前戏部分
模块,用一堆(很多行)代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来说,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
其实模块只是有很多 Python 代码的一个文件;要注意的是:模块名字是区分大小写的。
如:os 是系统相关的模块
模块分为三种:
自定义模块
[root@localhost python3]# cat >>modules_test.py<<eof
> #!/usr/bin/env python3
> # 在计算机中创建一个含有 Python 代码的文件,可实现一个或
> # 多个功能的文件,就是自定义了一个模块,这个文件就称为自定义模块
> # 下面就是用一个函数来实现一个打印传入参数的功能。
> # 以及声明了一个变量
>
> def func(*args): # 定义一个函数
> print('传入的函数参数是:', args)
>
> test_val='from modules_test's values' # 定义一个变量
> eof
[root@localhost python3]# python3
Python 3.6.0 (default, Feb 6 2017, 04:32:17)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import modules_test # 导入模块名称,不含 .py 哦
>>> modules_test.func('a',1,'b',2) # 使用模块的功能:模块名.函数
传入的函数参数是: ('a', 1, 'b', 2)
>>> modules_test. # 在linux系统中按两次 Tab 键会看到模块下的功能或方法
modules_test.func( modules_test.test_val
>>> modules_test.test_val # 使用模块的功能: 模块名.变量名
"from modules_test's values"
>>>第三方模块
第三方模块就是很多 Python 开发者贡献的,已经写好的可以实现某些功能的模块。
获取方法网络下载,这里举个第三方模块的例子: requests
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作
官网网站安装链接:http://www.python-requests.org/en/master/user/install/#install
安装方法:
Python3.x 的 pip3 安装方法:[root@localhost python3]# pip3 install requests # 可能需要你先解决,HTTPS/SSL 的安全认证问题Python2.x 的安装方法:需要先安装 pip,再用下面的方法:[root@localhost python3]# pip install requests源码安装,先把源码 Tarball 包下载到本地,执行如下命令:[root@localhost python3]# curl -OL https://github.com/kennethreitz/requests/tarball/master [root@localhost python3]# cd kennethreitz-requests-d6f4818/ [root@localhost kennethreitz-requests-d6f4818]# python3 setup.py install ************略************** creating dist creating 'dist/requests-2.13.0-py3.6.egg' and adding 'build/bdist.linux-x86_64/egg' to it removing 'build/bdist.linux-x86_64/egg' (and everything under it) Processing requests-2.13.0-py3.6.egg creating /usr/local/lib/python3.6/site-packages/requests-2.13.0-py3.6.egg Extracting requests-2.13.0-py3.6.egg to /usr/local/lib/python3.6/site-packages Adding requests 2.13.0 to easy-install.pth file Installed /usr/local/lib/python3.6/site-packages/requests-2.13.0-py3.6.egg Processing dependencies for requests==2.13.0 # 上面倒数第二行表示这个模块被默认到的目录 [root@localhost kennethreitz-requests-d6f4818]# python3 >>> import requests >>>
内置模块
内置模块时 Python 自带的,也叫标准库
Python 的一个显著特点就是具有庞大的模块标准库,可以执行很多有用的任务,并且和核心语言分开,避免臃肿.
官方文档: https://docs.python.org/3/library/
使用指南: https://docs.python.org/3/tutorial/stdlib.html
Doug Hellmann 的网站: https://pymotw.com/2/contents.html
Doug Hellmann 的书: Python standard Library by Example
举几个常用的内置模块,os,sys,random 等,后面会有详解
独立的程序
之前我所演示的例子都是在 Python 解释器里直接运行的 Python 代码。
现在我决定给你分享怎么写一个 Python 程序,并且执行它。
# 先有 vi 等文本编辑器,编辑一个空文本,写入代码 [root@localhost ~]# cat hello.py #!/usr/bin/env python3 # 指定程序解释器 print('Hello world') # Python 代码 # 执行 Python 程序方法一: [root@localhost ~]# python3 hello.py Hello world # 执行 Python 程序方法二: [root@localhost ~]# chmod a+x hello.py #先把文件添加上可执行权限 [root@localhost ~]# ./hello.py Hello world [root@localhost ~]#
模块的导入
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,
如果想要使用模块,则需要导入。基本的导入方法:
import 模块名
模块名 是不含 .py 的文件名
# 可以一次只导入一个模块 >>> import os # 也可以一次导入多个模块,模块之间用英文的逗号 “,” 隔开 >>> import os,sys
使用别名导入模块
在导入模块时,给它起个别名,可以解决导入同名但含有不同功能的模块,或者使用相对较短好记的名字
>>> import datetime as dt # as 后面跟模块的别名 >>>
导入模块的一部分
有时候你只是想要一个模块中的某一个或几个功能;就要用如下格式:
from 模块名 impot 功能1,功能2
警报: 这对 from … import … 的方式, import 后边跟的必须是一个或多个明确的对象。
其后面不能有含点的形式
比如 form package import mod.func # invalid syntax 语法错误
# 从 os 模块中只导入 system和chdir 方法 >>> from os import system,chdir >>> system('pwd') # 使用方法时,可以直接使用,不用 os.system 的形式 /root # shell 命令执行结果 0 # shell 命令执行结果的返回值 >>> chdir('/home') >>> system('pwd') /home 0 >>>
模块搜索路径
Python 在导入模块时,从哪些路径去找这个模块的文件呢?
