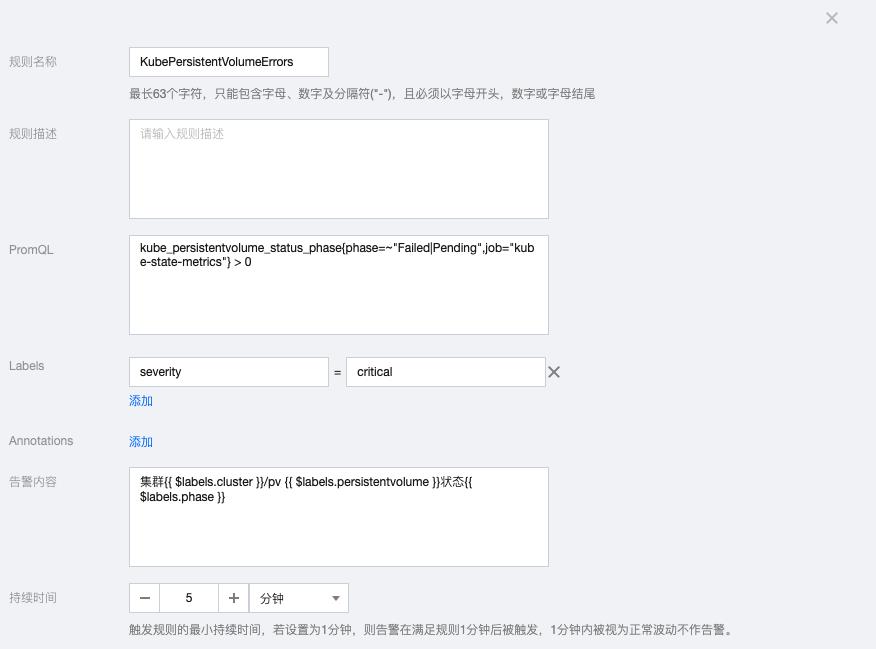
5.Kubernetes Master
5.1 KubeClientErrors
(sum(rate(rest_client_requests_total{code=~"5.."}[5m])) by (instance, job, cluster)
/
sum(rate(rest_client_requests_total[5m])) by (instance, job, cluster))
> 0.01告警内容:集群 {{ $labels.cluster }}/任务 {{ $labels.job }}/实例 {{ $labels.instance}} 访问APIServer出现{{ $value | humanizePercentage }}的错误
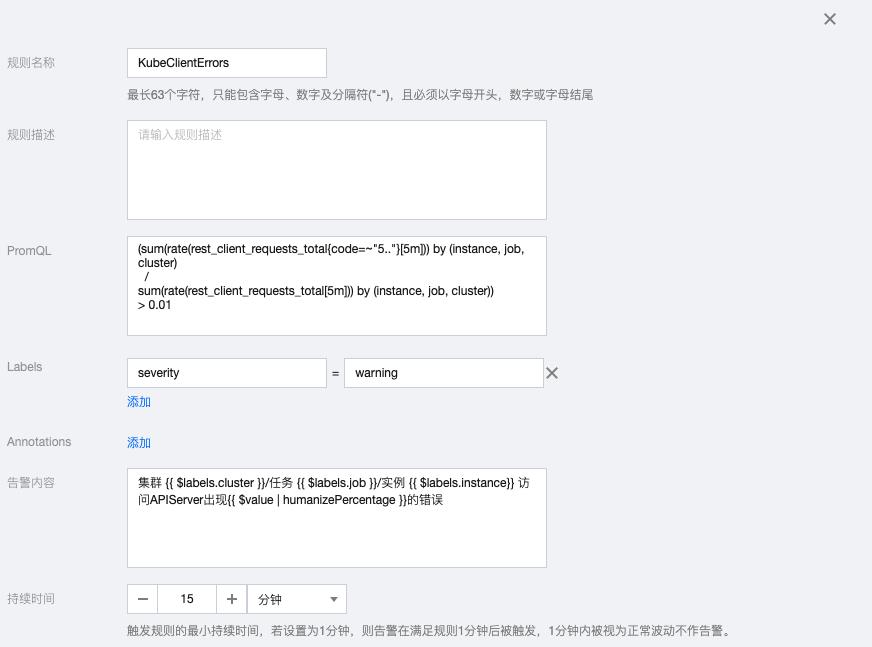
5.2 KubeClientCertificateExpiration
apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(cluster, job) histogram_quantile(0.01, sum by (cluster, job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 86400告警内容:访问集群{{ $labels.cluster }} apiserver的客户端证书将在24小时后过期。
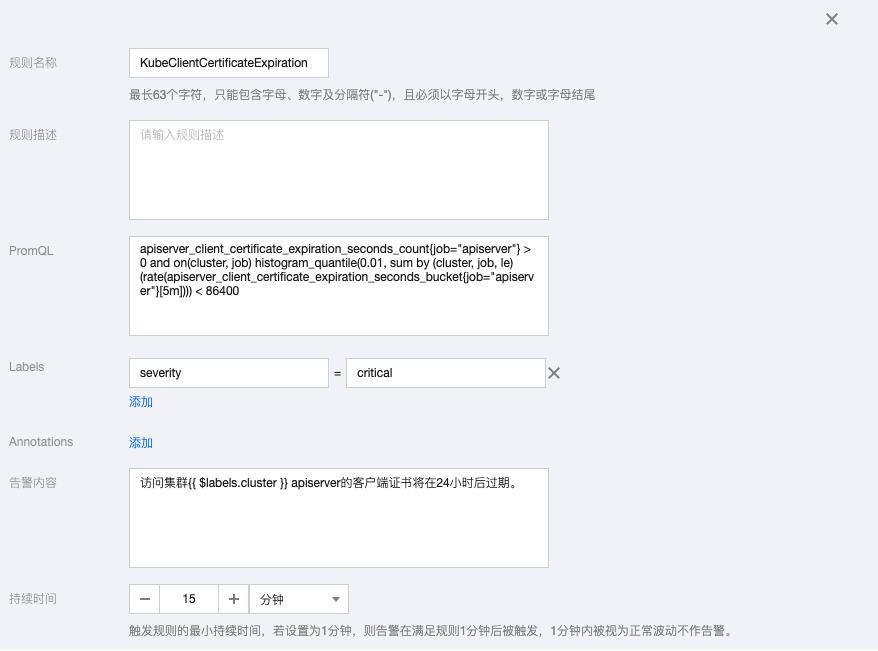
5.3 KubeAPIDown
sum(up{job="kube-apiserver"}) by (cluster) == 0告警内容:集群 {{ $labels.cluster }} 的kube-apiserver没有运行
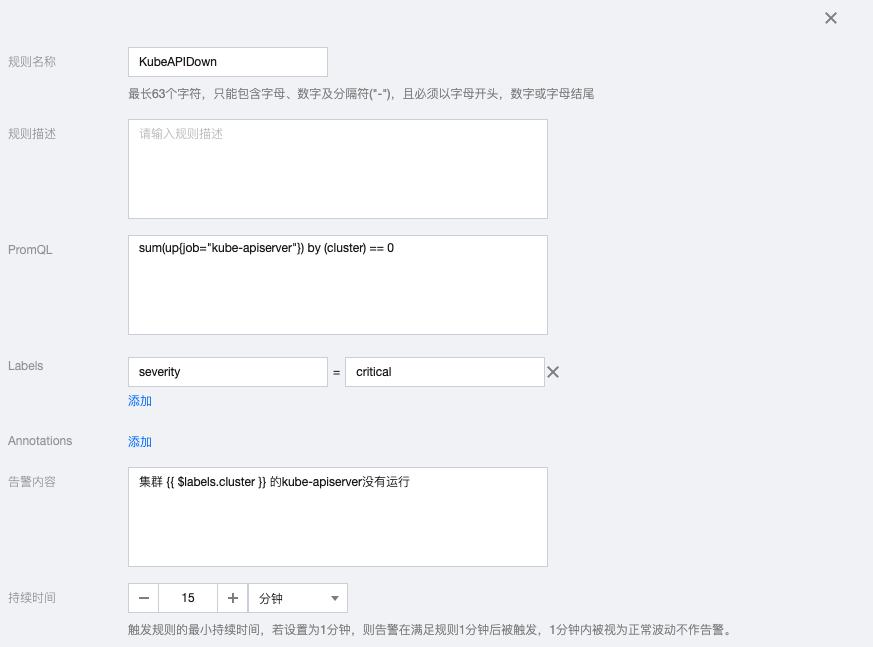
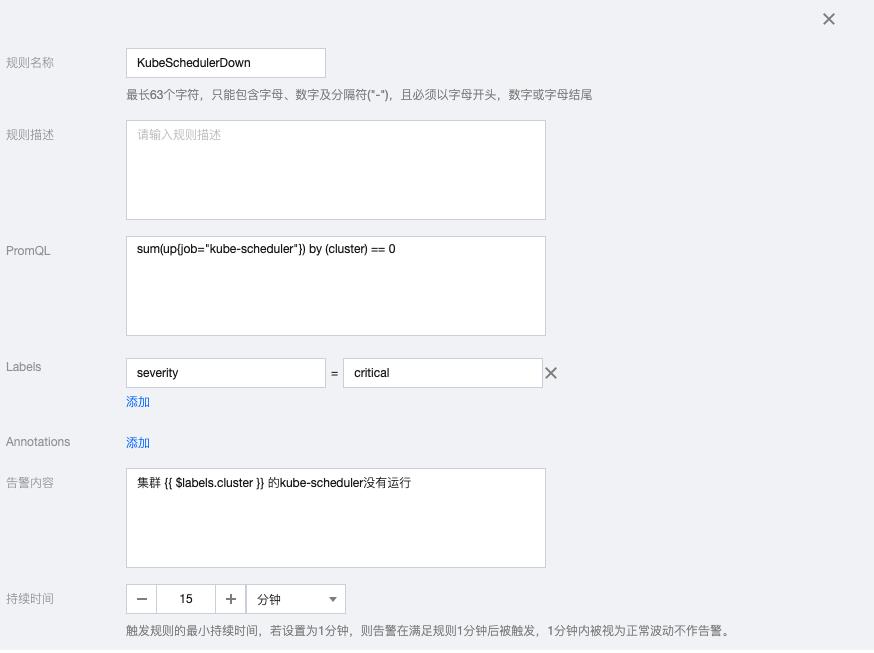
