摘要:
一般来说,子数据库和子表是跨数据库和子表格。上述想法是通过合理的数据分布避免跨数据库相关查询。事实上,我们也尽量不在业务中使用与跨数据库相关的查询。如果发生这种情况,我们应该分析业务或数据拆分是否合理。
从维度来说分成两种,一种是垂直,一种是水平。垂直切分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。水平切分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的切分。

1.1 垂直切分
垂直分表有两种,一种是单库的,一种是多库的。
- 1.1.1 单库垂直分表
单库分表,比如:商户信息表,拆分成基本信息表,联系方式表,结算信息表,附件表等等。
- 1.1.2 多库垂直分表
多库垂直分表就是把原来存储在一个库的不同的表,拆分到不同的数据库。
比如:消费金融核心系统数据库,有很多客户相关的表,这些客户相关的表,全部单独存放到客户的数据库里面。合同,放款,风控相关的业务表也是一样的。
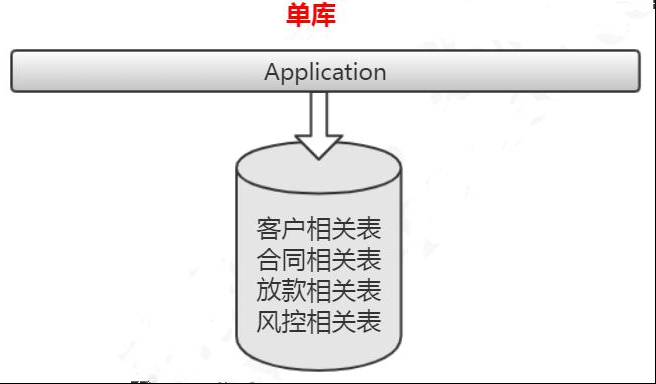
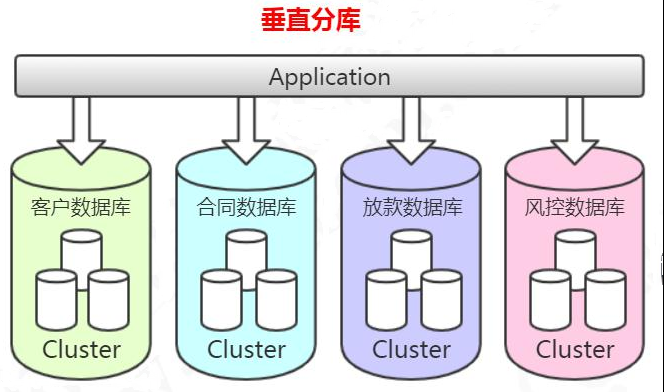
当我们对原来的一张表做了分库的处理,如果某些业务系统的数据还是有一个非常快的增长速度,比如说还款数据库的还款历史表,数据量达到了几个亿,这个时候硬件限制导致的性能问题还是会出现,所以从这个角度来说垂直切分并没有从根本上解决单库单表数据量过大的问题。在这个时候,我们还需要对我们的数据做一个水平的切分。
1.2 水平切分
当我们的客户表数量已经到达数千万甚至上亿的时候,单表的存储容量和查询效率都会出现问题,我们需要进一步对单张表的数据进行水平切分。水平切分的每个数据库的表结构都是一样的,只是存储的数据不一样,比如每个库存储 1000 万的数据。水平切分也可以分成两种,一种是单库的,一种是多库的。
- 1.2.1 单库水平分表
银行的交易流水表,所有进出的交易都需要登记这张表,因为绝大部分时候客户都是查询当天的交易和一个月以内的交易数据,所以我们根据使用频率把这张表拆分成三张表:当天表:只存储当天的数据。当月表:在夜间运行一个定时任务,前一天的数据,全部迁移到当月表。用的是 insert into select,然后 delete。
历史表:同样是通过定时任务,把登记时间超过 30 天的数据,迁移到 history历史表(历史表的数据非常大,我们按照月度,每个月建立分区)。
费用表:消费金融公司跟线下商户合作,给客户办理了贷款以后,消费金融公司要给商户返费用,或者叫提成,每天都会产生很多的费用的数据。为了方便管理,我们每个月建立一张费用表,例如 fee_detail_201901……fee_detail_201912。
但是注意,跟分区一样,这种方式虽然可以一定程度解决单表查询性能的问题,但是并不能解决单机存储瓶颈的问题。
- 1.2.2 多库水平分表
另一种是多库的水平分表。比如客户表,我们拆分到多个库存储,表结构是完全一样的。

一般我们说的分库分表都是跨库的分表。既然分库分表能够帮助我们解决性能的问题,那我们是不是马上动手去做,甚至在项目设计的时候就先给它分几个库呢?先冷静一下,我们来看一下分库分表会带来哪些问题,也就是我们前面说的分库分表之后带来的复杂性。
1.3 多案分库分表带来的问题
- 1.3.1 跨库关联查询
比如查询在合同信息的时候要关联客户数据,由于是合同数据和客户数据是在不同的数据库,那么我们肯定不能直接使用 join 的这种方式去做关联查询。我们有几种主要的解决方案:
1、字段冗余
比如我们查询合同库的合同表的时候需要关联客户库的客户表,我们可以直接把一些经常关联查询的客户字段放到合同表,通过这种方式避免跨库关联查询的问题。
2、数据同步
比如商户系统要查询产品系统的产品表,我们干脆在商户系统创建一张产品表,通过 ETL 或者其他方式定时同步产品数据。
3、全局表(广播表)
比如行名行号信息被很多业务系统用到,如果我们放在核心系统,每个系统都要去关联查询,这个时候我们可以在所有的数据库都存储相同的基础数据。
4、ER 表(绑定表)
我们有些表的数据是存在逻辑的主外键关系的,比如订单表 order_info,存的是汇总的商品数,商品金额;订单明细表 order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。所以我们能不能把父表和数据和从属于父表的数据落到一个节点上呢?