1. 首先会先从内置的标准库中找
2. 再从sys.path 定义的路径中依次寻找,先被找到的模块,会生效。之后有同名的模块将不会生效。
下面是 Linux 环境下的 Python3 的路径
>>> import sys >>> sys.path ['', '/usr/local/lib/python36.zip', '/usr/local/lib/python3.6', '/usr/local/lib/python3.6/lib-dynload', '/r oot/.local/lib/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages']# 可以看到上面是个列表,所以这个是可以被修改的,可以添加自定义的路径>>> for path in sys.path: ... print(path) ... # 此行是空,就是上面 sys.path 输出中的 '' ,就是当前目录 /usr/local/lib/python36.zip /usr/local/lib/python3.6 /usr/local/lib/python3.6/lib-dynload /root/.local/lib/python3.6/site-packages /usr/local/lib/python3.6/site-packages # 一般我们下载好的第三方模块,会放在这个目录下 >>>
自定义的模块名一定不要与系统内置或第三方的模块同名
包以及包的导入
我们已使用过单行代码、多行代码的函数、独立的程序以及同一目录下的多个模块。
为了使 Python 引用更具可扩展性,你可以把多个模块组织成有层次的文件夹和文件,称之为包。
包的本质其实就是一个包含 __init__.py 文件的目录,__init__.py文件可以为空。
不同名称的包下面可以有相同的模块名,如 package_a下有模块mod,表示为:package_a.mod,
而package_b下也有模块mod,表示为:package_b.mod,两个mod并不会冲突,
因为他们分别在不同的命名空间里(package_a和pacaage_b);
包是以 .模块名 (注意那个点)来组织 Python 模块 名称空间的方式。
注意:自定义的包名一定不要和自定义的模块名同名,也不要与系统内置的模块名或第三方同名
包之上还可以是包,可以组成一个大包
[root@localhost python3]# tree . ├── glance │ ├── api │ │ ├── __init__.py │ │ └── modles.py │ ├── db │ │ ├── __init__.py │ │ └── modles.py │ └── __init__.py ├── namespace.py └── package ├── __init__.py ├── __pycache__ │ ├── __init__.cpython-36.pyc │ └── test.cpython-36.pyc └── test.py 5 directories, 10 files [root@localhost python3]#警报:
无论是 import … 形式,还是 from … import … 形式,凡是在导入语句中(而不是在使用时)遇到带
点的,都要第一时间提高警觉:这是关于包才有的导入语法。所有导入方法中,每一个点的左边必须是一个包!
from glance.db import models models.db_func() form glance.db import models as x x.func() from glance.api.models import func1 func1()
__init__.py 文件的用途
1. 不管是哪种方式的导入,只要是第一次导入包或者导入包的任何部分,都会先依次执行包下的 __init__.py 文件
可以在此文件里写一些代码验证,因此可在此文件中写一些初始化包的代码
2. 在导入模块时,也有这样一种方式, from modles import *
可导入模块的所以功能(函数、变量等),但是并不建议这么去做,了解即可。
在这里要说的是,这种导入包的方式,实际上只是执行了要导入包所经过的路径包下的 __init__.py文件;
# 先看一下我在每个包的 __init__.py 文件里都放入的代码 [root@localhost python3]# cat glance/__init__.py print("from ===>glance package") [root@localhost python3]# cat glance/db/__init__.py print('from ===> db package') [root@localhost python3]# cat glance/api/__init__.py print('from ===> api package') __all__=['func1','func2'] api_val='我是api的测试变量' [root@localhost python3]# # 进行导入测试 [root@localhost python3]# python3 Python 3.6.0 (default, Feb 6 2017, 04:32:17) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import glance.api # 导入glanc包下的api包 from ===>glance package # 执行glance 包下的__init__.py文件 from ===> api package # 这里并没有执行 db 包中的 __init__.py文件 >>> exit() [root@localhost python3]# python3 Python 3.6.0 (default, Feb 6 2017, 04:32:17) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from glance.db import modules # 第一次导入glance.db包下的modules from ===>glance package # 执行glance 包下的__init__.py文件 from ===> db package # 执行db 包下的__init__.py文件 >>> from glance.db.modules import db_func # 第二次导入并不会执行__init__.py 文件 >>> db_func <function db_func at 0x7f4ef92b7488> >>> db_func() I am db package models db_func >>>因此,我们可以在这个文件里自定义要导入包时,有选择性的导入需要的模块或功能。
就是上面包 api 下的__init__.py文件中的
[root@localhost python3]# cat glance/api/__init__.py print('from ===> api package') __all__=['func1','func2'] api_val='我是api的测试变量' [root@localhost python3]# python3 [root@localhost python3]# python3 Python 3.6.0 (default, Feb 6 2017, 04:32:17) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from glance.api import * from ===>glance package from ===> api package Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: module 'glance.api' has no attribute 'func1' # 从上面的报错信息可以看出,在__all__变量的值中的名称,必须是在包的同级目录下的模块 >>> exit() [root@localhost python3]# vi glance/api/__init__.py [root@localhost python3]# python3 Python 3.6.0 (default, Feb 6 