LINUX用缓冲的地方遍地可见,不管是硬件、内核还是应用程序,内核里有页高速缓冲,内存高速缓冲,硬件更不用说的L1,L2 cache,应用程序更是多的数不清,基本写的好的软件都有。但归根结底这些缓冲的作用是相同的,都是为了提高机器或者程序的性能。而需要缓冲大部分的情况都是为了协调两个设备或者两个系统间速度的不匹配。
大家都知道IO设备的访问速度与CPU的速度相差好几个数量级,所以为了协调IO设备与CPU的速度的不匹配,对于块设备内核使用了页高速缓存。也就是说,数据会先被拷贝到操作系统内核的页缓存区中,然后才会从操作系统内核的缓存区拷贝到应用程序的地址空间。
当应用程序尝试读取某块数据的时候,如果这块数据已经存放在页缓存中,那么这块数据就可以立即返回给应用程序,而不需要经过实际的物理读盘操作。当然,如果数据在应用程序读取之前并未被存放在页缓存中,那么就需要先将数据从磁盘读到页缓存中去。对于写操作来说,应用程序也会将数据先写到页缓存中去,数据是否被立即写到磁盘上去取决于应用程序所采用的写操作机制:如果用户采用的是同步写机制,那么数据会立即被写回到磁盘上,应用程序会一直等到数据被写完为止;如果用户采用的是延迟写机制,那么应用程序就完全不需要等到数据全部被 写回到磁盘,数据只要被写到页缓存中去就可以了。在延迟写机制的情况下,操作系统会定期地将放在页缓存中的数据刷到磁盘上。与异步写机制不同的是,延迟写机制在数据完全写到磁盘上得时候不会通知应用程序,而异步写机制在数据完全写到磁盘上得时候是会返回给应用程序的。所以延迟写机制本省是存在数据丢失的风险的,而异步写机制则不会有这方面的担心。
在应用程序中,我们经常也使用缓存来解决IO设备与CPU速度的不匹配,如下面的read和write函数:
1 ssize_t read(int filedes, void *buf, size_t nbytes); 2 ssize_t write(int filedes, const void *buf, size_t nbytes);
我们调用read函数从文件读取数据或者调用write来写数据到文件中,一般都是一次性的写多个数据,很少一次写一个byte的数据(除了一些特殊的场景)。所以上面传递给read和write的buf参数其实就是我们的缓冲,这个缓冲的大小都是我们在写程序的时候自己定义的。但问题就来了,我们应该定义多大的缓冲大小才能使IO性能达到最大呢?对于一些不了解内核或者文件系统的人来说是很难知道这个大小的,下面是apue作者自己测试的不同缓冲大小对IO性能的影响的数据:
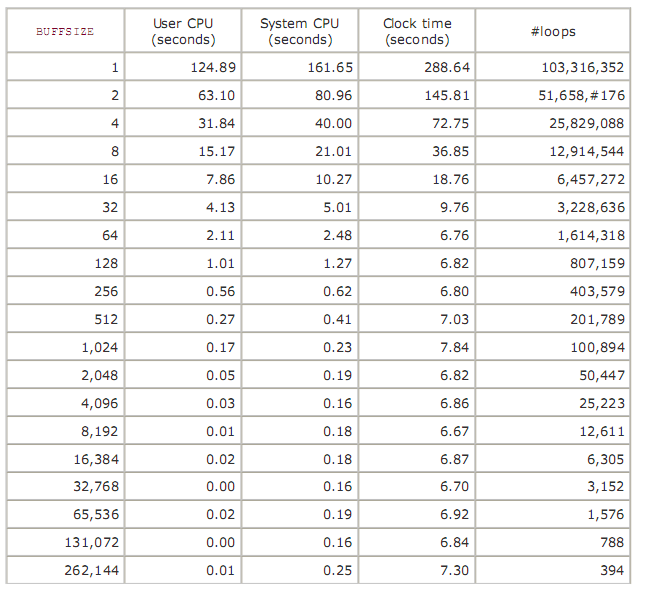
从上图可以知道当缓冲达到4096大小的时候,继续增加缓冲大小对IO性能影响不大。这个4096大小由文件系统的块大小决定,由于上面的测试所用的文件系统是Linux ext2,块大小是4096。
标准IO库则很好的解决了设置缓冲大小的问题,标准IO会选择最佳的缓存大小,使得我们不用再关心设置缓存大小的问题,事实上标准IO库会对每个IO流自动进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。不过使用标准IO库最大的问题也是它的缓冲,使用的不好很容易出现莫名其妙的结果。
标准IO提供的三种类型的缓冲全缓冲
在填满标准IO缓冲区后才进行实际的IO操作。对于在磁盘上的文件通常由标准IO库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓存区。
行缓冲
当在输入和输出中遇到换行符时,标准IO库执行IO操作。这允许我们一次输出一个字符(用标准IO函数fputc),但只有在写了一行之后才进行实际IO操作。通常涉及到终端(例如标准输入和标准输出)使用的是行缓冲。
对于行缓冲有两个限制。第一,因为标准IO库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行IO操作。第二,任何时候只要通过标准IO库要求从(a)一个不带缓存的流,或者(b)一个行缓存的流(它要求从内核得到数据)得到输入数据,那么就会造成冲洗所有行缓冲输出流(因为后面读取的数据可能就是前面输出的数据)。其实第二种情况我们会经常遇到,当我们先调用printf输出一串不带换行符的字符时,执行完这条printf语句并不会立刻在屏幕中显示我们输出的数据,当我们接下来调用scanf从标准输入读取数据时,我们才看到前面输出的数据。
不带缓冲
标准IO库不对字符进行存储。例如,如果用标准IO函数fputs写15个字符到不带缓冲的流中,则该函数很可能直接调用write系统调用将这些字符立即写到相关的文件中。标准出错流stderr是不带缓冲的,这样为了让出错的信息可以尽快的显示出来。
修改默认IO缓冲对于上面提到的每种文件流,IO库都默认分配一个对应的缓冲给它,但有时候我们想自己设置这些缓冲,不要默认的,那么我们可以使用下面两个函数来达到目的:
1 void setbuf(FILE *restrict fp, char *restrict buf); 2 void setvbuf(FILE *restrict fp, char *restrict buf, int mode, size_t size);
第一个函数用来打开或者关闭缓冲机制,如果buf为NULL,则关闭缓冲,否则buf指向缓冲区,不过缓冲区的类型和文件流有关。第二个函数可以精确的指定我们所需要的缓冲类型,如下图所示。

下面我们编写一个小的程序来获得标准IO默认缓冲的大小,代码如下:
1 #include <stdio.h> 2 3 int stream_attribute(FILE *fp) 4 { 5 if(fp->_flags & _IO_UNBUFFERED) 6 { 7 printf("The IO type is unbuffered "); 8 }else if(fp->_flags & _IO_LINE_BUF){ 9 printf("The IO type is line buf "); 10 }else{ 11 printf("The IO type is full buf "); 12 } 13 printf("The IO size : %d ",fp->_IO_buf_end - fp->_IO_buf_base); 14 return 0; 15 } 16 int main() 17 { 18 FILE *fp; 19 stream_attribute(stdin); 20 printf("___________________________________ "); 21 stream_attribute(stdout); 22 printf("___________________________________ "); 23 stream_attribute(stderr); 24 printf("___________________________________ "); 25 if((fp = fopen("test","w+")) == NULL) 26 perror("fail to fopen"); 27 stream_attribute(fp); 28 return 0; 29 }
在ubuntu下运行结果为:
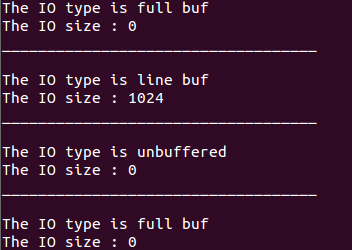
下面修改下代码,从键盘读入一串字符并写入到test文件中,代码如下:
1 #include <stdio.h> 2 3 int stream_attribute(FILE *fp) 4 { 5 if(fp->_flags & _IO_UNBUFFERED) 6 { 7 printf("The IO type is unbuffered "); 8 }else if(fp->_flags & _IO_LINE_BUF){ 9 printf("The IO type is line buf "); 10 }else{ 11 printf("The IO type is full buf "); 12 } 13 printf("The IO size : %d ",fp->_IO_buf_end - fp->_IO_buf_base); 14 return 0; 15 } 16 int main() 17 { 18 FILE *fp; 19 char buf[20]; 20 21 printf("input a string(<20):"); 22 scanf("%s", buf); 23 stream_attribute(stdin); 24 printf("___________________________________ "); 25 stream_attribute(stdout); 26 fprintf(stderr, "___________________________________ "); 27 stream_attribute(stderr); 28 printf("___________________________________ "); 29 if((fp = fopen("test.txt","w+")) == NULL) 30 perror("fail to fopen"); 31 fputs(buf, fp); 32 stream_attribute(fp); 33 return 0; 34 }
运行结果如下:
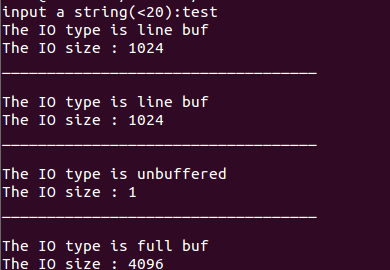
从上面的运行结果可以看出标准IO库对流的缓冲不是在一开始就分配的,只有对流进行了输入或者输出才会实际的分配。在linux下,行缓冲的默认大小是1K,全缓冲的大小默认是4K,无缓冲的默认大小是1字节。
参考《APUE》