摘要:
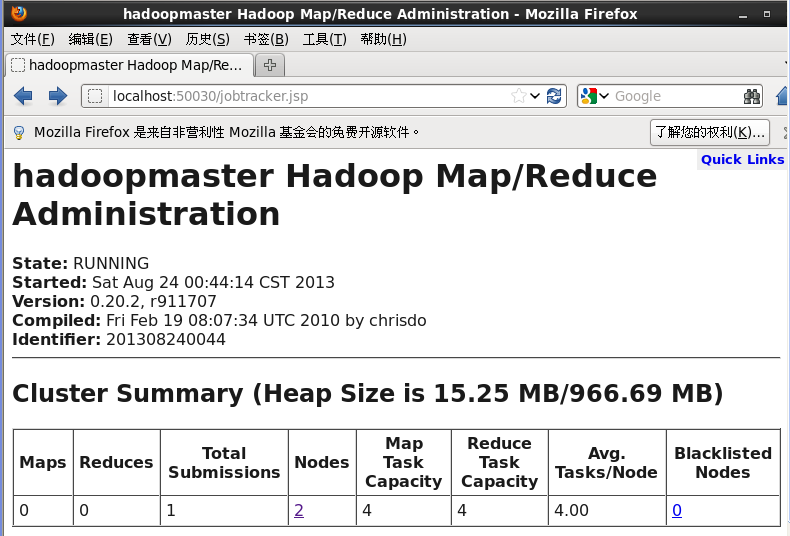
2.要查看任务跟踪jobtracker,可以在浏览器中输入localhost:50030进行任务跟踪
1、查看当前的文件系统
[root@hadoopmaster bin]# ./hadoop fs -ls /
Found 2 items
drwxr-xr-x- root supergroup02013-08-24 00:47/tmp
drwxr-xr-x- root supergroup02013-08-24 00:44/user
Found 2 items
drwxr-xr-x- root supergroup02013-08-24 00:47/tmp
drwxr-xr-x- root supergroup02013-08-24 00:44/user
当然也可以以浏览器中这样查看localhost:50070
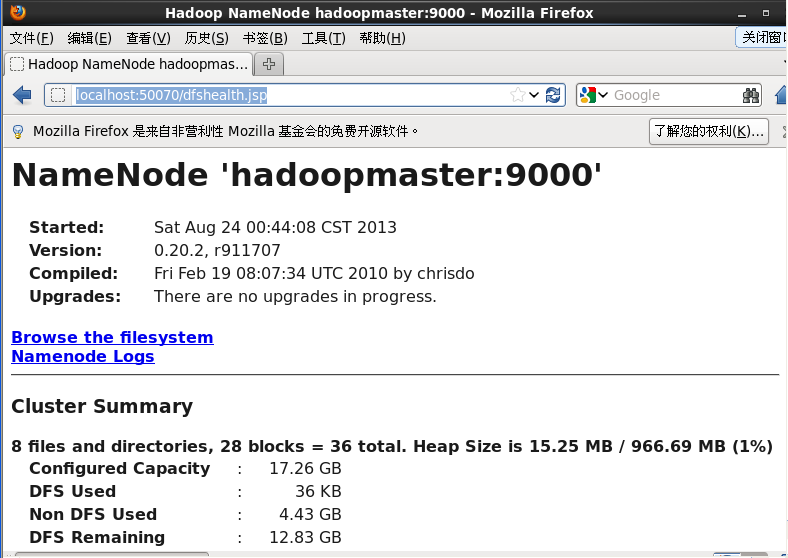
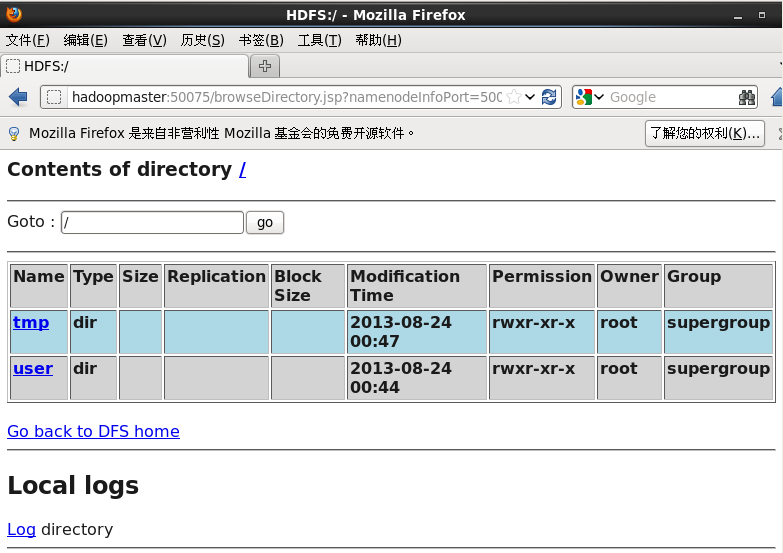
这就是hadoop中的分布式文件系统,即为hdfs,这里我说明了两种查看方式。2、查看任务跟踪jobtracker,即为任务跟踪可以在浏览器中输入localhost:50030