2017, 04:32:17) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from glance.api import * from ===>glance package from ===> api package >>> modules. modules.func1( modules.func2( modules.modules_val >>> modules.func1() I am from api's modles's func1 >>> import os >>> os.system('cat glance/api/__init__.py') print('from ===> api package') __all__=['modules'] # 修改后,只在__all__中添加了 modules 模块名 api_val='我是api的测试变量' 0 >>> api_val # 但是并没有在__all__中添加 api_val 变量名,就会有下面的报错了 Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'api_val' is not defined >>> exit() [root@localhost python3]# vi glance/api/__init__.py [root@localhost python3]# cat glance/api/__init__.py print('from ===> api package') #__all__=['modules'] # 把此行注释 api_val='我是api的测试变量' [root@localhost python3]# python3 Python 3.6.0 (default, Feb 6 2017, 04:32:17) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from glance.api import * from ===>glance package from ===> api package >>> api_val # 注释__all__ 后,变量名 api_val 生效了 '我是api的测试变量' >>> modules.func1() # 但是,包下面的模块没有声明,就不会生效了 Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'modules' is not defined >>> # 总结一下: __init__.py 文件中通过 __all__ = ['模块名','变量名'] 的方式,可以控制在用 # import * 的方式时,在包下面的哪些变量、函数或者功能可生效
常用内置模块
一、sys
用于提供对Python解释器相关的操作:
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdin 输入相关 sys.stdout 输出相关 sys.stderror 错误相关
二、os
用于提供对操作系统级别的操作:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.getpid() 获取当前 Python解释器或者pytho运行中程序的进程号
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.chmod('filename',0O4) 改变文件的权限第一参数是文件名,0o是零和小写字母o,后面跟三维的 8 进制的数字,
分别对应所属主所属组其他人,比如将文件设为0o764 的权限就是-rwxrw-r--
os.chown('filename',uid,gid)修改一个文件的所属主和所属组,即 uid/gid 都必须是系统中存在的,而且是整数形
式,并不是用户名和用户组,当然也支持这种形式 :
os.chown('filename',uid=1000,gid=0)
os.link('源文件名','硬链接文件名') 给文件建硬链接,可以是绝对或者相对路径
os.symlink('源文件名','软连接文件名') 给文件建软链接,可以是绝对或者相对路径
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为" ",Linux下为" "
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示;它的执行方式是,每次执行都会重新打开一个shell,
在新的shell里执行命令,执行结束后就退出当前执行命令的shell。
并且返回的仅是执行命令结果的状态码,而非命令结果本身。
os.popen("bash command") 这个和上面的一样,唯一不同的是,返回命令执行结果本身的一个对象,可以对这个对象进行操作;
方法是: reslut = os.popen("bash command").read()
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.realpath('/home/yikes.file') 从一个链接文件,查找源文件的绝对路径位置,链接文件可以似乎软链接和硬链接
os.path.dirname(path) 返回path的去掉路径中以的最后一个元素后的路径;是os.path.split(path)的第一个元素;
不过有两种情况
>>> os.path.dirname('/root/a/b/ab.txt/') # 当以 / 为结尾时,返回全部路径
'/root/a/b/ab.txt'
>>> os.path.dirname('/root/a/b/ab.txt') # 当不是以 / 为结尾时,返回的是去掉最后一个元素的路径
'/root/a/b'
>>> os.path.split('/root/a/b/ab.txt/') # 当以 / 为结尾时,路径变成元组的一个整体的元素
('/root/a/b/ab.txt', '')
>>> os.path.split('/root/a/b/ab.txt') # 当不是以 / 为结尾时,路径变成元组的两个元素
('/root/a/b', 'ab.txt')
>>>
os.path.basename(path) # 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。
# 即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
# 在这里值得注意的是,在Linux shell 中,Python会认为: / 左边一定是一个目录,而不是文件;
# 这里建议一个习惯,在写路径时候,无论最后的是不是目录,都不要在最后写上 / ;这样就不会混淆了。
>>> os.path.exists('/root/a/b/ab.txt')
True
>>> os.path.exists('/root/a/b/ab.txt/') # python 会认为 / 左边的ab.txt文件是他目录,但去校验是,不是,所以返回 False
False
>>> os.path.exists('/root/a/b/')
True
>>>
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join("path1","path2","path3") 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略,路径中不用加斜杠,除非定义一个跟路径,需要在第一个路径前加斜杠
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间,不过这个时间是从1970.01.01到创建时的时(秒)
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
补充
glob 模块
glob 模块可以利用 Linux、Unix系统中的通配符(而非正则)去匹配获取系统中的文件名或目录名
* 匹配任意零到多个字符
? 匹配任意一个字符
[abc] 匹配任意一个括号内的字符,也支持[a-zA-Z0-9]
[!abc] 匹配非括号内的任意一个字符,即不含 a 或 b 或 c 同样支持 [a-zA-Z0-9]
>>> import glob
>>> glob.