5.4 KubeSchedulerDown
sum(up{job="kube-scheduler"}) by (cluster) == 0告警内容:集群 {{ $labels.cluster }} 的kube-scheduler没有运行
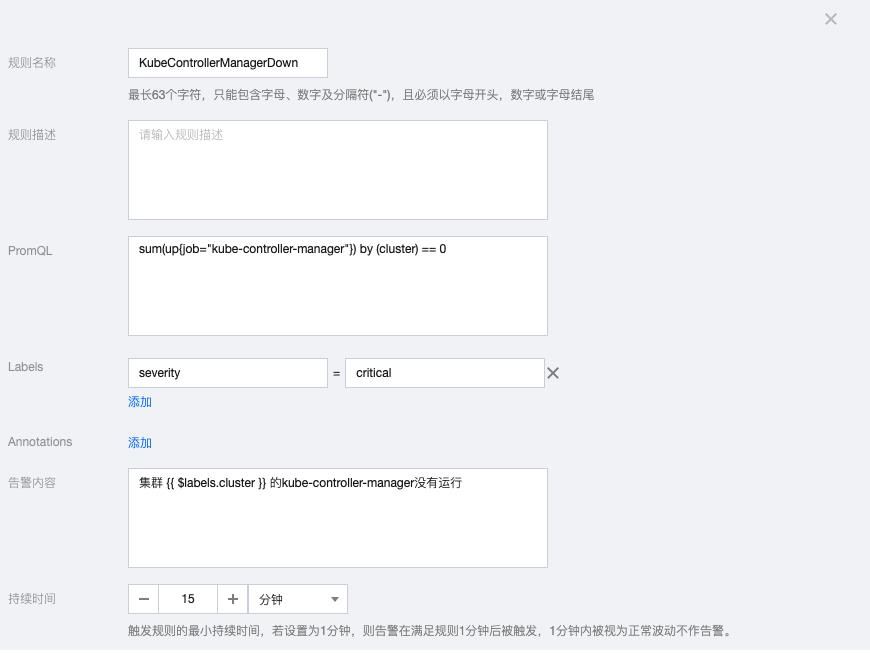
5.5 KubeControllerManagerDown
sum(up{job="kube-controller-manager"}) by (cluster) == 0告警内容:集群 {{ $labels.cluster }} 的kube-controller-manager没有运行
6.Kubernetes kubelet
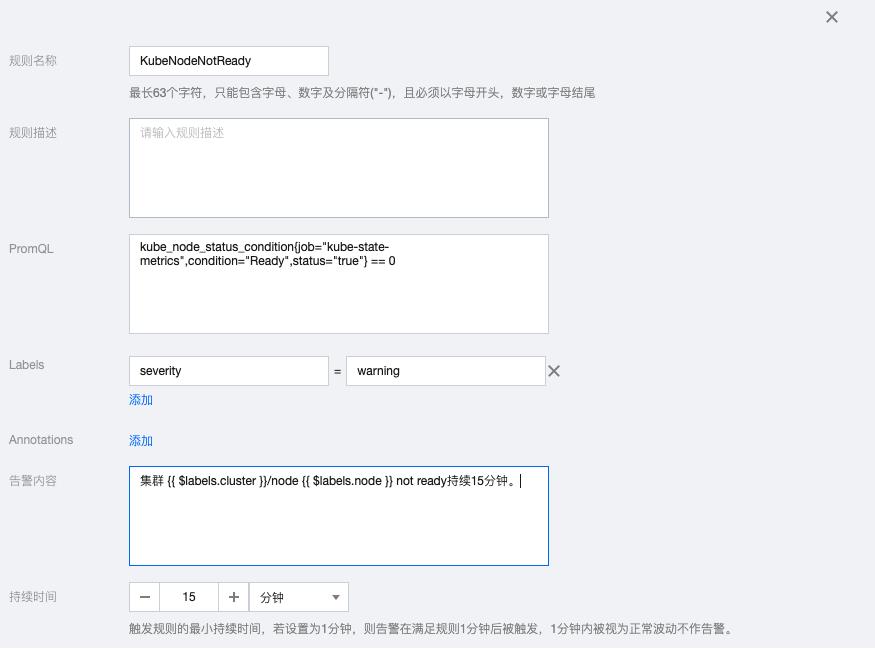
6.1 KubeNodeNotReady
kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"} == 0告警内容:集群 {{ $labels.cluster }}/node {{ $labels.node }} not ready持续15分钟。
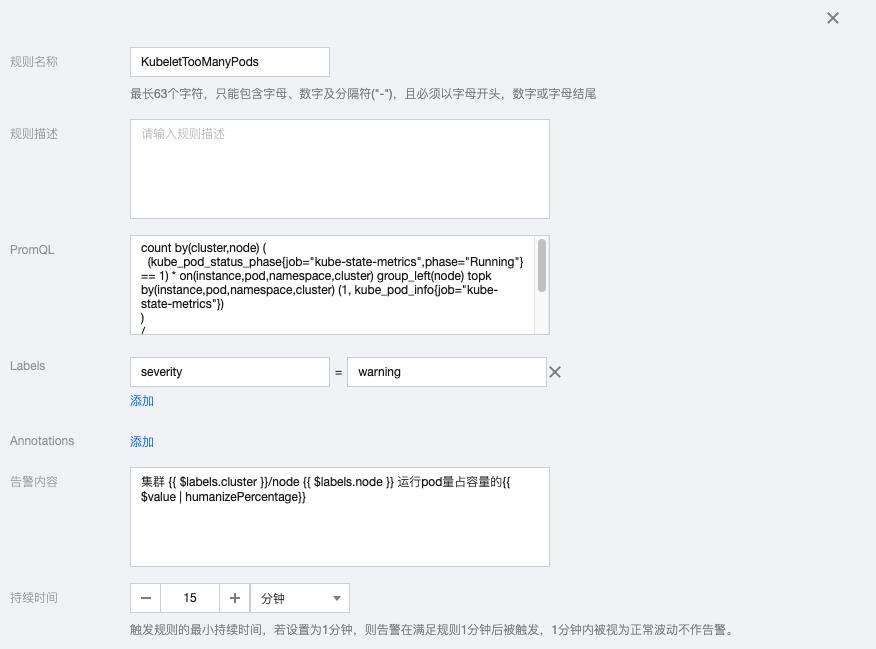
6.2 KubeletTooManyPods
count by(cluster,node) ( (kube_pod_status_phase{job="kube-state-metrics",phase="Running"} == 1) * on(instance,pod,namespace,cluster) group_left(node) topk by(instance,pod,namespace,cluster) (1, kube_pod_info{job="kube-state-metrics"}) ) / max by(cluster,node) ( kube_node_status_capacity_pods{job="kube-state-metrics"} != 1 ) > 0.95