比如 order_id=1001 的数据在 node1,它所有的明细数据也放到 node1;order_id=1002 的数据在 node2,它所有的明细数据都放到 node2,这样在关联查询的时候依然是在一个数据库。上面的思路都是通过合理的数据分布避免跨库关联查询,实际上在我们的业务中,也是尽量不要用跨库关联查询,如果出现了这种情况,就要分析一下业务或者数据拆分是不是合理。如果还是出现了需要跨库关联的情况,那我们就只能用最后一种办法。
5、系统层组装
在不同的数据库节点把符合条件数据的数据查询出来,然后重新组装,返回给客户端。
- 1.3.2 分布式事务
这个我会在分布式里讲解,目前暂且不提。
- 1.3.3 排序、翻页、函数计算问题
跨节点多库进行查询时,会出现 limit 分页,order by 排序的问题。比如有两个节点,节点 1 存的是奇数 id=1,3,5,7,9……;节点 2 存的是偶数 id=2,4,6,8,10……
执行 select * from user_info order by id limit 0,10需要在两个节点上各取出 10 条,然后合并数据,重新排序。
max、min、sum、count 之类的函数在进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。
- 1.3.4 全局主键避重问题
MySQL 的数据库里面字段有一个自增的属性,Oracle 也有 Sequence 序列。如果是一个数据库,那么可以保证 ID 是不重复的,但是水平分表以后,每个表都按照自己的

规律自增,肯定会出现 ID 重复的问题,这个时候我们就不能用本地自增的方式了。
我们有几种常见的解决方案:
1)UUID(Universally Unique Identifier 通用唯一识别码)
UUID 标准形式包含 32 个 16 进制数字,分为 5 段,形式为 8-4-4-4-12 的 36 个字符,例如:c4e7956c-03e7-472c-8909-d733803e79a9。
Name | Length (Bytes) | Length (Hex Digits) | Contents |
time_low | 4 | 8 | integer giving the low 32 bits of the time |
time_mid | 2 | 4 | integer giving the middle 16 bits of the time |
time_hi_and_version | 2 | 4 | 4-bit "version" in the most significant bits, followed by the high 12 bits of the time |
clock_seq_hi_and_res clock_seq_low | 2 | 4 | 1-3 bit "variant" in the most significant bits, followed by the 13-15 bit clock sequence |
node | 6 | 12 | the 48-bit node id |
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
M 表示 UUID 版本,目前只有五个版本,即只会出现 1,2,3,4,5,数字 N 的一至三个最高有效位表示 UUID 变体,目前只会出现 8,9,a,b 四种情况。
- 1、基于时间和 MAC 地址的 UUID
- 2、基于第一版却更安全的 DCE UUID
- 3、基于 MD5 散列算法的 UUID
- 4、基于随机数的 UUID——用的最多,JDK 里面是 4
- 5、基于 SHA1 散列算法的 UUID
UUID 是主键是最简单的方案,本地生成,性能高,没有网络耗时。但缺点也很明显,由于 UUID 非常长,会占用大量的存储空间;另外,作为主键建立索引和基于索引进行查询时都会存在性能问题,在 InnoDB 中,UUID 的无序性会引起数据位置频繁变动,导致分页。
2) 数据库
把序号维护在数据库的一张表中。这张表记录了全局主键的类型、位数、起始值,当前值。当其他应用需要获得全局 ID 时,先 for update 锁行,取到值+1 后并且更新后返回。并发性比较差。
3)Redis