glob.escape( glob.glob1( glob.magic_check_bytes
glob.fnmatch glob.has_magic( glob.os
glob.glob( glob.iglob( glob.re
glob.glob0( glob.magic_check
>>> glob.glob('/home/*') # 查找 home 目录下的所以文件
['/home/shark', '/home/yikes.file']
>>> glob.glob('/home/*.file') # 找任意字符开头,以 .file 结尾的文件
['/home/yikes.file']
>>> glob.glob('/home/yik??.file') # 找以 yik开头后面有任意 2 个字符,以 .file 结尾的文件
['/home/yikes.file']
>>> glob.glob('/home/[yY]ik??.file') # 找以 y 或者 Y 开头,后面是 ik 再紧随的是任意两个字符,以 .file 结尾的文件
['/home/yikes.file']
>>> glob.glob('/home/[!rs]*') # 查找不是以 r 或者 s 开头的任意文件
['/home/yikes.file']
>>>
三、random & string
random 模块,可从一个可迭代队列中随机取出一个元素
>>> random.random() # 随机 0 到 1 直接的浮点数 0.3755678429834486 >>> random.randint(5,100) # 随机任意两个整型数之间的整数 24 >>> random.randrange(4,100) # 随机从 python 可迭代对象中取值 96 >>> random.randrange(4,100,5) # 可以加步长 # 下面是从一个可迭代对象中,随机取出自定义好的几个无序的元素 >>> li = ['a',1,'b',2] >>> random.sample(li,3) # 从列表 li 中,随机选出 3 无序的个元素 ['a', 2, 'b'] >>> random.sample(li,4) # 从列表 li 中,随机选出 4 无序的个元素 [1, 2, 'b', 'a'] >>> random.sample(range(100),7) [32, 69, 25, 58, 46, 87, 85] >>>
string 模块,会返回一组 ASCII 码
>>> string.ascii_lowercase 'abcdefghijklmnopqrstuvwxyz' >>> string.ascii_uppercase 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' >>> string.ascii_letters 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' >>> string.digits '0123456789' >>>
随机验证
>>> import string,random >>> source = string.digits + string.ascii_lowercase >>> source '0123456789abcdefghijklmnopqrstuvwxyz' >>> random.sample( source , 6) ['h', 'i', 'p', 'w', '6', 'a'] >>> ''.join(random.sample( source , 6)) 'udsqrn' >>> ''.join(random.sample( source , 6)) '98lmnk' >>>
随机字符 + 数字 序列,40位
from hashlib import sha1
sha1(os.urandom(64)).hexdigest()
四、json & pickle 数据序列化 和 反序列化
Python中用于序列化的两个模块
- json 用于【字符串】和 【python基本数据类型】 间进行转换,是通用的夸语言的格式
- pickle 用于【python所有的类型】 和 【python基本数据类型】间进行转换,是 python 专用的,
并且下写入文件和读取文件时,是以字节的形式读写的
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
dumps / dump 序列化 内存中的Python所有数据类型====》pickle 类型的 字节
loads / load 反序列化 pickle 类型的 字节 ===》 内存中的Python 所有数据类型
两者的 dumps/loads 是在内存中互相转换,就是对一个对象在内存中转换为相对的对象
两者的 dump 是先把基本数据类型的对象转换为json/pickle 类型的字符或者bytes,之后再写入一个有写方法的对象
(如:文件、数据库等)
两者的 load 是先把文件或者数据库中的字符串或者pickle类型的bytes读取到内存,之后再转换为Python的基本数据类型
>>> import json,pickle
>>> li = [1,2,3]
>>> di = {'a':'b'}
>>> with open('json.db','w') as f:
... json.dump(li,f) # 一次将一个Python的基本数据类型对象转换为json类型的字符串,
... # 之后再写到文件中
>>> with open('json.db','r') as f:
... l2 = json.load(f) # 一次从文件中读一个对象到内存中,之后转换为Pyth基本数据类型
...
>>> print(l2,type(l2))
[1, 2, 3] <class 'list'>
>>>
>>> with open('json.db','w') as f:
... f.write(json.dumps(li)+'
') # 要想写多个对象到文件中,必须借助循环,之后再用dumps这种形式
... f.write(json.dumps(di)+'
') # 写进文件,保证每个对象占一行
...
10
11
>>> with open('json.db','r') as f:
... l2 = json.loads(f.readline()) # 读的时候也是要用 loads 配合readline,一次读一行
... d2 = json.loads(f.readline())
...
>>> l2
[1, 2, 3]
>>> d2
{'a': 'b'}
>>>
>>> with open('pickles.db','wb') as f: # 对于 pickle 来说,写入多个对象和读取多个对象,就简单一点儿了
... pickle.dump(li,f)
... pickle.dump(di,f)
...
>>> with open('pickle.db','rb') as f:
... l2 = pickle.load(f)
... d2 = pickle.load(f)
...
