本文是学习总结的笔记,仅供个人学习使用。
1. introduction
在这篇文章中,作者训练了一个端到端的卷积网络,以从连续无约束的图像对中计算深度和摄像机运动。该体系结构由多个堆叠的编解码器网络组成,核心部分是一个能够改进自身预测的迭代网络。该网络不仅估计深度和运动,而且还估计表面法线、图像之间的光流和匹配的置信度。该方法的一个重要组成部分是基于空间相对差异的训练损失。与传统的基于运动方法的双框结构相比,结果更准确,鲁棒性更强。与流行的Depth-from-Single-Image网络不同的是,DEMON学习了匹配的概念,因此更好地概括了训练过程中看不到的结构。
1.1 卷积网络与SfM的对比
SfM是计算机视觉研究中的一个长期课题。大多数现有的系统都是经过精心设计,包括几个连续的处理步骤。目前这个步骤的实现有一些固有的限制。例如,在通过密集对应搜索推断场景的结构之前,通常从估计摄像机运动开始。因此,对相机运动的错误估计会导致错误的深度预测。此外,通过关键点检测和描述子匹配计算稀疏对应来估计摄像机运动。这种低层次的处理很容易出现异常值,并且不能在无纹理的区域工作。最后,所有现有的SfM方法在小型摄像机转换的情况下都失败了。这是因为在这些退化的情况下很难整合能够提供合理解决方案的先验。
在本文中,作者训练了一个卷积网络,从无约束的一对图像中联合估计深度和摄像机运动。该方法与典型的SfM有很大的不同,它同时解决了运动和密集深度估计的问题。从长远来看,学习方法有很大的潜力,因为它自然地整合了X方法的所有形状:多视图、轮廓、纹理、阴影、散焦、雾霾。此外,在退化情况下,可以有效地从数据中学习到对象和结构的强先验,并对问题进行规格化;
深度学习方法明显优于传统方法。
1.2 传统卷积神经网络与本网络对比
最近,卷积网络在单个图像的深度预测方面表现出色通过学习对象及其形状的先验知识,这些网络在受限评价中,如室内或驾驶场景,达到了非常好的性能。
然而,单一图像方法在推广到以前未见过的图像类型方面存在更多问题。这是因为他们没有利用立体视觉。下图显示了一个示例,其中单个图像的深度失败,因为网络以前没有看到类似的结构。作者的网络,它学会了利用运动视差,没有这个限制,很好地概括了非常新的场景。

为了利用运动视差,网络必须将两个输入图像对应起来。作者发现一个简单的编码器-解码器网络不能使用立体图像:当训练它从两个图像计算深度时,它最终只使用其中一个。单幅图像的深度是满足训练目标的捷径,无需将两幅图像进行对应,并从对应中得到相机的运动和深度。在走捷径的同时网络忽略了三维空间对预测结果的影响。
本文解决了传统神经网络的问题,采用了一种光流估计与相机运动和深度估计交替进行的架构;为了求解光流,网络必须使用两个图像。
本文还提出了一个技术贡献是用特殊的梯度损失来处理由运动引起的结构尺度模糊。
2. Methods
整体网络架构如图2所示。DeMoN是一个编码-解码网络链,解决不同的任务。该体系结构由三个主要部分组成:bootstrap网络、迭代网络和细化网络。前两个组件是一对编码器解码器网络,其中第一个计算光流,第二个计算深度和摄像机运动;参见下图。迭代网递归地应用于连续地改进前一次迭代的估计。最后一个组件是一个单独的编码器-解码器网络,生成最终的更新采样和细化的深度映射。
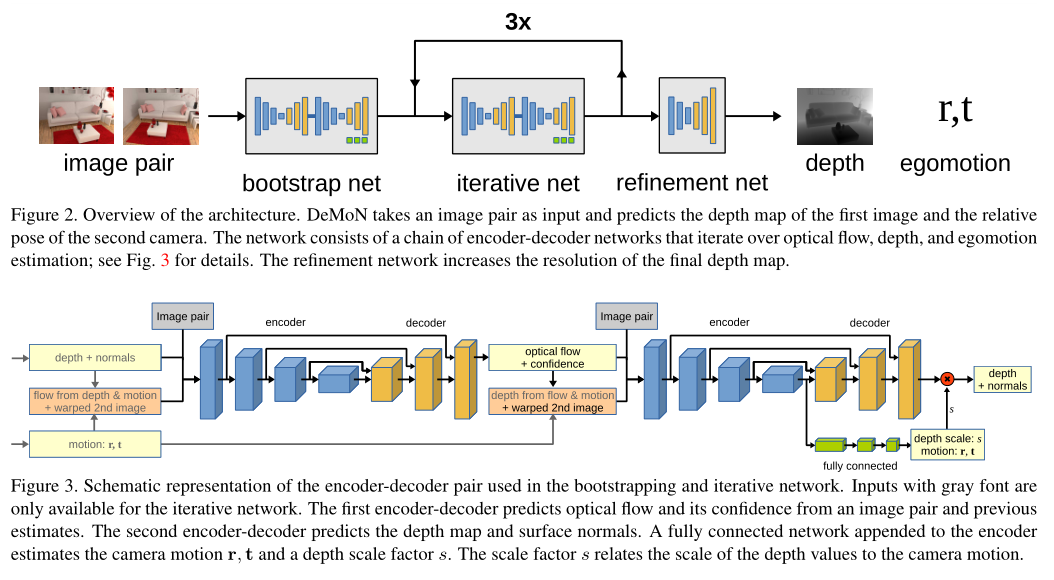
2.1 训练过程
2.1.1 损失函数
该网络估计的输出性质非常不同:高维(每像素)深度地图和低维摄像机运动向量。损失必须平衡这两个目标,并在不过度适应特定场景的情况下促进这两个任务的协同作用。
- Point-wise losses.