基于 Redis 的 INT 自增的特性,使用批量的方式降低数据库的写压力,每次获取一段区间的 ID 号段,用完之后再去数据库获取,可以大大减轻数据库的压力。
4)雪花算法 Snowflake(64bit)
核心思想:
- a)使用 41bit 作为毫秒数,可以使用 69 年
- b)10bit 作为机器的 ID(5bit 是数据中心,5bit 的机器 ID),支持 1024 个节点
- c)12bit 作为毫秒内的流水号(每个节点在每毫秒可以产生 4096 个 ID)
- d)最后还有一个符号位,永远是 0。
代码:snowflake.SnowFlakeTest
优点:毫秒数在高位,生成的 ID 整体上按时间趋势递增;不依赖第三方系统,稳定性和效率较高,理论上 QPS 约为 409.6w/s(1000*2^12),并且整个分布式系统内不会产生 ID 碰撞;可根据自身业务灵活分配 bit 位。
不足就在于:强依赖机器时钟,如果时钟回拨,则可能导致生成 ID 重复。
当我们对数据做了切分,分布在不同的节点上存储的时候,是不是意味着会产生多个数据源?既然有了多个数据源,那么在我们的项目里面就要配置多个数据源。现在问题就来了,我们在执行一条 SQL 语句的时候,比如插入,它应该是在哪个数据节点上面执行呢?又比如查询,如果只在其中的一个节点上面,我怎么知道在哪个节点,是不是要在所有的数据库节点里面都查询一遍,才能拿到结果?那么,从客户端到服务端,我们可以在哪些层面解决这些问题呢?
1.4 多数据源/读写数据源的解决方案
我们先要分析一下 SQL 执行经过的流程。
DAO——Mapper(ORM)——JDBC——代理——数据库服务
- 1.4.1 客户端 DAO 层
第一个就是在我们的客户端的代码,比如 DAO 层,在我们连接到某一个数据源之前,我们先根据配置的分片规则,判断需要连接到哪些节点,再建立连接。
Spring 中提供了一个抽象类 AbstractRoutingDataSource,可以实现数据源的动态切换。
SSM 工程:spring-boot-dynamic-data-source-master
步骤:
- 1)aplication.properties 定义多个数据源;
- 2)创建@TargetDataSource 注解;
- 3)创建 DynamicDataSource 继承 AbstractRoutingDataSource;
- 4)多数据源配置类 DynamicDataSourceConfig;
- 5)创建切面类 DataSourceAspect,对添加了@TargetDataSource 注解的类进行拦截设置数据源;
- 6)在启动类上自动装配数据源配置@Import({DynamicDataSourceConfig.class})
- 7)在 实 现 类 上 加 上 注 解 , 如 @TargetDataSource(name =DataSourceNames.SECOND),调用在 DAO 层实现的优势:不需要依赖 ORM 框架,即使替换了 ORM 框架也不受影响。实现简单(不需要解析 SQL 和路由规则),可以灵活地定制。
缺点:不能复用,不能跨语言。
- 1.4.2 ORM 框架层
第二个是在框架层,比如我们用 MyBatis 连接数据库,也可以指定数据源。我们可以基于 MyBatis 插件的拦截机制(拦截 query 和 update 方法),实现数据源的选择。
- 1.4.3 驱动层
不管是MyBatis还是Hibernate,还是Spring的JdbcTemplate,本质上都是对JDBC的封装,所以第三层就是驱动层。比如 Sharding-JDBC,就是对 JDBC 的对象进行了封装。JDBC 的核心对象:
- DataSource:数据源
- Connection:数据库连接
- Statement:语句对象
- ResultSet:结果集
那我们只要对这几个对象进行封装或者拦截或者代理,就可以实现分片的操作。
- 1.4.4 代理层
前面三种都是在客户端实现的,也就是说不同的项目都要做同样的改动,不同的编程语言也有不同的实现,所以我们能不能把这种选择数据源和实现路由的逻辑提取出来,做成一个公共的服务给所有的客户端使用呢?这个就是第四层,代理层。比如 Mycat 和 Sharding-Proxy,都是属于这一层。
- 1.4.5 数据库服务
最后一层就是在数据库服务上实现,也就是服务层,某些特定的数据库或者数据库的特定版本可以实现这个功能。