>>> l2
[1, 2, 3]
>>> d2
{'a': 'b'}
>>> 五、shelve (一次性序列化多个数据类型)
shelve模块是一个简单的,通过用k,v(即字典)的方式将内存的 Python 数据持久化到文件的模块,
可以持久化任何pickle可支持的python数据格式,底层是 pickle
>>> li = [1,'a',3]
>>> di = {'k1':'v1'}
>>> import shelve
>>> s = shelve.open('shelve_file') # 打开一个文件,命名为 shelve_file
>>> s["s_li"] = li # 开始将列表序列化到文件中,赋值给key: s_li 的值 s_li
>>> s["s_di"] = di # 继续讲字典序列化到文件中,赋值给key: s_di 的值
>>> s.close() # 记得关闭文件
>>> s = shelve.open('shelve_file') # 反序列化时,再次读取这个文件
>>> s['s_li'] # 用字典的方式得到key 的值
[1, 'a', 3]
>>> s.close()
六、time && datetime
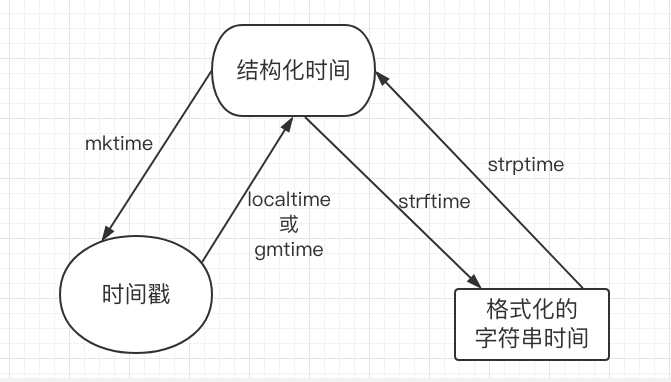
时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
>>> import time
>>> print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括s
leep时间,不稳定,mac上测不出来0.45
>>> print(time.altzone) #返回与utc时间的时间差,以秒计算
-28800
>>> print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016"
Wed Feb 22 05:33:35 2017
>>> print(time.localtime()) #返回本地时间的 struct time对象格式
time.struct_time(tm_year=2017, tm_mon=2, tm_mday=22, tm_hour=5, tm_min=33, tm_sec=54, tm_wday=2, tm_yday=53
, tm_isdst=0)>>> print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
Wed Feb 22 05:34:41 2017
# 日期字符串 转成 时间戳
>>> string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
>>> print(string_2_struct)
time.struct_time(tm_year=2016, tm_mon=5, tm_mday=22, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=143,
tm_isdst=-1)>>> struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
>>> print(struct_2_stamp)
1463846400.0
#将时间戳转为字符串格式
>>> print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
time.struct_time(tm_year=2017, tm_mon=2, tm_mday=20, tm_hour=21, tm_min=32, tm_sec=42, tm_wday=0, tm_yday=5
1, tm_isdst=0)>>> print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
2017-02-21 21:36:54
>>> print(time.strftime("%Y%m%d ",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
20170221
>>>
import datetime
>>> print(datetime.datetime.now()) # 当前时间
2017-02-22 05:23:58.194056
>>> print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
2017-02-22
>>> print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
2017-02-25 05:24:41.211896
>>> print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
2017-02-19 05:24:58.482398
>>> print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
2017-02-22 08:25:13.363732
>>> print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
2017-02-22 05:55:22.320439
>>> c_time = datetime.datetime.now()
>>> print(c_time.replace(minute=3,hour=2)) #时间替换
2017-02-22 02:03:39.511867
windows 处理 time
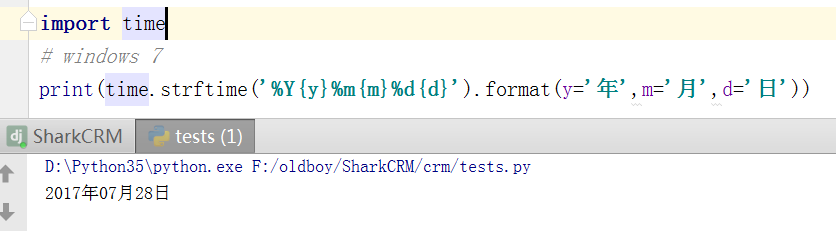
报错:
Traceback (most recent call last): File "test.py", line 6, in <module>print(nt.strftime('%Y年%m月%d日 %H时%M分%S秒')) UnicodeEncodeError: 'locale' codec can't encode character 'u5e74'in position 2 : Illegal byte sequence
原因:
在Windows里,time.strftime使用C运行时的多字节字符串函数strftime,这个函数必须先根据当前locale配置来编码格式化字符串(使用PyUnicode_EncodeLocale)。
如果不设置好locale的话,根据默认的"C" locale,底层的wcstombs函数会使用latin-1编码(单字节编码)来编码格式化字符串,然后导致我们提供的多字节编码的字符串在编码时出错。
解决办法:
既然直接丢中文字符进去会出错,那么就绕过这个问题,丢(可能)永远不会出错的ascii字符进去充当占位符,格式化完毕后再将占位符换回中文字符。
七、 shutil (强大的文件、文件夹压缩打包)
shutil 是 Python中 高级的文件 文件夹 压缩包 处理模块
拷贝文件内容到另一个文件对象中
>>> import shutil
# 先写一些内容到一个文件中
>>> with open('old.file','w',encoding='utf-8') as of:
... of.write('I am a old file')
...