- 作者将点方向的损失应用到作者的输出上:反深度值ξ,表面法线n,光流w,光流置信值c。对于深度,作者直接在反深度值上使用L1损失:
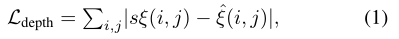
- 对于法线和光流的损失函数:
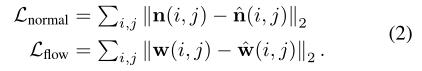
- 作者训练网络通过预测每个光流分量的置信图来评估其自身流量预测的质量。x分量置信度:
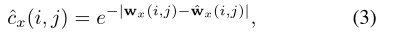 相应的损失函数是:
相应的损失函数是: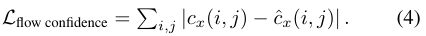
- 作者将点方向的损失应用到作者的输出上:反深度值ξ,表面法线n,光流w,光流置信值c。对于深度,作者直接在反深度值上使用L1损失:
- Motion losses.
- 作者使用了摄像机运动的最小参数化,每个参数为旋转r和平移t。运动矢量的损失:
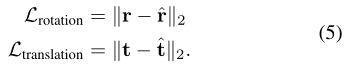
- 作者使用了摄像机运动的最小参数化,每个参数为旋转r和平移t。运动矢量的损失:
- Scale invariant gradient loss.
- 作者定义离散不变梯度g为
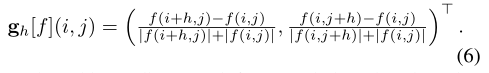
- 基于这个梯度,作者定义了一个尺度不变的损失,它惩罚了相邻像素之间的相关性:
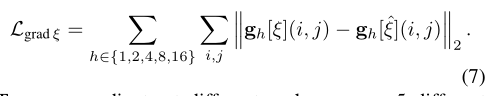
- 作者对光流的每个分量应用相同的尺度不变梯度损失。这增强了估计流场的平滑度和运动不连续性的锐度
- 作者定义离散不变梯度g为
- Weighting
- 作者分别权衡损失以平衡其重要性。权重因素是根据经验确定的,并在补充资料中列出。
2.2 训练进度
网络训练是基于Caffe框架的。作者用Adam从头开始训练模型,动量为0.9,重量衰减为0.0004。整个培训过程包括三个阶段。
首先,作者在引导网和迭代网中顺序训练四个编解码器组件,每个迭代250k次,批大小为32。在训练编解码器时,作者保持前面所有组件的权重不变。对于指定光流的编解码器,在10k次迭代后应用尺度不变损耗。
其次,作者只训练迭代网络的编解码器对。在此阶段,作者将前三次训练迭代的输出附加到小批量中。在此阶段,引导网络使用大小为8的批次。将前三次网络迭代的输出添加到批次中,从而产生迭代网络的总批次大小为32。作者运行160万次培训迭代。
最后,在其他权值固定的情况下,对精化网络进行600k次迭代训练。
3. Results
3.1 数据集
SUN3D:这个数据集提供了一组不同的室内图像以及深度和相机姿势。此数据集上的深度和相机姿势并不完美。因此,作者从数据集中采样图像对,并自动丢弃具有较高照相一致性误差的图像对。作者拆分数据集,以便相同的场景不会同时出现在训练和测试集中。
MVS:包括几个室外数据集。作者使用来自的Citywall和Achteckturm数据集和Breisach数据集进行训练,并使用COLMAP提供的数据集进行测试。重建场景的深度图通常是稀疏的,并且可能包含重建误差。
Scenes11:是一个合成数据集,包含随机几何形状的虚拟场景图像,提供完美的深度和运动场景真实,但缺乏真实感。
因此,作者引入了基于blendswap.com上150个场景的Blendswap数据集。该数据集提供了大量的场景,从类似卡通的场景到逼真的场景。该数据集主要包含室内场景。作者仅将此数据集用于训练。
NYUv2:提供多种室内场景的深度地图,但缺乏相机姿态信息。作者没有在NYU上进行训练,而是使用了与Eigen等人相同的测试分割。与Eigen等人不同,作者还需要第二个输入图像,它不应该与前一个相同。因此,作者根据差分图像上的一个阈值,自动选择与第一幅图像足够不同的下一幅图像。
在所有没有表面法线的情况下,我们从深度图中生成它们。我们专门为SUN3D中使用的相机特性训练了DeMoN,并通过裁剪和缩放来适应所有其他数据集以匹配这些参数。
3.2 误差指标
单图像方法的目的是在实际物理尺度上预测深度,而双图像方法通常产生的尺度相对于相机平移向量的范数。比较这两组方法的结果需要一个尺度不变误差度量。我们采用的尺度不变误差,定义为:
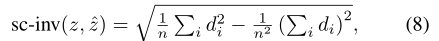
其中: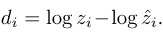
为了与运动方法中的经典结构进行比较,我们采用了以下措施:
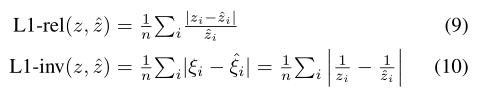
3.3 与经典结构的运动对比
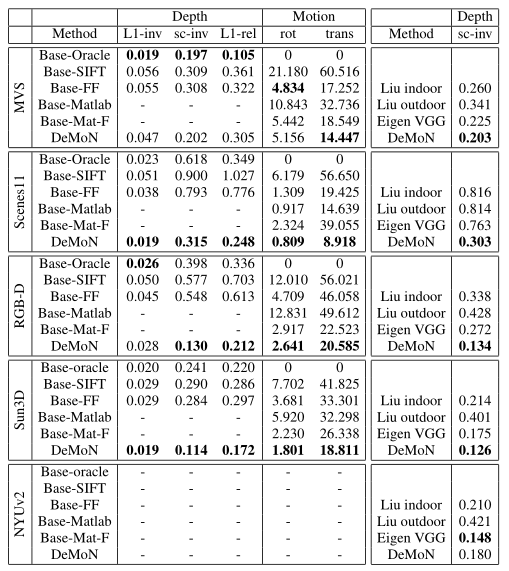
两帧深度和运动估计方法的比较。对所有措施来说,越低越好。为了与基线方法进行公平比较,我们仅在两幅图像中可见的像素处评估深度。因为Base-Matlab的深度只能作为稀疏点云提供,因此不能与这里进行比较。我们没有报告NYUv2的错误,因为运动地面真相(因此深度刻度)是不可用的。右:与单帧深度估计的比较。由于尺度估计不具有可比性,我们仅报告尺度不变误差度量。

通过增加DeMoN的两个输入图像之间的基线来提高质量性能。深度图由左上角的参考图像和下面的第二个图像生成。第一个输出包含两个相同的图像输入,这是传统结构运动的退化情况。
3.4 与单个图像的深度进行比较

在各种数据集上进行定性深度预测比较,DeMoN的预测非常清晰和详尽,因为一些原因,缺少有关NYUv2的Base-Oracle预测。
3.4 对新数据的归纳
当面对与训练数据截然不同的场景时,在训练过程中学习的特定场景先验可能是无用的,甚至是有害的。相反,一对图像之间的几何关系是独立于场景内容的,应该概括为未知的场景。为了分析DeMoN的泛化特性,我们汇编了一个小数据集,其中包含一些不常见或复杂的场景,例如抽象雕塑、人物和物体的特写、旋转90度的图像。

将DeMoN的泛化能力可视化到以前看不到的配置。在这种情况下,单帧方法有严重的问题,因为在最后一个示例的深度估计的点云可视化中最清晰可见。
4. Discussion
DeMoN是第一个学习从两个不受约束的图像中估计深度和摄像机运动的深度网络。与从单一图像估算深度的网络不同,DeMoN可以利用运动视差,这是一种强大的线索,可用于新类型的场景,并允许估算自我运动。该网络在两帧上优于传统的运动技术结构,因为与那些相比,它是端到端的训练,并学习从X线索整合其他形状。当涉及到处理相机与不同的内在参数,它还没有达到传统方法的灵活性。下一个挑战是解除这个限制,并将这项工作扩展到两个以上的图像。与传统技术一样,这有望显著提高鲁棒性和准确性。
5. References
C. Bailer, B. Taetz, and D. Stricker. Flow Fields: Dense Correspondence Fields for Highly Accurate Large Displacement Optical Flow Estimation. In IEEE International Conference on Computer Vision (ICCV), Dec. 2015.
P . Agrawal, J. Carreira, and J. Malik. Learning to see by moving. In IEEE International Conference on Computer Vision (ICCV), Dec. 2015.
D. Eigen and R. Fergus. Predicting Depth, Surface Normals and Semantic Labels With a Common Multi-Scale Convo- lutional Architecture. In IEEE International Conference on Computer Vision (ICCV), Dec. 2015
F. Liu, C. Shen, G. Lin, and I. Reid. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. In IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015.