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.node }} 运行pod量占容量的{{ $value | humanizePercentage}}
6.3 KubeletClientCertificateExpiration
kubelet_certificate_manager_client_ttl_seconds < 86400
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.node }}上kubelet客户端证书将在{{ $value | humanizeDuration }}后过期
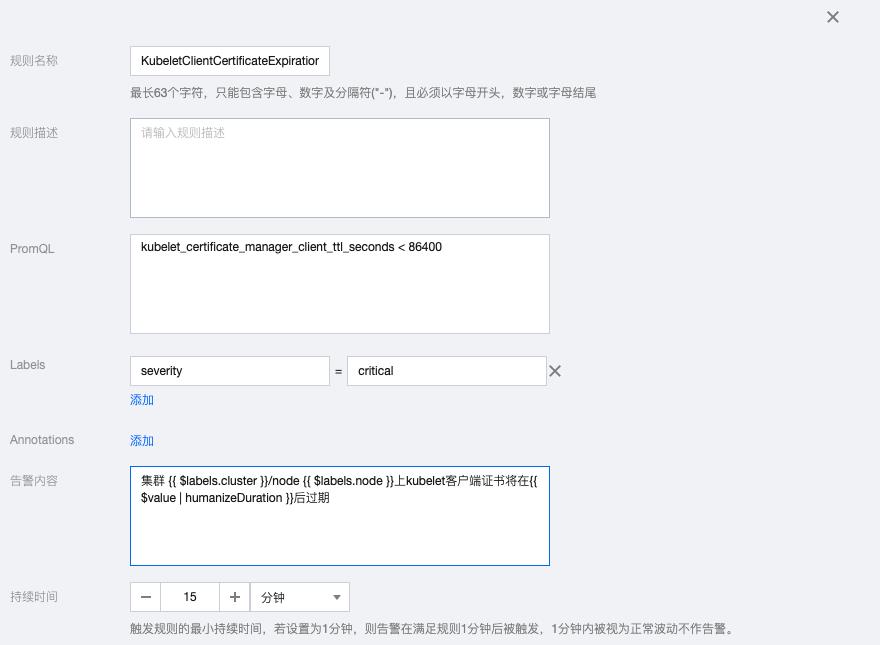
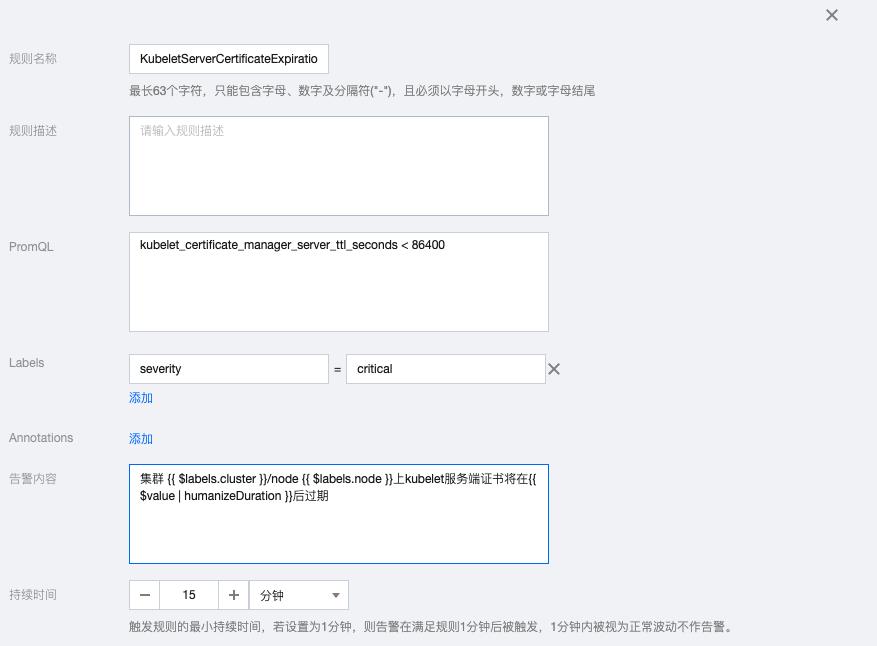
6.4 KubeletServerCertificateExpiration