15
# 把一个文件对象的内容复制到新文件对象文件里,这里两个参数都是对象,不是文件名
>>> shutil.copyfileobj(open('old.file','r',encoding='utf-8'),open('new.file','w',encoding='utf-8') )
>>> with open('new.file','r',encoding='utf-8') as nf:
... print(nf.read())
...
I am a old file
>>>
拷贝文件内容到另一个文件中,参数是文件名
>>> shutil.copyfile('old.file','new2.file')
'new2.file'
>>> with open('new2.file','r') as nf:
... print(nf.read())
...
I am a old file
>>>
只拷贝源文件的权限信息,不包括文件的内容和所属主、所属组
>>> shutil.copymode('src.file','dst.file')仅拷贝文件的状态信息,包括,权限 ,atime,mtime, 不包括用户和组以及 修改内容的时间
shutil.copystat('src.log', 'dst.log')shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
>>> shutil.copytree('/home','/tmp/hbak',ignore=shutil.ignore_patterns('*.file'))
# 递归拷贝一个文件夹下的所以内容到另一个文件下,目标文件夹应该是原来系统中不存在的文件夹# ignore=shutil.ignore_patterns('排除的文件名','排除的文件夹名') 支持通配符
递归删除一个文件夹下的所有内容
>>> shutil.rmtree('/tmp/hb')
>>> shutil.rmtree('/tmp/hbad/')
# 最后结尾的一定是明确的文件名,不可以下向下面这样
>>> shutil.rmtree('/tmp/hbak/*')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/shutil.py", line 465, in rmtree
onerror(os.lstat, path, sys.exc_info())
File "/usr/local/lib/python3.6/shutil.py", line 463, in rmtree
orig_st = os.lstat(path)
FileNotFoundError: [Errno 2] No such file or directory: '/tmp/hbak/*'shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
>>> shutil.move('/home/src.file','./shark')
'./shark/src.file'
>>>
# 源文件名,不支持任意模式的模糊匹配shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/shark/www =>保存至/Users/shark/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
# 将 /home/shark 目录下的所以文件打包压缩到当前目录下,名字shark,格式 gztar >>> shutil.make_archive( 'shark','gztar','/home/shark') '/home/shark.tar.gz' # 将 /home/shark 目录下的所以文件打包压缩到 /tmp 目录下,名字shark,格式 tar >>> shutil.make_archive( '/tmp/shark','tar','/home/shark') '/tmp/shark.tar'
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
ZipFile
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall()
z.close()TarFile
import tarfile
# 压缩
tar = tarfile.open('your.tar','w')
tar.add('/Users/shark/PycharmProjects/bbs2.log', arcname='bbs2.log')
tar.add('/Users/shark/PycharmProjects/cmdb.log', arcname='cmdb.log')
tar.close()
# 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()八、 xml处理
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
示例文档
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
 #只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')自己创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式安全提示
假如有个XML片段,定义了10个嵌套实体,每一项扩展10倍的子项,总共就会有10亿的扩展项
糟糕的是,前面前面提到的XML库无法容纳10亿多的项。
Defused XML (https://bitbucket.org/tiran/defusedxml)列出了这种攻击和Python库中的其他缺点,并且指出了如何修改
设置避免这些问题,或者使用 defusedxml 库作为安全的保护:
>>> # 不安全的 >>> from xml.etree.ElementTree import parse >>> et = parse(xmlfile) NameError: name 'xmlfile' is not defined >>> # 受保护的,当然这个是第三方模块,需要你自行安装后才行 >>> from defusedxml.ElementTree import parse
九、 yaml处理
和 json 类似,YAML(http://www.yaml.org)同样有键和值,但主要用于处理日期和时间这样的数据类型。这个也是属于第三方模块,需要自行安装(http://pyyaml.org/wiki/PyYAML)。
load() 将YAML 字符串转为Python的数据类型,而domp()则正好相反。
下面YAML示例文件包含加拿大诗人 James McIntyre 的两首诗:
name:
first: James
last: McIntyre
dates:
birth:1828-0525
death:1986-03-31
details:
bearded:true
themes:[cheese,Canada]
books:
url:http://www.gutenberg.org/files/36068/36068-h/36068-h.htm
poems:
- title:'Motto'
text:|
Politemes,perseverance and pluck,
- title:'Canadian Charms'
text:|
Here industry is not in vain, 类似于 true 、false、on 和 off 的值可以转换为 Python 的布尔值。
整数和字符串转换为 Python等价的。其他语法创建为列表和字典:
>>> import yaml
>>> with open('example.yaml','r') as yf:
... text = yf.read()
...
>>> data = yaml.load(text)
>>> data['datails']
{'themes': ['cheese', 'Canada'], 'bearded': True}
>>> len(data['poems'])
2
>>>创建的 匹配这个 YAML 文件的数据结构超过了一层嵌套。如果想得到第二首诗歌的题目,要使用
dict/list/dict 的方式:
>>> data['popens'][1]['title'] 'Canadian Charms'
十、 configparser (配置文件)
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
来看一个好多软件的常见文档格式如下
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)写完了还可以再读出来哈。
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
'50022'
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'configparser增删改查语法
[section1]
k1 = v1
k2:v2
[section2]
k1 = v1
import ConfigParser
config = ConfigParser.ConfigParser()
config.read('i.cfg')
# ########## 读 ##########
#secs = config.sections()
#print secs
#options = config.options('group2')
#print options
#item_list = config.items('group2')
#print item_list
#val = config.get('group1','key')
#val = config.getint('group1','key')
# ########## 改写 ##########
#sec = config.remove_section('group1')
#config.write(open('i.cfg', "w"))
#sec = config.has_section('shark')
#sec = config.add_section('shark')
#config.write(open('i.cfg', "w"))
#config.set('group2','k1',11111)
#config.write(open('i.cfg', "w"))
#config.remove_option('group2','age')
#config.write(open('i.cfg', "w"))十一、 hashlib (加密)
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...")
print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
'''
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac h = hmac.new(b'天王盖地虎', b'宝塔镇河妖') print h.hexdigest()
十二、subprocess
常用subprocess方法示例
#执行命令,返回命令执行状态 , 0 or 非0
>>> retcode = subprocess.call(["ls", "-l"])#执行命令,如果命令结果为0,就正常返回,否则抛异常
>>> subprocess.check_call(["ls", "-l"])
0#接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
>>> subprocess.getstatusoutput('ls /bin/ls')
(0, '/bin/ls')#接收字符串格式命令,并返回结果
>>> subprocess.getoutput('ls /bin/ls')
'/bin/ls'#执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
>>> res=subprocess.check_output(['ls','-l'])
>>> res
b'total 0 drwxr-xr-x 12 shark staff 408 Nov 2 11:05 OldBoyCRM '#上面那些方法,底层都是封装的subprocess.Popen
poll()
Check if child process has terminated. Returns returncodewait()
Wait for child process to terminate. Returns returncode attribute.terminate() 杀掉所启动进程
communicate() 等待任务结束stdin 标准输入
stdout 标准输出
stderr 标准错误pid
The process ID of the child process.#例子
>>> p = subprocess.Popen("df -h|grep disk",stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
>>> p.stdout.read()
b'/dev/disk1 465Gi 64Gi 400Gi 14% 16901472 104938142 14% / '
>>> subprocess.run(["ls", "-l"]) # doesn't capture output
CompletedProcess(args=['ls', '-l'], returncode=0)
>>> subprocess.run("exit 1", shell=True, check=True)
Traceback (most recent call last):
...
subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1
>>> subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE)
CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0,
stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null
')调用subprocess.run(...)是推荐的常用方法,在大多数情况下能满足需求,但如果你可能需要进行一些复杂的与系统的交互的话,你还可以用subprocess.Popen(),语法如下:
p = subprocess.Popen("find / -size +1000000 -exec ls -shl {} ;",shell=True,stdout=subprocess.PIPE)
print(p.stdout.read())可用参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
需要交互的命令示例
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write('print 1
')
obj.stdin.write('print 2
')
obj.stdin.write('print 3
')
obj.stdin.write('print 4
')
out_error_list = obj.communicate(timeout=10)
print out_error_listsubprocess实现sudo 自动输入密码
import subprocess
def mypass():
mypass = '123' #or get the password from anywhere
return mypass
echo = subprocess.Popen(['echo',mypass()],
stdout=subprocess.PIPE,
)
sudo = subprocess.Popen(['sudo','-S','iptables','-L'],
stdin=echo.stdout,
stdout=subprocess.PIPE,
)
end_of_pipe = sudo.stdout
print "Password ok
Iptables Chains %s" % end_of_pipe.read()十三、logging 模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,
python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,
logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,
import logging
logging.warning("user [shark] attempted wrong password more than 3 times")
logging.critical("server is down")
#输出
WARNING:root:user [shark] attempted wrong password more than 3 times
CRITICAL:root:server is down看一下这几个日志级别分别代表什么意思
Level | When it’s used |
| Detailed information, typically of interest only when diagnosing problems. |
| Confirmation that things are working as expected. |
| An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
| Due to a more serious problem, the software has not been able to perform some function. |
| A serious error, indicating that the program itself may be unable to continue running. |
如果想把日志写到文件里,也很简单
import logging
logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,
只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,
如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.')