kubelet_certificate_manager_server_ttl_seconds < 86400
告警内容:集群 {{ $labels.cluster }}/node {{ $labels.node }}上kubelet服务端证书将在{{ $value | humanizeDuration }}后过期
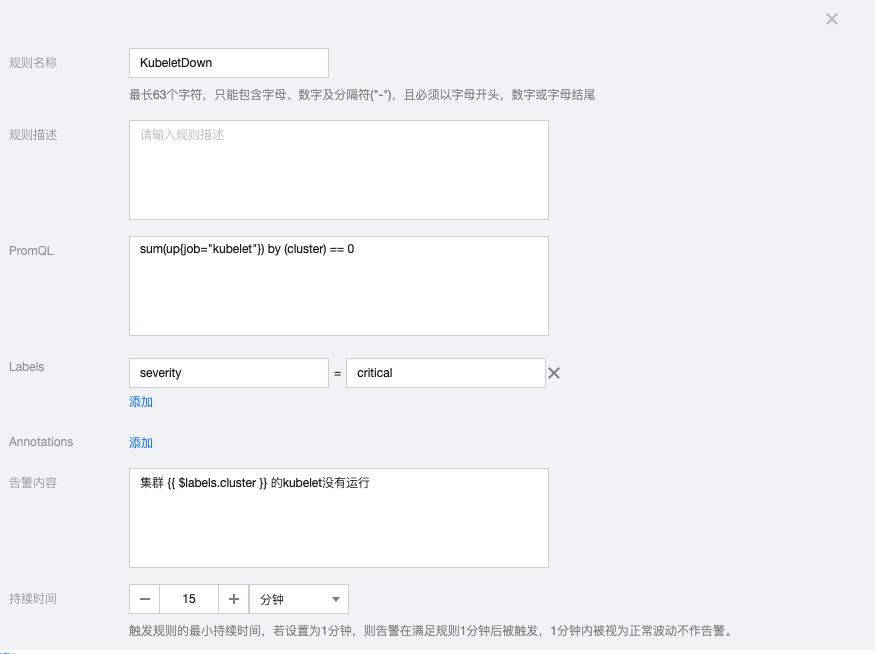
6.5 KubeletDown
sum(up{job="kubelet"}) by (cluster) == 0告警内容:集群 {{ $labels.cluster }} 的kubelet没有运行
7.参考
以上告警规则参考腾讯云原生监控,当然,在prometheus-operator中也有很多默认规则可以参考,具体见以下链接:https://github.com/prometheus-operator/kube-prometheus/tree/main/manifests