#输出
12/12/2010 11:46:36 AM is when this event was logged.日志格式说明
%(name)s | Logger的名字 |
%(levelno)s | 数字形式的日志级别 |
%(levelname)s | 文本形式的日志级别 |
%(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 |
%(filename)s | 调用日志输出函数的模块的文件名 |
%(module)s | 调用日志输出函数的模块名 |
%(funcName)s | 调用日志输出函数的函数名 |
%(lineno)d | 调用日志输出函数的语句所在的代码行 |
%(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 |
%(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数 |
%(asctime)s | 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
%(thread)d | 线程ID。可能没有 |
%(threadName)s | 线程名。可能没有 |
%(process)d | 进程ID。可能没有 |
%(message)s | 用户输出的消息 |
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
- Logger 记录器,暴露了应用程序代码能直接使用的接口。
- Handler 处理器,将(记录器产生的)日志记录发送至合适的目的地。
- Filter 过滤器,提供了更好的粒度控制,它可以决定输出哪些日志记录。
- Formatter 格式化器,指明了最终输出中日志记录的布局。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
以下是相关概念总结:
熟悉了这些概念之后,有另外一个比较重要的事情必须清楚,即Logger是一个树形层级结构;
Logger可以包含一个或多个Handler和Filter,即Logger与Handler或Fitler是一对多的关系;
一个Logger实例可以新增多个Handler,一个Handler可以新增多个格式化器或多个过滤器,而且日志级别将会继承。

显式配置
import logging
#create logger
logger = logging.getLogger('TEST-LOG')
logger.setLevel(logging.DEBUG)
# create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# create file handler and set level to warning
fh = logging.FileHandler("access.log")
fh.setLevel(logging.WARNING)
# create formatter
fmt = "%(asctime)-15s %(levelname)s %(filename)s %(lineno)d %(process)d %(message)s"
datefmt = "%a %d %b %Y %H:%M:%S"
formatter = logging.Formatter(fmt, datefmt)
# add formatter to ch and fh
ch.setFormatter(formatter)
fh.setFormatter(formatter)
# add ch and fh to logger
logger.addHandler(ch)
logger.addHandler(fh)
# 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')文件配置
配置文件logging.conf如下:
keys=root,example01
[logger_root]
level=DEBUG
handlers=hand01,hand02
[logger_example01]
handlers=hand01,hand02
qualname=example01
propagate=0
[handlers]
keys=hand01,hand02
[handler_hand01]
class=StreamHandler
level=INFO
formatter=form02
args=(sys.stderr,)
[handler_hand02]
class=FileHandler
level=DEBUG
formatter=form01
args=('log.log', 'a')
[formatters]
keys=form01,form02
[formatter_form01]
format=%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s使用程序logger.py如下:
# -*- encoding:utf-8 -*-
import logging
import logging.config
logging.config.fileConfig("./logging.conf")
# create logger
logger_name = "example"
logger = logging.getLogger(logger_name)
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')日志切割例子
import logging
from logging import handlers
logger = logging.getLogger(__name__)
log_file = "timelog.log"
#fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3)
fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3)
formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
logger.warning("test1")
logger.warning("test12")
logger.warning("test13")
logger.warning("test14")十四、re 模块(正则)
常用正则表达式符号
'.' 默认匹配除
之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","
abc
eee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo
sdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符连续出现m次
'{n,m}' 匹配前一个字符连续出现n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'A' 只从字符开头匹配,re.search("Aabc","sharkabc") 是匹配不到的
'' 匹配字符结尾,同$
'd' 匹配数字0-9
'D' 匹配非数字
'w' 匹配[A-Za-z0-9]和下划线 _
'W' 匹配非[A-Za-z0-9]和非下划线 _ ,就是任意的特殊字符(符号)
's' 匹配空白字符、 、
、
, re.search("s+","ab c1
3").group() 结果 ' '
'(?P<name>...)' 分组匹配
>>> re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupd
ict("city")
#输出结果
{'province': '3714', 'city': '81', 'birthday': '1993'}
>>>
最常用的匹配语法
re.match 从头开始匹配,成功匹配到第一个,则返回;否则未匹配到返回 None
re.search 浏览整个字符串,成功匹配到第一个,则返回,否则未匹配到返回 None re.findall 把所有匹配到的字符放到以列表中的元素返回 re.splitall 以匹配到的字符当做列表分隔符,规则相同的话,得到的结果和 findall 正好相反 re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图) S(DOTALL): 点任意匹配模式,改变'.'的行为
联系作业
开发一个简单的python计算器
- 实现加减乘除及拓号优先级解析
- 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式(不能调用eval等类似功能偷懒实现),运算后得出结果,结果必须与真实的计算器所得出的结果一致
十五、第三方模块 paramiko
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内
部的远程管理就是使用的paramiko来现实。
1、下载安装
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto
pip3 install pycrypto
pip3 install paramiko2、模块使用


#!/usr/bin/env python#coding:utf-8 importparamiko ssh =paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.1.108', 22, 'alex', '123') stdin, stdout, stderr = ssh.exec_command('df') printstdout.read() ssh.close();
importparamiko private_key_path = '/home/auto/.ssh/id_rsa'key =paramiko.RSAKey.from_private_key_file(private_key_path) ssh =paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('主机名 ', 端口, '用户名', key) stdin, stdout, stderr = ssh.exec_command('df') printstdout.read() ssh.close()
importparamiko t = paramiko.Transport(('172.16.153.141',22)) t.connect(username='shark',password='123') sftp =paramiko.SFTPClient.from_transport(t) #上传 sftp.put('/tmp/test.py','/tmp/test.py') #下载 sftp.get('/tmp/test.py','/tmp/test1.py') t.close()
import paramiko
pravie_key_path = '/home/shark/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(pravie_key_path)
t = paramiko.Transport(('172.16.153.151',22))
t.connect(username='shark',pkey=key)
sftp = paramiko.SFTPClient.from_transport(t)
# 上传
sftp.put('/tmp/test.py','/tmp/test2.py')
# 下载
sftp.get('/tmp/test2.py','/tmp/test3.py')
t.close()
setdefault() 和 defaultdict()处理缺失的键
使用counter()计数
使用有序字典 OrderedDict按键排序
双端序列:栈和队列
使用 itertools 迭代代码结构
使用 pprint()友好输出